 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Graph Condensation via Classification Complexity Mitigation
Oct 30, 2025Graph condensation (GC) has gained significant attention for its ability to synthesize smaller yet informative graphs. However, existing studies often overlook the robustness of GC in scenarios where the original graph is corrupted. In such cases, we observe that the performance of GC deteriorates significantly, while existing robust graph learning technologies offer only limited effectiveness. Through both empirical investigation and theoretical analysis, we reveal that GC is inherently an intrinsic-dimension-reducing process, synthesizing a condensed graph with lower classification complexity. Although this property is critical for effective GC performance, it remains highly vulnerable to adversarial perturbations. To tackle this vulnerability and improve GC robustness, we adopt the geometry perspective of graph data manifold and propose a novel Manifold-constrained Robust Graph Condensation framework named MRGC. Specifically, we introduce three graph data manifold learning modules that guide the condensed graph to lie within a smooth, low-dimensional manifold with minimal class ambiguity, thereby preserving the classification complexity reduction capability of GC and ensuring robust performance under universal adversarial attacks. Extensive experiments demonstrate the robustness of \ModelName\ across diverse attack scenarios.
Bi-Directional Multi-Scale Graph Dataset Condensation via Information Bottleneck
Dec 23, 2024Dataset condensation has significantly improved model training efficiency, but its application on devices with different computing power brings new requirements for different data sizes. Thus, condensing multiple scale graphs simultaneously is the core of achieving efficient training in different on-device scenarios. Existing efficient works for multi-scale graph dataset condensation mainly perform efficient approximate computation in scale order (large-to-small or small-to-large scales). However, for non-Euclidean structures of sparse graph data, these two commonly used paradigms for multi-scale graph dataset condensation have serious scaling down degradation and scaling up collapse problems of a graph. The main bottleneck of the above paradigms is whether the effective information of the original graph is fully preserved when consenting to the primary sub-scale (the first of multiple scales), which determines the condensation effect and consistency of all scales. In this paper, we proposed a novel GNN-centric Bi-directional Multi-Scale Graph Dataset Condensation (BiMSGC) framework, to explore unifying paradigms by operating on both large-to-small and small-to-large for multi-scale graph condensation. Based on the mutual information theory, we estimate an optimal ``meso-scale'' to obtain the minimum necessary dense graph preserving the maximum utility information of the original graph, and then we achieve stable and consistent ``bi-directional'' condensation learning by optimizing graph eigenbasis matching with information bottleneck on other scales. Encouraging empirical results on several datasets demonstrates the significant superiority of the proposed framework in graph condensation at different scales.
Pre-Training and Prompting for Few-Shot Node Classification on Text-Attributed Graphs
Jul 22, 2024
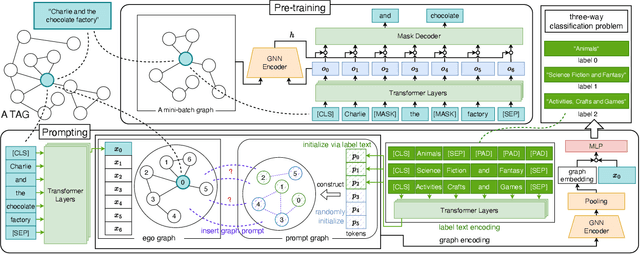
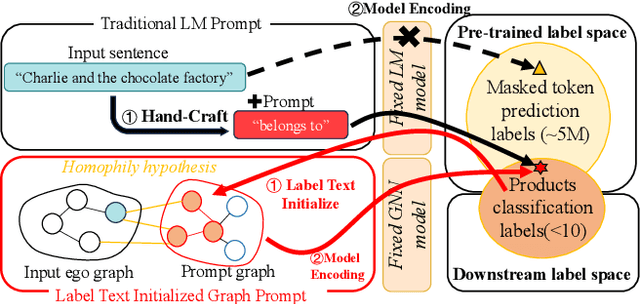
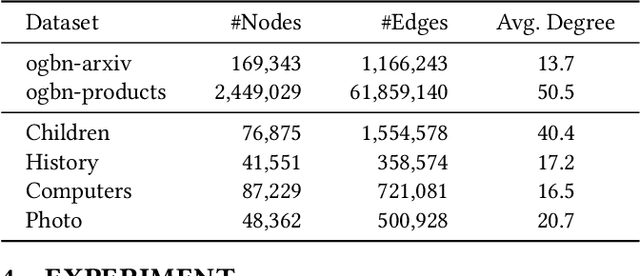
The text-attributed graph (TAG) is one kind of important real-world graph-structured data with each node associated with raw texts. For TAGs, traditional few-shot node classification methods directly conduct training on the pre-processed node features and do not consider the raw texts. The performance is highly dependent on the choice of the feature pre-processing method. In this paper, we propose P2TAG, a framework designed for few-shot node classification on TAGs with graph pre-training and prompting. P2TAG first pre-trains the language model (LM) and graph neural network (GNN) on TAGs with self-supervised loss. To fully utilize the ability of language models, we adapt the masked language modeling objective for our framework. The pre-trained model is then used for the few-shot node classification with a mixed prompt method, which simultaneously considers both text and graph information. We conduct experiments on six real-world TAGs, including paper citation networks and product co-purchasing networks. Experimental results demonstrate that our proposed framework outperforms existing graph few-shot learning methods on these datasets with +18.98% ~ +35.98% improvements.
GC-Bench: An Open and Unified Benchmark for Graph Condensation
Jun 30, 2024Graph condensation (GC) has recently garnered considerable attention due to its ability to reduce large-scale graph datasets while preserving their essential properties. The core concept of GC is to create a smaller, more manageable graph that retains the characteristics of the original graph. Despite the proliferation of graph condensation methods developed in recent years, there is no comprehensive evaluation and in-depth analysis, which creates a great obstacle to understanding the progress in this field. To fill this gap, we develop a comprehensive Graph Condensation Benchmark (GC-Bench) to analyze the performance of graph condensation in different scenarios systematically. Specifically, GC-Bench systematically investigates the characteristics of graph condensation in terms of the following dimensions: effectiveness, transferability, and complexity. We comprehensively evaluate 12 state-of-the-art graph condensation algorithms in node-level and graph-level tasks and analyze their performance in 12 diverse graph datasets. Further, we have developed an easy-to-use library for training and evaluating different GC methods to facilitate reproducible research. The GC-Bench library is available at https://github.com/RingBDStack/GC-Bench.
Two Trades is not Baffled: Condensing Graph via Crafting Rational Gradient Matching
Feb 08, 2024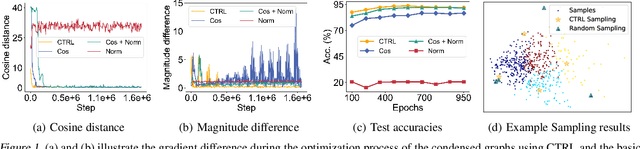
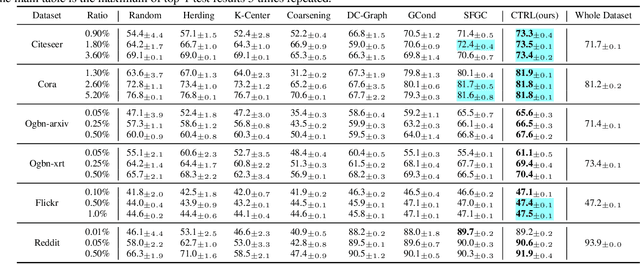
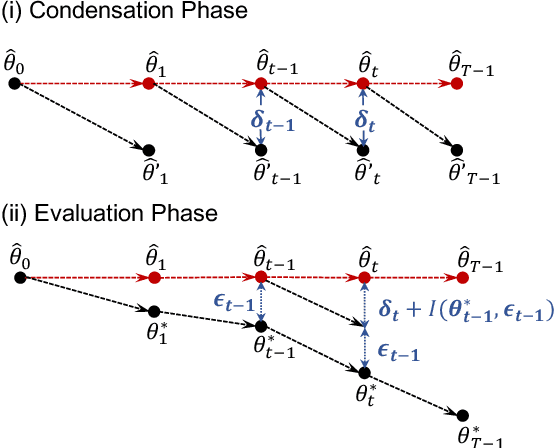
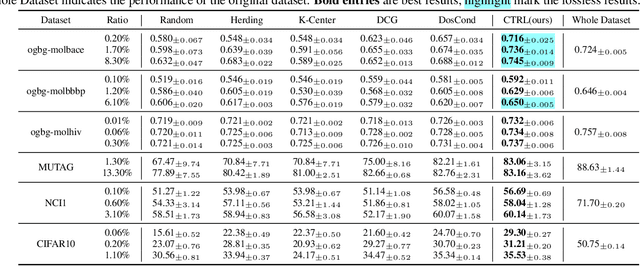
Training on large-scale graphs has achieved remarkable results in graph representation learning, but its cost and storage have raised growing concerns. As one of the most promising directions, graph condensation methods address these issues by employing gradient matching, aiming to condense the full graph into a more concise yet information-rich synthetic set. Though encouraging, these strategies primarily emphasize matching directions of the gradients, which leads to deviations in the training trajectories. Such deviations are further magnified by the differences between the condensation and evaluation phases, culminating in accumulated errors, which detrimentally affect the performance of the condensed graphs. In light of this, we propose a novel graph condensation method named \textbf{C}raf\textbf{T}ing \textbf{R}ationa\textbf{L} trajectory (\textbf{CTRL}), which offers an optimized starting point closer to the original dataset's feature distribution and a more refined strategy for gradient matching. Theoretically, CTRL can effectively neutralize the impact of accumulated errors on the performance of condensed graphs. We provide extensive experiments on various graph datasets and downstream tasks to support the effectiveness of CTRL. Code is released at https://github.com/NUS-HPC-AI-Lab/CTRL.
Does Graph Distillation See Like Vision Dataset Counterpart?
Oct 13, 2023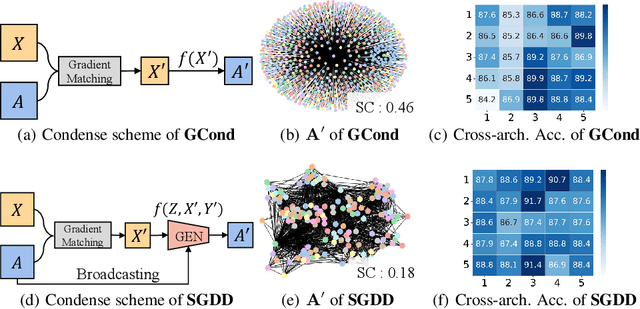

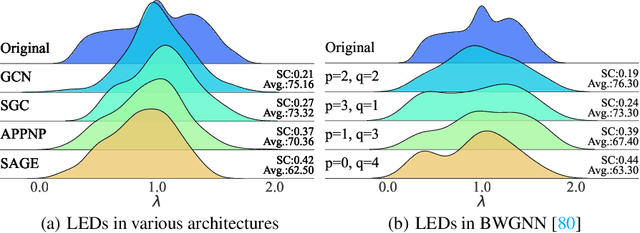

Training on large-scale graphs has achieved remarkable results in graph representation learning, but its cost and storage have attracted increasing concerns. Existing graph condensation methods primarily focus on optimizing the feature matrices of condensed graphs while overlooking the impact of the structure information from the original graphs. To investigate the impact of the structure information, we conduct analysis from the spectral domain and empirically identify substantial Laplacian Energy Distribution (LED) shifts in previous works. Such shifts lead to poor performance in cross-architecture generalization and specific tasks, including anomaly detection and link prediction. In this paper, we propose a novel Structure-broadcasting Graph Dataset Distillation (SGDD) scheme for broadcasting the original structure information to the generation of the synthetic one, which explicitly prevents overlooking the original structure information. Theoretically, the synthetic graphs by SGDD are expected to have smaller LED shifts than previous works, leading to superior performance in both cross-architecture settings and specific tasks. We validate the proposed SGDD across 9 datasets and achieve state-of-the-art results on all of them: for example, on the YelpChi dataset, our approach maintains 98.6% test accuracy of training on the original graph dataset with 1,000 times saving on the scale of the graph. Moreover, we empirically evaluate there exist 17.6% ~ 31.4% reductions in LED shift crossing 9 datasets. Extensive experiments and analysis verify the effectiveness and necessity of the proposed designs. The code is available in the GitHub repository: https://github.com/RingBDStack/SGDD.
Self-organization Preserved Graph Structure Learning with Principle of Relevant Information
Dec 30, 2022
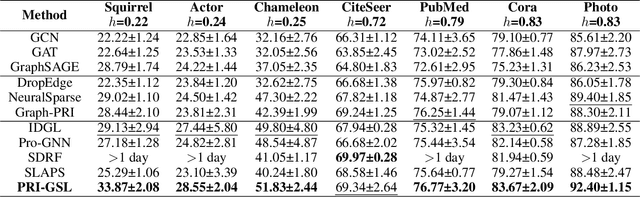
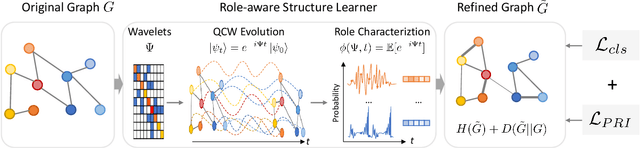
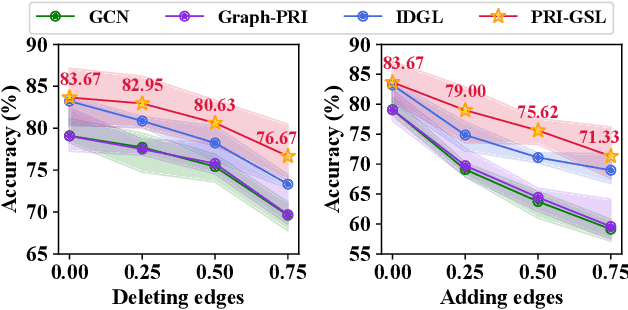
Most Graph Neural Networks follow the message-passing paradigm, assuming the observed structure depicts the ground-truth node relationships. However, this fundamental assumption cannot always be satisfied, as real-world graphs are always incomplete, noisy, or redundant. How to reveal the inherent graph structure in a unified way remains under-explored. We proposed PRI-GSL, a Graph Structure Learning framework guided by the Principle of Relevant Information, providing a simple and unified framework for identifying the self-organization and revealing the hidden structure. PRI-GSL learns a structure that contains the most relevant yet least redundant information quantified by von Neumann entropy and Quantum Jensen-Shannon divergence. PRI-GSL incorporates the evolution of quantum continuous walk with graph wavelets to encode node structural roles, showing in which way the nodes interplay and self-organize with the graph structure. Extensive experiments demonstrate the superior effectiveness and robustness of PRI-GSL.