 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Path to Multimodal Generalist: General-Level and General-Bench
May 07, 2025The Multimodal Large Language Model (MLLM) is currently experiencing rapid growth, driven by the advanced capabilities of LLMs. Unlike earlier specialists, existing MLLMs are evolving towards a Multimodal Generalist paradigm. Initially limited to understanding multiple modalities, these models have advanced to not only comprehend but also generate across modalities. Their capabilities have expanded from coarse-grained to fine-grained multimodal understanding and from supporting limited modalities to arbitrary ones. While many benchmarks exist to assess MLLMs, a critical question arises: Can we simply assume that higher performance across tasks indicates a stronger MLLM capability, bringing us closer to human-level AI? We argue that the answer is not as straightforward as it seems. This project introduces General-Level, an evaluation framework that defines 5-scale levels of MLLM performance and generality, offering a methodology to compare MLLMs and gauge the progress of existing systems towards more robust multimodal generalists and, ultimately, towards AGI. At the core of the framework is the concept of Synergy, which measures whether models maintain consistent capabilities across comprehension and generation, and across multiple modalities. To support this evaluation, we present General-Bench, which encompasses a broader spectrum of skills, modalities, formats, and capabilities, including over 700 tasks and 325,800 instances. The evaluation results that involve over 100 existing state-of-the-art MLLMs uncover the capability rankings of generalists, highlighting the challenges in reaching genuine AI. We expect this project to pave the way for future research on next-generation multimodal foundation models, providing a robust infrastructure to accelerate the realization of AGI. Project page: https://generalist.top/
SwimVG: Step-wise Multimodal Fusion and Adaption for Visual Grounding
Feb 24, 2025



Visual grounding aims to ground an image region through natural language, which heavily relies on cross-modal alignment. Most existing methods transfer visual/linguistic knowledge separately by fully fine-tuning uni-modal pre-trained models, followed by a simple stack of visual-language transformers for multimodal fusion. However, these approaches not only limit adequate interaction between visual and linguistic contexts, but also incur significant computational costs. Therefore, to address these issues, we explore a step-wise multimodal fusion and adaption framework, namely SwimVG. Specifically, SwimVG proposes step-wise multimodal prompts (Swip) and cross-modal interactive adapters (CIA) for visual grounding, replacing the cumbersome transformer stacks for multimodal fusion. Swip can improve {the} alignment between the vision and language representations step by step, in a token-level fusion manner. In addition, weight-level CIA further promotes multimodal fusion by cross-modal interaction. Swip and CIA are both parameter-efficient paradigms, and they fuse the cross-modal features from shallow to deep layers gradually. Experimental results on four widely-used benchmarks demonstrate that SwimVG achieves remarkable abilities and considerable benefits in terms of efficiency. Our code is available at https://github.com/liuting20/SwimVG.
Adaptive Perception for Unified Visual Multi-modal Object Tracking
Feb 10, 2025Recently, many multi-modal trackers prioritize RGB as the dominant modality, treating other modalities as auxiliary, and fine-tuning separately various multi-modal tasks. This imbalance in modality dependence limits the ability of methods to dynamically utilize complementary information from each modality in complex scenarios, making it challenging to fully perceive the advantages of multi-modal. As a result, a unified parameter model often underperforms in various multi-modal tracking tasks. To address this issue, we propose APTrack, a novel unified tracker designed for multi-modal adaptive perception. Unlike previous methods, APTrack explores a unified representation through an equal modeling strategy. This strategy allows the model to dynamically adapt to various modalities and tasks without requiring additional fine-tuning between different tasks. Moreover, our tracker integrates an adaptive modality interaction (AMI) module that efficiently bridges cross-modality interactions by generating learnable tokens. Experiments conducted on five diverse multi-modal datasets (RGBT234, LasHeR, VisEvent, DepthTrack, and VOT-RGBD2022) demonstrate that APTrack not only surpasses existing state-of-the-art unified multi-modal trackers but also outperforms trackers designed for specific multi-modal tasks.
Multi-Stage Vision Token Dropping: Towards Efficient Multimodal Large Language Model
Nov 16, 2024



The vision tokens in multimodal large language models usually exhibit significant spatial and temporal redundancy and take up most of the input tokens, which harms their inference efficiency. To solve this problem, some recent works were introduced to drop the unimportant tokens during inference where the importance of each token is decided only by the information in either the vision encoding stage or the prefilling stage. In this paper, we propose Multi-stage Token Dropping (MustDrop) to measure the importance of each token from the whole lifecycle, including the vision encoding stage, prefilling stage, and decoding stage. Concretely, in the visual encoding stage, MustDrop merges spatially adjacent tokens with high similarity, and establishes a key token set to retain the most vision-critical tokens, preventing them from being discarded in later stages. In the prefilling stage, MustDrop further compresses vision tokens by the guidance of text semantics, with a dual-attention filtering strategy. In the decoding stage, an output-aware cache policy is proposed to further reduce the size of the KV cache. By leveraging tailored strategies in the multi-stage process, MustDrop can more precisely recognize the important and redundant tokens, thus achieving an optimal balance between performance and efficiency. For instance, MustDrop reduces about 88.5\% FLOPs on LLaVA with a compression ratio of 92.2\% while maintaining comparable accuracy. Our codes are available at \url{https://github.com/liuting20/MustDrop}.
Sparse-Tuning: Adapting Vision Transformers with Efficient Fine-tuning and Inference
May 23, 2024



Parameter-efficient fine-tuning (PEFT) has emerged as a popular approach for adapting pre-trained Vision Transformer (ViT) models to downstream applications. While current PEFT methods achieve parameter efficiency, they overlook GPU memory and time efficiency during both fine-tuning and inference, due to the repeated computation of redundant tokens in the ViT architecture. This falls short of practical requirements for downstream task adaptation. In this paper, we propose \textbf{Sparse-Tuning}, a novel tuning paradigm that substantially enhances both fine-tuning and inference efficiency for pre-trained ViT models. Sparse-Tuning efficiently fine-tunes the pre-trained ViT by sparsely preserving the informative tokens and merging redundant ones, enabling the ViT to focus on the foreground while reducing computational costs on background regions in the images. To accurately distinguish informative tokens from uninformative ones, we introduce a tailored Dense Adapter, which establishes dense connections across different encoder layers in the ViT, thereby enhancing the representational capacity and quality of token sparsification. Empirical results on VTAB-1K, three complete image datasets, and two complete video datasets demonstrate that Sparse-Tuning reduces the GFLOPs to \textbf{62\%-70\%} of the original ViT-B while achieving state-of-the-art performance. Source code is available at \url{https://github.com/liuting20/Sparse-Tuning}.
Autoregressive Queries for Adaptive Tracking with Spatio-TemporalTransformers
Mar 15, 2024The rich spatio-temporal information is crucial to capture the complicated target appearance variations in visual tracking. However, most top-performing tracking algorithms rely on many hand-crafted components for spatio-temporal information aggregation. Consequently, the spatio-temporal information is far away from being fully explored. To alleviate this issue, we propose an adaptive tracker with spatio-temporal transformers (named AQATrack), which adopts simple autoregressive queries to effectively learn spatio-temporal information without many hand-designed components. Firstly, we introduce a set of learnable and autoregressive queries to capture the instantaneous target appearance changes in a sliding window fashion. Then, we design a novel attention mechanism for the interaction of existing queries to generate a new query in current frame. Finally, based on the initial target template and learnt autoregressive queries, a spatio-temporal information fusion module (STM) is designed for spatiotemporal formation aggregation to locate a target object. Benefiting from the STM, we can effectively combine the static appearance and instantaneous changes to guide robust tracking. Extensive experiments show that our method significantly improves the tracker's performance on six popular tracking benchmarks: LaSOT, LaSOText, TrackingNet, GOT-10k, TNL2K, and UAV123.
Explicit Visual Prompts for Visual Object Tracking
Jan 06, 2024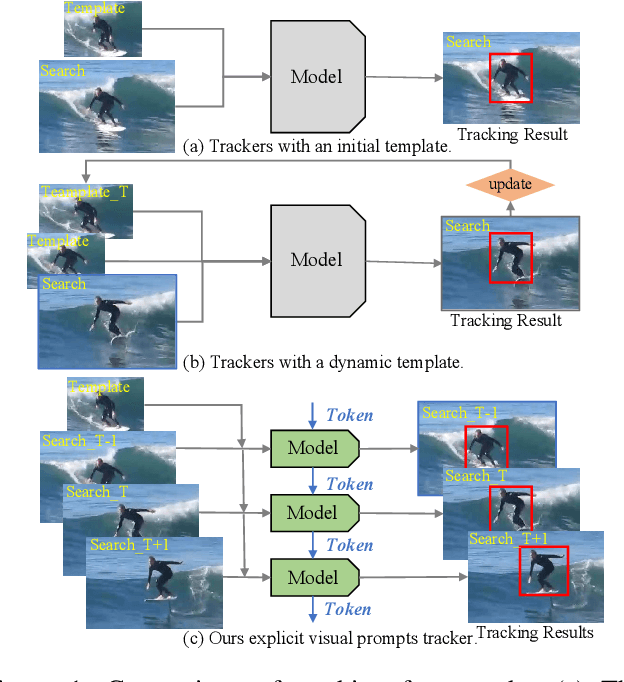
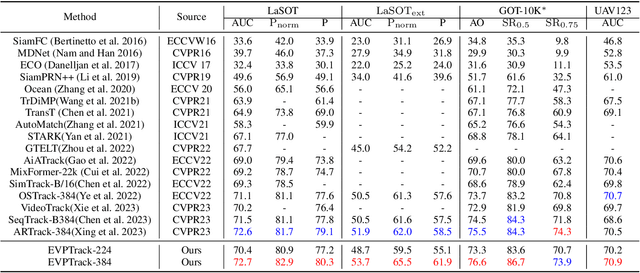
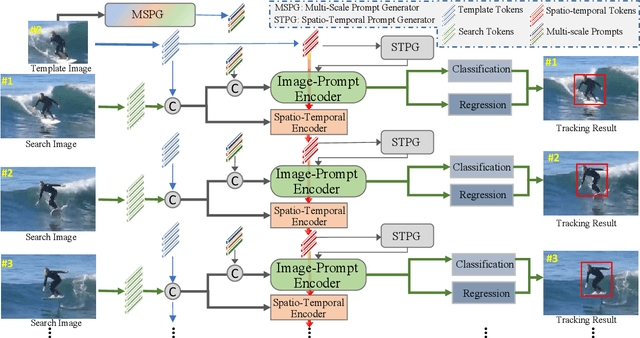

How to effectively exploit spatio-temporal information is crucial to capture target appearance changes in visual tracking. However, most deep learning-based trackers mainly focus on designing a complicated appearance model or template updating strategy, while lacking the exploitation of context between consecutive frames and thus entailing the \textit{when-and-how-to-update} dilemma. To address these issues, we propose a novel explicit visual prompts framework for visual tracking, dubbed \textbf{EVPTrack}. Specifically, we utilize spatio-temporal tokens to propagate information between consecutive frames without focusing on updating templates. As a result, we cannot only alleviate the challenge of \textit{when-to-update}, but also avoid the hyper-parameters associated with updating strategies. Then, we utilize the spatio-temporal tokens to generate explicit visual prompts that facilitate inference in the current frame. The prompts are fed into a transformer encoder together with the image tokens without additional processing. Consequently, the efficiency of our model is improved by avoiding \textit{how-to-update}. In addition, we consider multi-scale information as explicit visual prompts, providing multiscale template features to enhance the EVPTrack's ability to handle target scale changes. Extensive experimental results on six benchmarks (i.e., LaSOT, LaSOT\rm $_{ext}$, GOT-10k, UAV123, TrackingNet, and TNL2K.) validate that our EVPTrack can achieve competitive performance at a real-time speed by effectively exploiting both spatio-temporal and multi-scale information. Code and models are available at https://github.com/GXNU-ZhongLab/EVPTrack.