 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards LLM-Empowered Knowledge Tracing via LLM-Student Hierarchical Behavior Alignment in Hyperbolic Space
Feb 26, 2026Knowledge Tracing (KT) diagnoses students' concept mastery through continuous learning state monitoring in education.Existing methods primarily focus on studying behavioral sequences based on ID or textual information.While existing methods rely on ID-based sequences or shallow textual features, they often fail to capture (1) the hierarchical evolution of cognitive states and (2) individualized problem difficulty perception due to limited semantic modeling. Therefore, this paper proposes a Large Language Model Hyperbolic Aligned Knowledge Tracing(L-HAKT). First, the teacher agent deeply parses question semantics and explicitly constructs hierarchical dependencies of knowledge points; the student agent simulates learning behaviors to generate synthetic data. Then, contrastive learning is performed between synthetic and real data in hyperbolic space to reduce distribution differences in key features such as question difficulty and forgetting patterns. Finally, by optimizing hyperbolic curvature, we explicitly model the tree-like hierarchical structure of knowledge points, precisely characterizing differences in learning curve morphology for knowledge points at different levels. Extensive experiments on four real-world educational datasets validate the effectiveness of our Large Language Model Hyperbolic Aligned Knowledge Tracing (L-HAKT) framework.
Implicit Federated In-context Learning For Task-Specific LLM Fine-Tuning
Nov 10, 2025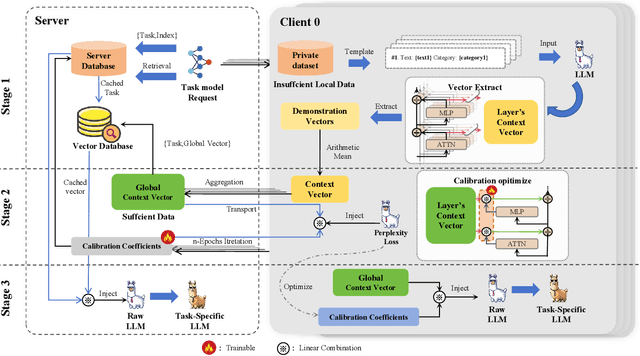

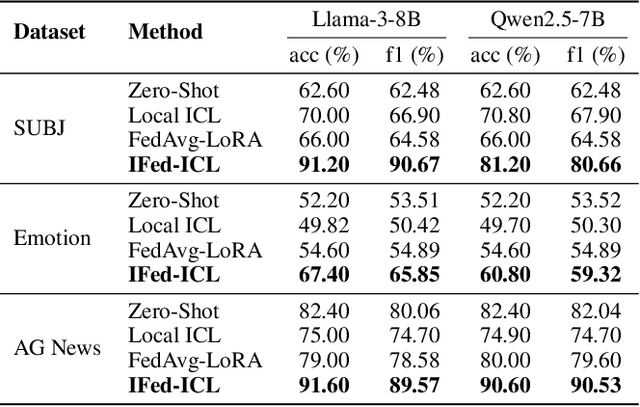
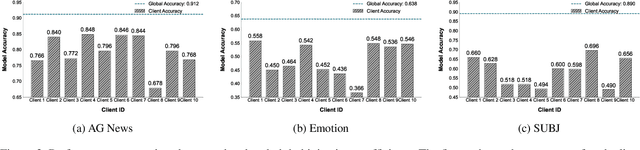
As large language models continue to develop and expand, the extensive public data they rely on faces the risk of depletion. Consequently, leveraging private data within organizations to enhance the performance of large models has emerged as a key challenge. The federated learning paradigm, combined with model fine-tuning techniques, effectively reduces the number of trainable parameters. However,the necessity to process high-dimensional feature spaces results in substantial overall computational overhead. To address this issue, we propose the Implicit Federated In-Context Learning (IFed-ICL) framework. IFed-ICL draws inspiration from federated learning to establish a novel distributed collaborative paradigm, by converting client local context examples into implicit vector representations, it enables distributed collaborative computation during the inference phase and injects model residual streams to enhance model performance. Experiments demonstrate that our proposed method achieves outstanding performance across multiple text classification tasks. Compared to traditional methods, IFed-ICL avoids the extensive parameter updates required by conventional fine-tuning methods while reducing data transmission and local computation at the client level in federated learning. This enables efficient distributed context learning using local private-domain data, significantly improving model performance on specific tasks.
Toward a Unified Geometry Understanding: Riemannian Diffusion Framework for Graph Generation and Prediction
Oct 06, 2025Graph diffusion models have made significant progress in learning structured graph data and have demonstrated strong potential for predictive tasks. Existing approaches typically embed node, edge, and graph-level features into a unified latent space, modeling prediction tasks including classification and regression as a form of conditional generation. However, due to the non-Euclidean nature of graph data, features of different curvatures are entangled in the same latent space without releasing their geometric potential. To address this issue, we aim to construt an ideal Riemannian diffusion model to capture distinct manifold signatures of complex graph data and learn their distribution. This goal faces two challenges: numerical instability caused by exponential mapping during the encoding proces and manifold deviation during diffusion generation. To address these challenges, we propose GeoMancer: a novel Riemannian graph diffusion framework for both generation and prediction tasks. To mitigate numerical instability, we replace exponential mapping with an isometric-invariant Riemannian gyrokernel approach and decouple multi-level features onto their respective task-specific manifolds to learn optimal representations. To address manifold deviation, we introduce a manifold-constrained diffusion method and a self-guided strategy for unconditional generation, ensuring that the generated data remains aligned with the manifold signature. Extensive experiments validate the effectiveness of our approach, demonstrating superior performance across a variety of tasks.
Towards Universal Modal Tracking with Online Dense Temporal Token Learning
Jul 27, 2025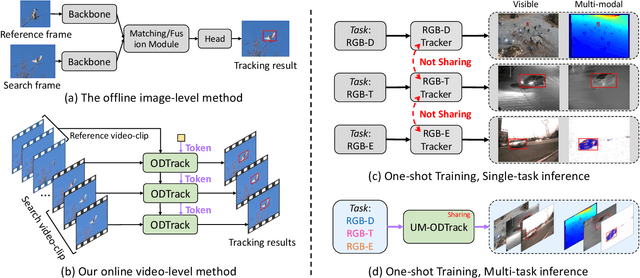


We propose a universal video-level modality-awareness tracking model with online dense temporal token learning (called {\modaltracker}). It is designed to support various tracking tasks, including RGB, RGB+Thermal, RGB+Depth, and RGB+Event, utilizing the same model architecture and parameters. Specifically, our model is designed with three core goals: \textbf{Video-level Sampling}. We expand the model's inputs to a video sequence level, aiming to see a richer video context from an near-global perspective. \textbf{Video-level Association}. Furthermore, we introduce two simple yet effective online dense temporal token association mechanisms to propagate the appearance and motion trajectory information of target via a video stream manner. \textbf{Modality Scalable}. We propose two novel gated perceivers that adaptively learn cross-modal representations via a gated attention mechanism, and subsequently compress them into the same set of model parameters via a one-shot training manner for multi-task inference. This new solution brings the following benefits: (i) The purified token sequences can serve as temporal prompts for the inference in the next video frames, whereby previous information is leveraged to guide future inference. (ii) Unlike multi-modal trackers that require independent training, our one-shot training scheme not only alleviates the training burden, but also improves model representation. Extensive experiments on visible and multi-modal benchmarks show that our {\modaltracker} achieves a new \textit{SOTA} performance. The code will be available at https://github.com/GXNU-ZhongLab/ODTrack.
Mitigating Message Imbalance in Fraud Detection with Dual-View Graph Representation Learning
Jul 09, 2025Graph representation learning has become a mainstream method for fraud detection due to its strong expressive power, which focuses on enhancing node representations through improved neighborhood knowledge capture. However, the focus on local interactions leads to imbalanced transmission of global topological information and increased risk of node-specific information being overwhelmed during aggregation due to the imbalance between fraud and benign nodes. In this paper, we first summarize the impact of topology and class imbalance on downstream tasks in GNN-based fraud detection, as the problem of imbalanced supervisory messages is caused by fraudsters' topological behavior obfuscation and identity feature concealment. Based on statistical validation, we propose a novel dual-view graph representation learning method to mitigate Message imbalance in Fraud Detection(MimbFD). Specifically, we design a topological message reachability module for high-quality node representation learning to penetrate fraudsters' camouflage and alleviate insufficient propagation. Then, we introduce a local confounding debiasing module to adjust node representations, enhancing the stable association between node representations and labels to balance the influence of different classes. Finally, we conducted experiments on three public fraud datasets, and the results demonstrate that MimbFD exhibits outstanding performance in fraud detection.
An Out-Of-Distribution Membership Inference Attack Approach for Cross-Domain Graph Attacks
May 26, 2025Graph Neural Network-based methods face privacy leakage risks due to the introduction of topological structures about the targets, which allows attackers to bypass the target's prior knowledge of the sensitive attributes and realize membership inference attacks (MIA) by observing and analyzing the topology distribution. As privacy concerns grow, the assumption of MIA, which presumes that attackers can obtain an auxiliary dataset with the same distribution, is increasingly deviating from reality. In this paper, we categorize the distribution diversity issue in real-world MIA scenarios as an Out-Of-Distribution (OOD) problem, and propose a novel Graph OOD Membership Inference Attack (GOOD-MIA) to achieve cross-domain graph attacks. Specifically, we construct shadow subgraphs with distributions from different domains to model the diversity of real-world data. We then explore the stable node representations that remain unchanged under external influences and consider eliminating redundant information from confounding environments and extracting task-relevant key information to more clearly distinguish between the characteristics of training data and unseen data. This OOD-based design makes cross-domain graph attacks possible. Finally, we perform risk extrapolation to optimize the attack's domain adaptability during attack inference to generalize the attack to other domains. Experimental results demonstrate that GOOD-MIA achieves superior attack performance in datasets designed for multiple domains.
Discrete Curvature Graph Information Bottleneck
Dec 28, 2024Graph neural networks(GNNs) have been demonstrated to depend on whether the node effective information is sufficiently passing. Discrete curvature (Ricci curvature) is used to study graph connectivity and information propagation efficiency with a geometric perspective, and has been raised in recent years to explore the efficient message-passing structure of GNNs. However, most empirical studies are based on directly observed graph structures or heuristic topological assumptions and lack in-depth exploration of underlying optimal information transport structures for downstream tasks. We suggest that graph curvature optimization is more in-depth and essential than directly rewiring or learning for graph structure with richer message-passing characterization and better information transport interpretability. From both graph geometry and information theory perspectives, we propose the novel Discrete Curvature Graph Information Bottleneck (CurvGIB) framework to optimize the information transport structure and learn better node representations simultaneously. CurvGIB advances the Variational Information Bottleneck (VIB) principle for Ricci curvature optimization to learn the optimal information transport pattern for specific downstream tasks. The learned Ricci curvature is used to refine the optimal transport structure of the graph, and the node representation is fully and efficiently learned. Moreover, for the computational complexity of Ricci curvature differentiation, we combine Ricci flow and VIB to deduce a curvature optimization approximation to form a tractable IB objective function. Extensive experiments on various datasets demonstrate the superior effectiveness and interpretability of CurvGIB.
Bi-Directional Multi-Scale Graph Dataset Condensation via Information Bottleneck
Dec 23, 2024Dataset condensation has significantly improved model training efficiency, but its application on devices with different computing power brings new requirements for different data sizes. Thus, condensing multiple scale graphs simultaneously is the core of achieving efficient training in different on-device scenarios. Existing efficient works for multi-scale graph dataset condensation mainly perform efficient approximate computation in scale order (large-to-small or small-to-large scales). However, for non-Euclidean structures of sparse graph data, these two commonly used paradigms for multi-scale graph dataset condensation have serious scaling down degradation and scaling up collapse problems of a graph. The main bottleneck of the above paradigms is whether the effective information of the original graph is fully preserved when consenting to the primary sub-scale (the first of multiple scales), which determines the condensation effect and consistency of all scales. In this paper, we proposed a novel GNN-centric Bi-directional Multi-Scale Graph Dataset Condensation (BiMSGC) framework, to explore unifying paradigms by operating on both large-to-small and small-to-large for multi-scale graph condensation. Based on the mutual information theory, we estimate an optimal ``meso-scale'' to obtain the minimum necessary dense graph preserving the maximum utility information of the original graph, and then we achieve stable and consistent ``bi-directional'' condensation learning by optimizing graph eigenbasis matching with information bottleneck on other scales. Encouraging empirical results on several datasets demonstrates the significant superiority of the proposed framework in graph condensation at different scales.
FedRGL: Robust Federated Graph Learning for Label Noise
Nov 28, 2024Federated Graph Learning (FGL) is a distributed machine learning paradigm based on graph neural networks, enabling secure and collaborative modeling of local graph data among clients. However, label noise can degrade the global model's generalization performance. Existing federated label noise learning methods, primarily focused on computer vision, often yield suboptimal results when applied to FGL. To address this, we propose a robust federated graph learning method with label noise, termed FedRGL. FedRGL introduces dual-perspective consistency noise node filtering, leveraging both the global model and subgraph structure under class-aware dynamic thresholds. To enhance client-side training, we incorporate graph contrastive learning, which improves encoder robustness and assigns high-confidence pseudo-labels to noisy nodes. Additionally, we measure model quality via predictive entropy of unlabeled nodes, enabling adaptive robust aggregation of the global model. Comparative experiments on multiple real-world graph datasets show that FedRGL outperforms 12 baseline methods across various noise rates, types, and numbers of clients.
Personalized federated learning based on feature fusion
Jun 24, 2024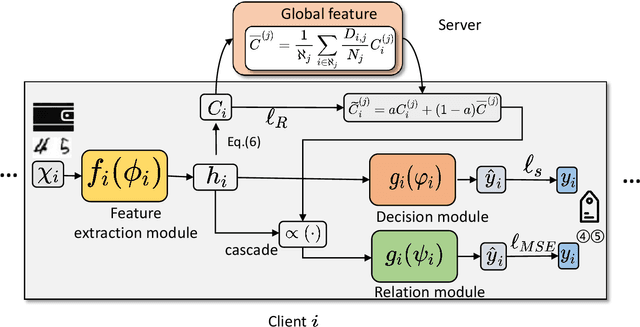
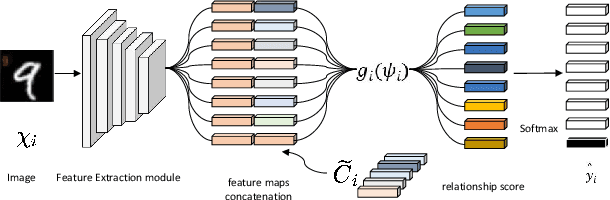
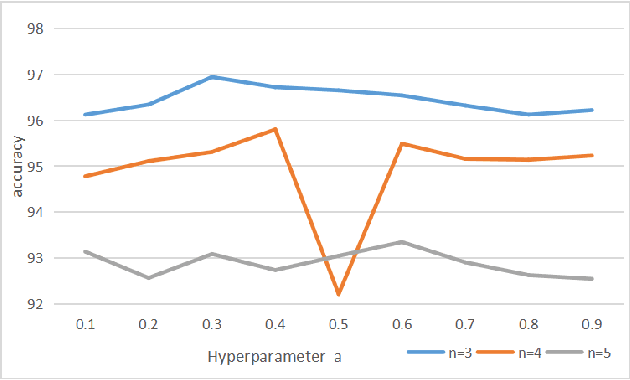
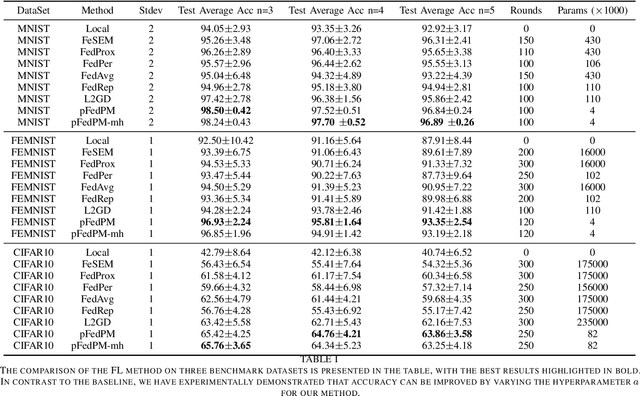
Federated learning enables distributed clients to collaborate on training while storing their data locally to protect client privacy. However, due to the heterogeneity of data, models, and devices, the final global model may need to perform better for tasks on each client. Communication bottlenecks, data heterogeneity, and model heterogeneity have been common challenges in federated learning. In this work, we considered a label distribution skew problem, a type of data heterogeneity easily overlooked. In the context of classification, we propose a personalized federated learning approach called pFedPM. In our process, we replace traditional gradient uploading with feature uploading, which helps reduce communication costs and allows for heterogeneous client models. These feature representations play a role in preserving privacy to some extent. We use a hyperparameter $a$ to mix local and global features, which enables us to control the degree of personalization. We also introduced a relation network as an additional decision layer, which provides a non-linear learnable classifier to predict labels. Experimental results show that, with an appropriate setting of $a$, our scheme outperforms several recent FL methods on MNIST, FEMNIST, and CRIFAR10 datasets and achieves fewer communications.