 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagine Before You Draw: Visual Prompt Engineering for Image Generation
Jun 03, 2026Incorporating visual semantic representations as an intermediate step before image generation can reduce the modeling difficulty between text and images, thereby improving generation quality. Recent works such as X-Omni and BLIP3o-Next have explored this direction, but they typically use a two-stage external pipeline: a separate autoregressive model first generates semantic tokens, which are then fed as conditioning to an independent diffusion decoder. Since the decoder cannot jointly access the original input and the semantic plan, this design introduces an information bottleneck that limits detail preservation in downstream tasks such as editing. Internal architectures such as Transfusion, BAGEL, and Show-o2 avoid this bottleneck by enabling cross-modal interaction within a single model, but they still face the difficult text-to-pixel modeling gap without intermediate semantic guidance. We propose Visual Prompt Engineering (VPE), which can be seamlessly integrated into such internal frameworks. Specifically, the model first autoregressively generates visual semantic tokens (e.g., SigLIP 2) as "visual prompts" that capture the semantic layout, then generates the full image tokens conditioned on this plan. We validate VPE across class-conditional generation, text-to-image generation, and image editing, covering various token types and model architectures. Results show that VPE can accelerate convergence, raise quality ceilings, and through internal integration, achieve substantially better editing preservation (PSNR: 26.76 vs. 19.92) than external alternatives of the same parameter scale, while maintaining competitive editing responsiveness.
Principled Steering via Null-space Projection for Jailbreak Defense in Vision-Language Models
Mar 23, 2026As vision-language models (VLMs) are increasingly deployed in open-world scenarios, they can be easily induced by visual jailbreak attacks to generate harmful content, posing serious risks to model safety and trustworthy usage. Recent activation steering methods inject directional vectors into model activations during inference to induce refusal behaviors and have demonstrated effectiveness. However, a steering vector may both enhance refusal ability and cause over-refusal, thereby degrading model performance on benign inputs. Moreover, due to the lack of theoretical interpretability, these methods still suffer from limited robustness and effectiveness. To better balance safety and utility, we propose NullSteer, a null-space projected activation defense framework. Our method constructs refusal directions within model activations through a linear transformation: it maintains zero perturbation within the benign subspace while dynamically inducing refusal along potentially harmful directions, thereby theoretically achieving safety enhancement without impairing the model's general capabilities. Extensive experiments show that NullSteer significantly reduces harmful outputs under various jailbreak attacks (average ASR reduction over 15 percent on MiniGPT-4) while maintaining comparable performance to the original model on general benchmarks.
Look Carefully: Adaptive Visual Reinforcements in Multimodal Large Language Models for Hallucination Mitigation
Feb 27, 2026Multimodal large language models (MLLMs) have achieved remarkable progress in vision-language reasoning, yet they remain vulnerable to hallucination, where generated content deviates from visual evidence. Existing mitigation strategies either require costly supervision during training or introduce additional latency at inference time. Recent vision enhancement methods attempt to address this issue by reinforcing visual tokens during decoding, but they typically inject all tokens indiscriminately, which causes interference from background regions and distracts the model from critical cues. To overcome this challenge, we propose Adaptive Visual Reinforcement (AIR), a training-free framework for MLLMs. AIR consists of two components. Prototype-based token reduction condenses the large pool of visual tokens into a compact subset to suppress redundancy. OT-guided patch reinforcement quantifies the alignment between hidden states and patch embeddings to selectively integrate the most consistent patches into feed-forward layers. As a result, AIR enhances the model's reliance on salient visual information and effectively mitigates hallucination. Extensive experiments across representative MLLMs demonstrate that AIR substantially reduces hallucination while preserving general capabilities, establishing it as an effective solution for building reliable MLLMs.
Thinking with Images as Continuous Actions: Numerical Visual Chain-of-Thought
Feb 27, 2026Recent multimodal large language models (MLLMs) increasingly rely on visual chain-of-thought to perform region-grounded reasoning over images. However, existing approaches ground regions via either textified coordinates-causing modality mismatch and semantic fragmentation or fixed-granularity patches that both limit precise region selection and often require non-trivial architectural changes. In this paper, we propose Numerical Visual Chain-of-Thought (NV-CoT), a framework that enables MLLMs to reason over images using continuous numerical coordinates. NV-CoT expands the MLLM action space from discrete vocabulary tokens to a continuous Euclidean space, allowing models to directly generate bounding-box coordinates as actions with only minimal architectural modification. The framework supports both supervised fine-tuning and reinforcement learning. In particular, we replace categorical token policies with a Gaussian (or Laplace) policy over coordinates and introduce stochasticity via reparameterized sampling, making NV-CoT fully compatible with GRPO-style policy optimization. Extensive experiments on three benchmarks against eight representative visual reasoning baselines demonstrate that NV-CoT significantly improves localization precision and final answer accuracy, while also accelerating training convergence, validating the effectiveness of continuous-action visual reasoning in MLLMs. The code is available in https://github.com/kesenzhao/NV-CoT.
Reducing Class-Wise Performance Disparity via Margin Regularization
Jan 30, 2026Deep neural networks often exhibit substantial disparities in class-wise accuracy, even when trained on class-balanced data, posing concerns for reliable deployment. While prior efforts have explored empirical remedies, a theoretical understanding of such performance disparities in classification remains limited. In this work, we present Margin Regularization for Performance Disparity Reduction (MR$^2$), a theoretically principled regularization for classification by dynamically adjusting margins in both the logit and representation spaces. Our analysis establishes a margin-based, class-sensitive generalization bound that reveals how per-class feature variability contributes to error, motivating the use of larger margins for hard classes. Guided by this insight, MR$^2$ optimizes per-class logit margins proportional to feature spread and penalizes excessive representation margins to enhance intra-class compactness. Experiments on seven datasets, including ImageNet, and diverse pre-trained backbones (MAE, MoCov2, CLIP) demonstrate that MR$^2$ not only improves overall accuracy but also significantly boosts hard class performance without trading off easy classes, thus reducing performance disparity. Code is available at: https://github.com/BeierZhu/MR2
DragNeXt: Rethinking Drag-Based Image Editing
Jun 09, 2025

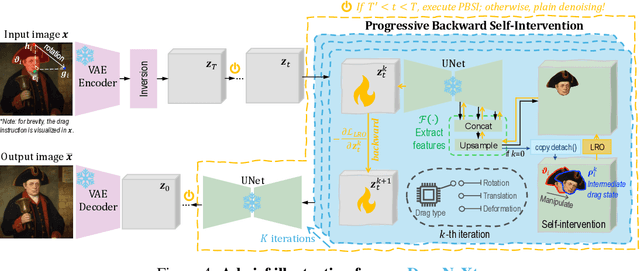

Drag-Based Image Editing (DBIE), which allows users to manipulate images by directly dragging objects within them, has recently attracted much attention from the community. However, it faces two key challenges: (\emph{\textcolor{magenta}{i}}) point-based drag is often highly ambiguous and difficult to align with users' intentions; (\emph{\textcolor{magenta}{ii}}) current DBIE methods primarily rely on alternating between motion supervision and point tracking, which is not only cumbersome but also fails to produce high-quality results. These limitations motivate us to explore DBIE from a new perspective -- redefining it as deformation, rotation, and translation of user-specified handle regions. Thereby, by requiring users to explicitly specify both drag areas and types, we can effectively address the ambiguity issue. Furthermore, we propose a simple-yet-effective editing framework, dubbed \textcolor{SkyBlue}{\textbf{DragNeXt}}. It unifies DBIE as a Latent Region Optimization (LRO) problem and solves it through Progressive Backward Self-Intervention (PBSI), simplifying the overall procedure of DBIE while further enhancing quality by fully leveraging region-level structure information and progressive guidance from intermediate drag states. We validate \textcolor{SkyBlue}{\textbf{DragNeXt}} on our NextBench, and extensive experiments demonstrate that our proposed method can significantly outperform existing approaches. Code will be released on github.
Unsupervised Visual Chain-of-Thought Reasoning via Preference Optimization
Apr 25, 2025Chain-of-thought (CoT) reasoning greatly improves the interpretability and problem-solving abilities of multimodal large language models (MLLMs). However, existing approaches are focused on text CoT, limiting their ability to leverage visual cues. Visual CoT remains underexplored, and the only work is based on supervised fine-tuning (SFT) that relies on extensive labeled bounding-box data and is hard to generalize to unseen cases. In this paper, we introduce Unsupervised Visual CoT (UV-CoT), a novel framework for image-level CoT reasoning via preference optimization. UV-CoT performs preference comparisons between model-generated bounding boxes (one is preferred and the other is dis-preferred), eliminating the need for bounding-box annotations. We get such preference data by introducing an automatic data generation pipeline. Given an image, our target MLLM (e.g., LLaVA-1.5-7B) generates seed bounding boxes using a template prompt and then answers the question using each bounded region as input. An evaluator MLLM (e.g., OmniLLM-12B) ranks the responses, and these rankings serve as supervision to train the target MLLM with UV-CoT by minimizing negative log-likelihood losses. By emulating human perception--identifying key regions and reasoning based on them--UV-CoT can improve visual comprehension, particularly in spatial reasoning tasks where textual descriptions alone fall short. Our experiments on six datasets demonstrate the superiority of UV-CoT, compared to the state-of-the-art textual and visual CoT methods. Our zero-shot testing on four unseen datasets shows the strong generalization of UV-CoT. The code is available in https://github.com/kesenzhao/UV-CoT.
Sequential Recommendation for Optimizing Both Immediate Feedback and Long-term Retention
Apr 04, 2024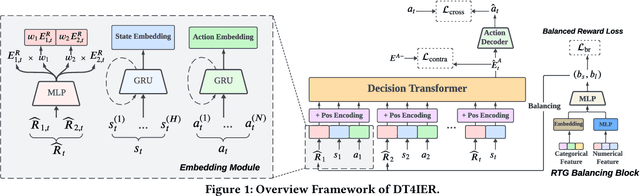
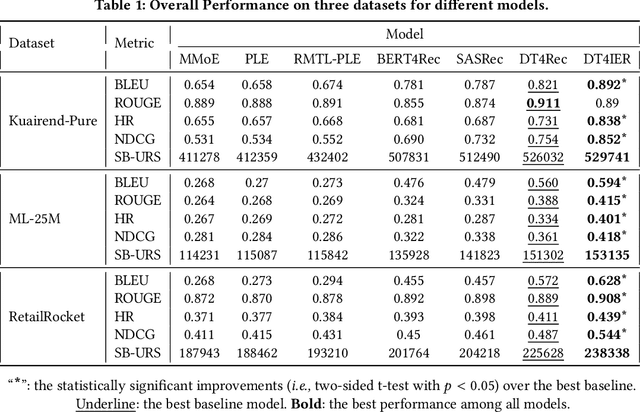
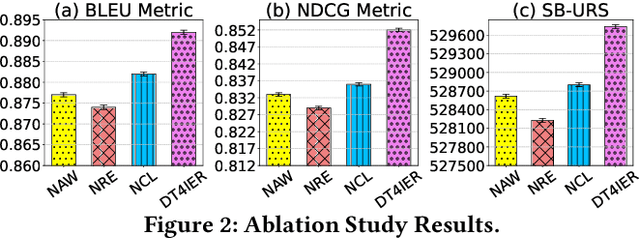
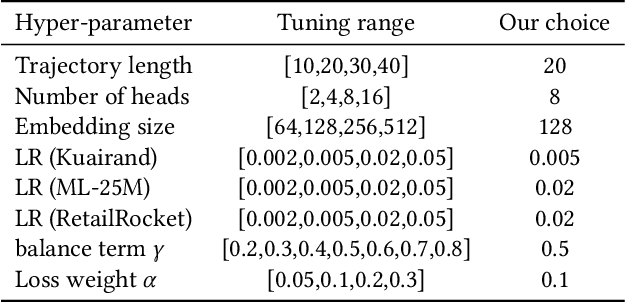
In the landscape of Recommender System (RS) applications, reinforcement learning (RL) has recently emerged as a powerful tool, primarily due to its proficiency in optimizing long-term rewards. Nevertheless, it suffers from instability in the learning process, stemming from the intricate interactions among bootstrapping, off-policy training, and function approximation. Moreover, in multi-reward recommendation scenarios, designing a proper reward setting that reconciles the inner dynamics of various tasks is quite intricate. In response to these challenges, we introduce DT4IER, an advanced decision transformer-based recommendation model that is engineered to not only elevate the effectiveness of recommendations but also to achieve a harmonious balance between immediate user engagement and long-term retention. The DT4IER applies an innovative multi-reward design that adeptly balances short and long-term rewards with user-specific attributes, which serve to enhance the contextual richness of the reward sequence ensuring a more informed and personalized recommendation process. To enhance its predictive capabilities, DT4IER incorporates a high-dimensional encoder, skillfully designed to identify and leverage the intricate interrelations across diverse tasks. Furthermore, we integrate a contrastive learning approach within the action embedding predictions, a strategy that significantly boosts the model's overall performance. Experiments on three real-world datasets demonstrate the effectiveness of DT4IER against state-of-the-art Sequential Recommender Systems (SRSs) and Multi-Task Learning (MTL) models in terms of both prediction accuracy and effectiveness in specific tasks. The source code is accessible online to facilitate replication
KuaiSim: A Comprehensive Simulator for Recommender Systems
Sep 22, 2023



Reinforcement Learning (RL)-based recommender systems (RSs) have garnered considerable attention due to their ability to learn optimal recommendation policies and maximize long-term user rewards. However, deploying RL models directly in online environments and generating authentic data through A/B tests can pose challenges and require substantial resources. Simulators offer an alternative approach by providing training and evaluation environments for RS models, reducing reliance on real-world data. Existing simulators have shown promising results but also have limitations such as simplified user feedback, lacking consistency with real-world data, the challenge of simulator evaluation, and difficulties in migration and expansion across RSs. To address these challenges, we propose KuaiSim, a comprehensive user environment that provides user feedback with multi-behavior and cross-session responses. The resulting simulator can support three levels of recommendation problems: the request level list-wise recommendation task, the whole-session level sequential recommendation task, and the cross-session level retention optimization task. For each task, KuaiSim also provides evaluation protocols and baseline recommendation algorithms that further serve as benchmarks for future research. We also restructure existing competitive simulators on the KuaiRand Dataset and compare them against KuaiSim to future assess their performance and behavioral differences. Furthermore, to showcase KuaiSim's flexibility in accommodating different datasets, we demonstrate its versatility and robustness when deploying it on the ML-1m dataset.
User Retention-oriented Recommendation with Decision Transformer
Mar 11, 2023



Improving user retention with reinforcement learning~(RL) has attracted increasing attention due to its significant importance in boosting user engagement. However, training the RL policy from scratch without hurting users' experience is unavoidable due to the requirement of trial-and-error searches. Furthermore, the offline methods, which aim to optimize the policy without online interactions, suffer from the notorious stability problem in value estimation or unbounded variance in counterfactual policy evaluation. To this end, we propose optimizing user retention with Decision Transformer~(DT), which avoids the offline difficulty by translating the RL as an autoregressive problem. However, deploying the DT in recommendation is a non-trivial problem because of the following challenges: (1) deficiency in modeling the numerical reward value; (2) data discrepancy between the policy learning and recommendation generation; (3) unreliable offline performance evaluation. In this work, we, therefore, contribute a series of strategies for tackling the exposed issues. We first articulate an efficient reward prompt by weighted aggregation of meta embeddings for informative reward embedding. Then, we endow a weighted contrastive learning method to solve the discrepancy between training and inference. Furthermore, we design two robust offline metrics to measure user retention. Finally, the significant improvement in the benchmark datasets demonstrates the superiority of the proposed method.