 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuSteerNet: Human Reaction Generation from Videos via Observation-Reaction Mutual Steering
Mar 20, 2026Video-driven human reaction generation aims to synthesize 3D human motions that directly react to observed video sequences, which is crucial for building human-like interactive AI systems. However, existing methods often fail to effectively leverage video inputs to steer human reaction synthesis, resulting in reaction motions that are mismatched with the content of video sequences. We reveal that this limitation arises from a severe relational distortion between visual observations and reaction types. In light of this, we propose MuSteerNet, a simple yet effective framework that generates 3D human reactions from videos via observation-reaction mutual steering. Specifically, we first propose a Prototype Feedback Steering mechanism to mitigate relational distortion by refining visual observations with a gated delta-rectification modulator and a relational margin constraint, guided by prototypical vectors learned from human reactions. We then introduce Dual-Coupled Reaction Refinement that fully leverages rectified visual cues to further steer the refinement of generated reaction motions, thereby effectively improving reaction quality and enabling MuSteerNet to achieve competitive performance. Extensive experiments and ablation studies validate the effectiveness of our method. Code coming soon: https://github.com/zhouyuan888888/MuSteerNet.
VGGT-Motion: Motion-Aware Calibration-Free Monocular SLAM for Long-Range Consistency
Feb 05, 2026Despite recent progress in calibration-free monocular SLAM via 3D vision foundation models, scale drift remains severe on long sequences. Motion-agnostic partitioning breaks contextual coherence and causes zero-motion drift, while conventional geometric alignment is computationally expensive. To address these issues, we propose VGGT-Motion, a calibration-free SLAM system for efficient and robust global consistency over kilometer-scale trajectories. Specifically, we first propose a motion-aware submap construction mechanism that uses optical flow to guide adaptive partitioning, prune static redundancy, and encapsulate turns for stable local geometry. We then design an anchor-driven direct Sim(3) registration strategy. By exploiting context-balanced anchors, it achieves search-free, pixel-wise dense alignment and efficient loop closure without costly feature matching. Finally, a lightweight submap-level pose graph optimization enforces global consistency with linear complexity, enabling scalable long-range operation. Experiments show that VGGT-Motion markedly improves trajectory accuracy and efficiency, achieving state-of-the-art performance in zero-shot, long-range calibration-free monocular SLAM.
NeuSpring: Neural Spring Fields for Reconstruction and Simulation of Deformable Objects from Videos
Nov 11, 2025In this paper, we aim to create physical digital twins of deformable objects under interaction. Existing methods focus more on the physical learning of current state modeling, but generalize worse to future prediction. This is because existing methods ignore the intrinsic physical properties of deformable objects, resulting in the limited physical learning in the current state modeling. To address this, we present NeuSpring, a neural spring field for the reconstruction and simulation of deformable objects from videos. Built upon spring-mass models for realistic physical simulation, our method consists of two major innovations: 1) a piecewise topology solution that efficiently models multi-region spring connection topologies using zero-order optimization, which considers the material heterogeneity of real-world objects. 2) a neural spring field that represents spring physical properties across different frames using a canonical coordinate-based neural network, which effectively leverages the spatial associativity of springs for physical learning. Experiments on real-world datasets demonstrate that our NeuSping achieves superior reconstruction and simulation performance for current state modeling and future prediction, with Chamfer distance improved by 20% and 25%, respectively.
Lightweight and Accurate Multi-View Stereo with Confidence-Aware Diffusion Model
Sep 18, 2025To reconstruct the 3D geometry from calibrated images, learning-based multi-view stereo (MVS) methods typically perform multi-view depth estimation and then fuse depth maps into a mesh or point cloud. To improve the computational efficiency, many methods initialize a coarse depth map and then gradually refine it in higher resolutions. Recently, diffusion models achieve great success in generation tasks. Starting from a random noise, diffusion models gradually recover the sample with an iterative denoising process. In this paper, we propose a novel MVS framework, which introduces diffusion models in MVS. Specifically, we formulate depth refinement as a conditional diffusion process. Considering the discriminative characteristic of depth estimation, we design a condition encoder to guide the diffusion process. To improve efficiency, we propose a novel diffusion network combining lightweight 2D U-Net and convolutional GRU. Moreover, we propose a novel confidence-based sampling strategy to adaptively sample depth hypotheses based on the confidence estimated by diffusion model. Based on our novel MVS framework, we propose two novel MVS methods, DiffMVS and CasDiffMVS. DiffMVS achieves competitive performance with state-of-the-art efficiency in run-time and GPU memory. CasDiffMVS achieves state-of-the-art performance on DTU, Tanks & Temples and ETH3D. Code is available at: https://github.com/cvg/diffmvs.
DragNeXt: Rethinking Drag-Based Image Editing
Jun 09, 2025

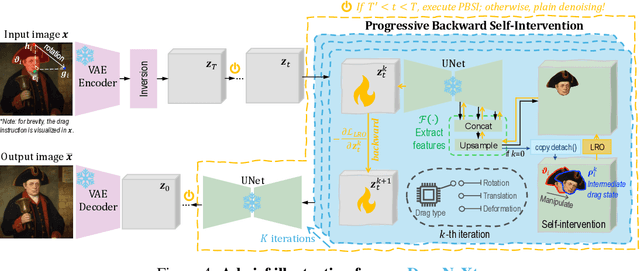

Drag-Based Image Editing (DBIE), which allows users to manipulate images by directly dragging objects within them, has recently attracted much attention from the community. However, it faces two key challenges: (\emph{\textcolor{magenta}{i}}) point-based drag is often highly ambiguous and difficult to align with users' intentions; (\emph{\textcolor{magenta}{ii}}) current DBIE methods primarily rely on alternating between motion supervision and point tracking, which is not only cumbersome but also fails to produce high-quality results. These limitations motivate us to explore DBIE from a new perspective -- redefining it as deformation, rotation, and translation of user-specified handle regions. Thereby, by requiring users to explicitly specify both drag areas and types, we can effectively address the ambiguity issue. Furthermore, we propose a simple-yet-effective editing framework, dubbed \textcolor{SkyBlue}{\textbf{DragNeXt}}. It unifies DBIE as a Latent Region Optimization (LRO) problem and solves it through Progressive Backward Self-Intervention (PBSI), simplifying the overall procedure of DBIE while further enhancing quality by fully leveraging region-level structure information and progressive guidance from intermediate drag states. We validate \textcolor{SkyBlue}{\textbf{DragNeXt}} on our NextBench, and extensive experiments demonstrate that our proposed method can significantly outperform existing approaches. Code will be released on github.
Personalize Your Gaussian: Consistent 3D Scene Personalization from a Single Image
May 20, 2025Personalizing 3D scenes from a single reference image enables intuitive user-guided editing, which requires achieving both multi-view consistency across perspectives and referential consistency with the input image. However, these goals are particularly challenging due to the viewpoint bias caused by the limited perspective provided in a single image. Lacking the mechanisms to effectively expand reference information beyond the original view, existing methods of image-conditioned 3DGS personalization often suffer from this viewpoint bias and struggle to produce consistent results. Therefore, in this paper, we present Consistent Personalization for 3D Gaussian Splatting (CP-GS), a framework that progressively propagates the single-view reference appearance to novel perspectives. In particular, CP-GS integrates pre-trained image-to-3D generation and iterative LoRA fine-tuning to extract and extend the reference appearance, and finally produces faithful multi-view guidance images and the personalized 3DGS outputs through a view-consistent generation process guided by geometric cues. Extensive experiments on real-world scenes show that our CP-GS effectively mitigates the viewpoint bias, achieving high-quality personalization that significantly outperforms existing methods. The code will be released at https://github.com/Yuxuan-W/CP-GS.
On Path to Multimodal Generalist: General-Level and General-Bench
May 07, 2025The Multimodal Large Language Model (MLLM) is currently experiencing rapid growth, driven by the advanced capabilities of LLMs. Unlike earlier specialists, existing MLLMs are evolving towards a Multimodal Generalist paradigm. Initially limited to understanding multiple modalities, these models have advanced to not only comprehend but also generate across modalities. Their capabilities have expanded from coarse-grained to fine-grained multimodal understanding and from supporting limited modalities to arbitrary ones. While many benchmarks exist to assess MLLMs, a critical question arises: Can we simply assume that higher performance across tasks indicates a stronger MLLM capability, bringing us closer to human-level AI? We argue that the answer is not as straightforward as it seems. This project introduces General-Level, an evaluation framework that defines 5-scale levels of MLLM performance and generality, offering a methodology to compare MLLMs and gauge the progress of existing systems towards more robust multimodal generalists and, ultimately, towards AGI. At the core of the framework is the concept of Synergy, which measures whether models maintain consistent capabilities across comprehension and generation, and across multiple modalities. To support this evaluation, we present General-Bench, which encompasses a broader spectrum of skills, modalities, formats, and capabilities, including over 700 tasks and 325,800 instances. The evaluation results that involve over 100 existing state-of-the-art MLLMs uncover the capability rankings of generalists, highlighting the challenges in reaching genuine AI. We expect this project to pave the way for future research on next-generation multimodal foundation models, providing a robust infrastructure to accelerate the realization of AGI. Project page: https://generalist.top/
Generalized Kullback-Leibler Divergence Loss
Mar 11, 2025In this paper, we delve deeper into the Kullback-Leibler (KL) Divergence loss and mathematically prove that it is equivalent to the Decoupled Kullback-Leibler (DKL) Divergence loss that consists of (1) a weighted Mean Square Error (wMSE) loss and (2) a Cross-Entropy loss incorporating soft labels. Thanks to the decoupled structure of DKL loss, we have identified two areas for improvement. Firstly, we address the limitation of KL loss in scenarios like knowledge distillation by breaking its asymmetric optimization property along with a smoother weight function. This modification effectively alleviates convergence challenges in optimization, particularly for classes with high predicted scores in soft labels. Secondly, we introduce class-wise global information into KL/DKL to reduce bias arising from individual samples. With these two enhancements, we derive the Generalized Kullback-Leibler (GKL) Divergence loss and evaluate its effectiveness by conducting experiments on CIFAR-10/100, ImageNet, and vision-language datasets, focusing on adversarial training, and knowledge distillation tasks. Specifically, we achieve new state-of-the-art adversarial robustness on the public leaderboard -- RobustBench and competitive knowledge distillation performance across CIFAR/ImageNet models and CLIP models, demonstrating the substantial practical merits. Our code is available at https://github.com/jiequancui/DKL.
Nautilus: Locality-aware Autoencoder for Scalable Mesh Generation
Jan 27, 2025



Triangle meshes are fundamental to 3D applications, enabling efficient modification and rasterization while maintaining compatibility with standard rendering pipelines. However, current automatic mesh generation methods typically rely on intermediate representations that lack the continuous surface quality inherent to meshes. Converting these representations into meshes produces dense, suboptimal outputs. Although recent autoregressive approaches demonstrate promise in directly modeling mesh vertices and faces, they are constrained by the limitation in face count, scalability, and structural fidelity. To address these challenges, we propose Nautilus, a locality-aware autoencoder for artist-like mesh generation that leverages the local properties of manifold meshes to achieve structural fidelity and efficient representation. Our approach introduces a novel tokenization algorithm that preserves face proximity relationships and compresses sequence length through locally shared vertices and edges, enabling the generation of meshes with an unprecedented scale of up to 5,000 faces. Furthermore, we develop a Dual-stream Point Conditioner that provides multi-scale geometric guidance, ensuring global consistency and local structural fidelity by capturing fine-grained geometric features. Extensive experiments demonstrate that Nautilus significantly outperforms state-of-the-art methods in both fidelity and scalability. The project page will be released to https://nautilusmeshgen.github.io.
Pushing Rendering Boundaries: Hard Gaussian Splatting
Dec 06, 20243D Gaussian Splatting (3DGS) has demonstrated impressive Novel View Synthesis (NVS) results in a real-time rendering manner. During training, it relies heavily on the average magnitude of view-space positional gradients to grow Gaussians to reduce rendering loss. However, this average operation smooths the positional gradients from different viewpoints and rendering errors from different pixels, hindering the growth and optimization of many defective Gaussians. This leads to strong spurious artifacts in some areas. To address this problem, we propose Hard Gaussian Splatting, dubbed HGS, which considers multi-view significant positional gradients and rendering errors to grow hard Gaussians that fill the gaps of classical Gaussian Splatting on 3D scenes, thus achieving superior NVS results. In detail, we present positional gradient driven HGS, which leverages multi-view significant positional gradients to uncover hard Gaussians. Moreover, we propose rendering error guided HGS, which identifies noticeable pixel rendering errors and potentially over-large Gaussians to jointly mine hard Gaussians. By growing and optimizing these hard Gaussians, our method helps to resolve blurring and needle-like artifacts. Experiments on various datasets demonstrate that our method achieves state-of-the-art rendering quality while maintaining real-time efficiency.