 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Distilled Trajectory-Aware Boltzmann Modeling: Bridging the Training-Inference Discrepancy in Diffusion Language Models
May 12, 2026Diffusion Language Models (DLMs) have recently emerged as a promising alternative to autoregressive language models, offering stronger global awareness and highly parallel generation. However, post-training DLMs with standard Negative Evidence Lower Bound (NELBO)-based supervised fine-tuning remains inefficient: training reconstructs randomly masked tokens in a single step, whereas inference follows a confidence-guided, multi-step easy-to-hard denoising trajectory. Recent trajectory-based self-distillation methods exploit such inference trajectories mainly for sampling-step compression and acceleration, often improving decoding efficiency without substantially enhancing the model's underlying capability, and may even degrade performance under full diffusion decoding. In this work, we ask whether self-distilled trajectories can be used not merely for faster inference, but for genuine knowledge acquisition. Although these trajectories lie on the pretrained DLM's own distributional manifold and thus offer a potentially lower optimization barrier, we find that naively fine-tuning on them with standard NELBO objectives yields only marginal gains. To address this limitation, we propose \textbf{T}rajectory-\textbf{A}ligned optimization via \textbf{Bo}ltzmann \textbf{M}odeling (\textbf{TABOM}), a self-distilled trajectory-based post-training framework that aligns training with the easy-to-hard structure of inference. TABOM models the inference unmasking preference as a Boltzmann distribution over predictive entropies and derives a tractable pairwise ranking objective to align the model's certainty ordering with the observed decoding trajectory. Empirically, TABOM achieves substantial gains in new domains, expands the effective knowledge boundary of DLMs, and significantly mitigates catastrophic forgetting compared with standard SFT.
CoVe: Training Interactive Tool-Use Agents via Constraint-Guided Verification
Mar 02, 2026Developing multi-turn interactive tool-use agents is challenging because real-world user needs are often complex and ambiguous, yet agents must execute deterministic actions to satisfy them. To address this gap, we introduce \textbf{CoVe} (\textbf{Co}nstraint-\textbf{Ve}rification), a post-training data synthesis framework designed for training interactive tool-use agents while ensuring both data complexity and correctness. CoVe begins by defining explicit task constraints, which serve a dual role: they guide the generation of complex trajectories and act as deterministic verifiers for assessing trajectory quality. This enables the creation of high-quality training trajectories for supervised fine-tuning (SFT) and the derivation of accurate reward signals for reinforcement learning (RL). Our evaluation on the challenging $τ^2$-bench benchmark demonstrates the effectiveness of the framework. Notably, our compact \textbf{CoVe-4B} model achieves success rates of 43.0\% and 59.4\% in the Airline and Retail domains, respectively; its overall performance significantly outperforms strong baselines of similar scale and remains competitive with models up to $17\times$ its size. These results indicate that CoVe provides an effective and efficient pathway for synthesizing training data for state-of-the-art interactive tool-use agents. To support future research, we open-source our code, trained model, and the full set of 12K high-quality trajectories used for training.
Efficient Reasoning via Reward Model
Nov 12, 2025Reinforcement learning with verifiable rewards (RLVR) has been shown to enhance the reasoning capabilities of large language models (LLMs), enabling the development of large reasoning models (LRMs). However, LRMs such as DeepSeek-R1 and OpenAI o1 often generate verbose responses containing redundant or irrelevant reasoning step-a phenomenon known as overthinking-which substantially increases computational costs. Prior efforts to mitigate this issue commonly incorporate length penalties into the reward function, but we find they frequently suffer from two critical issues: length collapse and training collapse, resulting in sub-optimal performance. To address them, we propose a pipeline for training a Conciseness Reward Model (CRM) that scores the conciseness of reasoning path. Additionally, we introduce a novel reward formulation named Conciseness Reward Function (CRF) with explicit dependency between the outcome reward and conciseness score, thereby fostering both more effective and more efficient reasoning. From a theoretical standpoint, we demonstrate the superiority of the new reward from the perspective of variance reduction and improved convergence properties. Besides, on the practical side, extensive experiments on five mathematical benchmark datasets demonstrate the method's effectiveness and token efficiency, which achieves an 8.1% accuracy improvement and a 19.9% reduction in response token length on Qwen2.5-7B. Furthermore, the method generalizes well to other LLMs including Llama and Mistral. The implementation code and datasets are publicly available for reproduction: https://anonymous.4open.science/r/CRM.
LLM-Powered User Simulator for Recommender System
Dec 22, 2024



User simulators can rapidly generate a large volume of timely user behavior data, providing a testing platform for reinforcement learning-based recommender systems, thus accelerating their iteration and optimization. However, prevalent user simulators generally suffer from significant limitations, including the opacity of user preference modeling and the incapability of evaluating simulation accuracy. In this paper, we introduce an LLM-powered user simulator to simulate user engagement with items in an explicit manner, thereby enhancing the efficiency and effectiveness of reinforcement learning-based recommender systems training. Specifically, we identify the explicit logic of user preferences, leverage LLMs to analyze item characteristics and distill user sentiments, and design a logical model to imitate real human engagement. By integrating a statistical model, we further enhance the reliability of the simulation, proposing an ensemble model that synergizes logical and statistical insights for user interaction simulations. Capitalizing on the extensive knowledge and semantic generation capabilities of LLMs, our user simulator faithfully emulates user behaviors and preferences, yielding high-fidelity training data that enrich the training of recommendation algorithms. We establish quantifying and qualifying experiments on five datasets to validate the simulator's effectiveness and stability across various recommendation scenarios.
Modeling User Retention through Generative Flow Networks
Jun 10, 2024



Recommender systems aim to fulfill the user's daily demands. While most existing research focuses on maximizing the user's engagement with the system, it has recently been pointed out that how frequently the users come back for the service also reflects the quality and stability of recommendations. However, optimizing this user retention behavior is non-trivial and poses several challenges including the intractable leave-and-return user activities, the sparse and delayed signal, and the uncertain relations between users' retention and their immediate feedback towards each item in the recommendation list. In this work, we regard the retention signal as an overall estimation of the user's end-of-session satisfaction and propose to estimate this signal through a probabilistic flow. This flow-based modeling technique can back-propagate the retention reward towards each recommended item in the user session, and we show that the flow combined with traditional learning-to-rank objectives eventually optimizes a non-discounted cumulative reward for both immediate user feedback and user retention. We verify the effectiveness of our method through both offline empirical studies on two public datasets and online A/B tests in an industrial platform.
M3oE: Multi-Domain Multi-Task Mixture-of Experts Recommendation Framework
Apr 29, 2024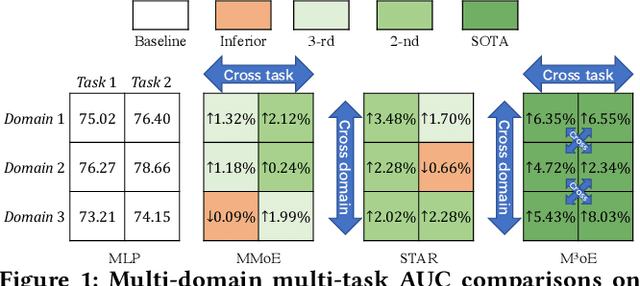
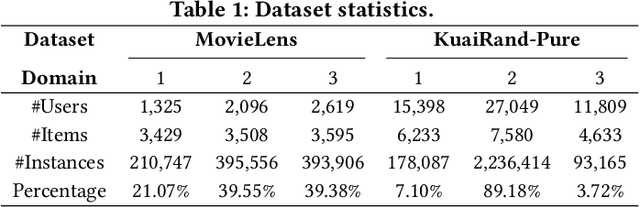
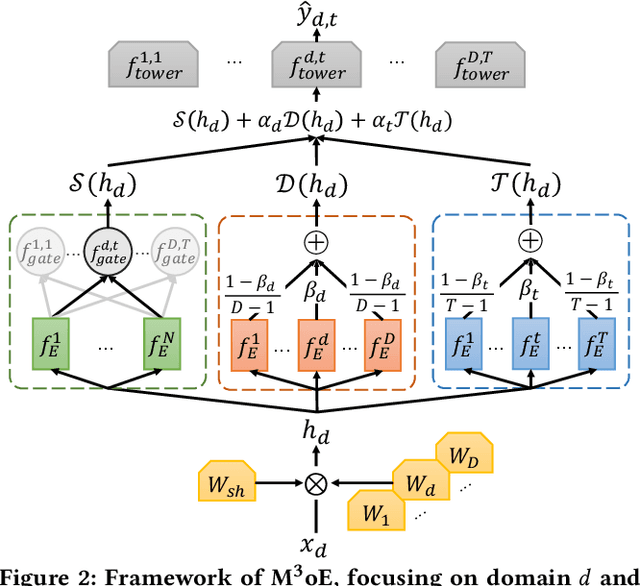
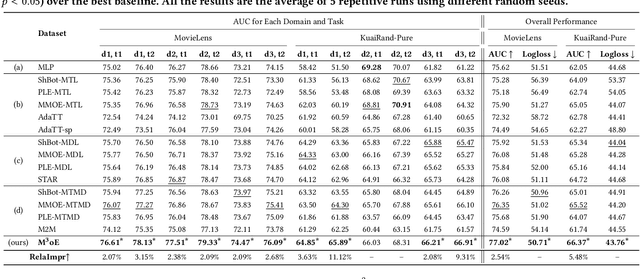
Multi-domain recommendation and multi-task recommendation have demonstrated their effectiveness in leveraging common information from different domains and objectives for comprehensive user modeling. Nonetheless, the practical recommendation usually faces multiple domains and tasks simultaneously, which cannot be well-addressed by current methods. To this end, we introduce M3oE, an adaptive multi-domain multi-task mixture-of-experts recommendation framework. M3oE integrates multi-domain information, maps knowledge across domains and tasks, and optimizes multiple objectives. We leverage three mixture-of-experts modules to learn common, domain-aspect, and task-aspect user preferences respectively to address the complex dependencies among multiple domains and tasks in a disentangled manner. Additionally, we design a two-level fusion mechanism for precise control over feature extraction and fusion across diverse domains and tasks. The framework's adaptability is further enhanced by applying AutoML technique, which allows dynamic structure optimization. To the best of the authors' knowledge, our M3oE is the first effort to solve multi-domain multi-task recommendation self-adaptively. Extensive experiments on two benchmark datasets against diverse baselines demonstrate M3oE's superior performance. The implementation code is available to ensure reproducibility.
Sequential Recommendation for Optimizing Both Immediate Feedback and Long-term Retention
Apr 04, 2024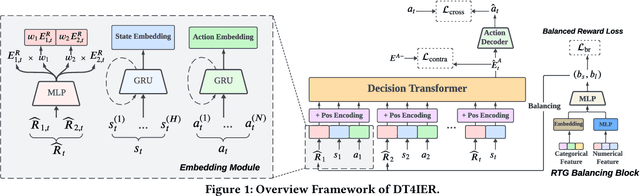
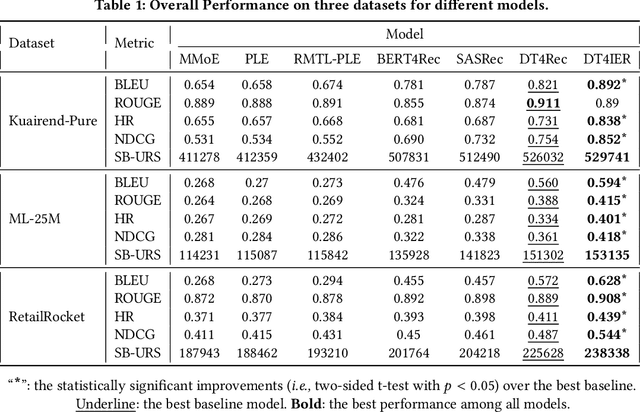
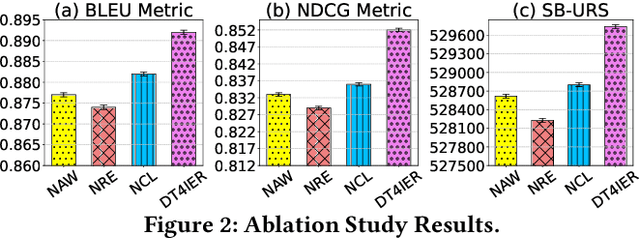
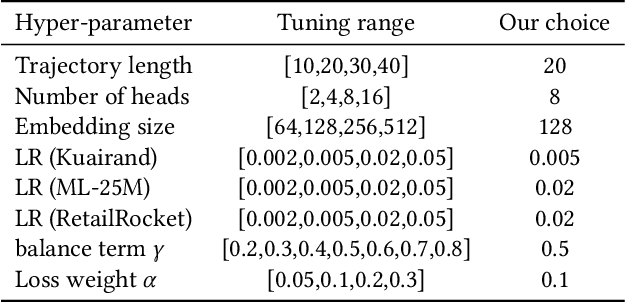
In the landscape of Recommender System (RS) applications, reinforcement learning (RL) has recently emerged as a powerful tool, primarily due to its proficiency in optimizing long-term rewards. Nevertheless, it suffers from instability in the learning process, stemming from the intricate interactions among bootstrapping, off-policy training, and function approximation. Moreover, in multi-reward recommendation scenarios, designing a proper reward setting that reconciles the inner dynamics of various tasks is quite intricate. In response to these challenges, we introduce DT4IER, an advanced decision transformer-based recommendation model that is engineered to not only elevate the effectiveness of recommendations but also to achieve a harmonious balance between immediate user engagement and long-term retention. The DT4IER applies an innovative multi-reward design that adeptly balances short and long-term rewards with user-specific attributes, which serve to enhance the contextual richness of the reward sequence ensuring a more informed and personalized recommendation process. To enhance its predictive capabilities, DT4IER incorporates a high-dimensional encoder, skillfully designed to identify and leverage the intricate interrelations across diverse tasks. Furthermore, we integrate a contrastive learning approach within the action embedding predictions, a strategy that significantly boosts the model's overall performance. Experiments on three real-world datasets demonstrate the effectiveness of DT4IER against state-of-the-art Sequential Recommender Systems (SRSs) and Multi-Task Learning (MTL) models in terms of both prediction accuracy and effectiveness in specific tasks. The source code is accessible online to facilitate replication
KuaiSim: A Comprehensive Simulator for Recommender Systems
Sep 22, 2023



Reinforcement Learning (RL)-based recommender systems (RSs) have garnered considerable attention due to their ability to learn optimal recommendation policies and maximize long-term user rewards. However, deploying RL models directly in online environments and generating authentic data through A/B tests can pose challenges and require substantial resources. Simulators offer an alternative approach by providing training and evaluation environments for RS models, reducing reliance on real-world data. Existing simulators have shown promising results but also have limitations such as simplified user feedback, lacking consistency with real-world data, the challenge of simulator evaluation, and difficulties in migration and expansion across RSs. To address these challenges, we propose KuaiSim, a comprehensive user environment that provides user feedback with multi-behavior and cross-session responses. The resulting simulator can support three levels of recommendation problems: the request level list-wise recommendation task, the whole-session level sequential recommendation task, and the cross-session level retention optimization task. For each task, KuaiSim also provides evaluation protocols and baseline recommendation algorithms that further serve as benchmarks for future research. We also restructure existing competitive simulators on the KuaiRand Dataset and compare them against KuaiSim to future assess their performance and behavioral differences. Furthermore, to showcase KuaiSim's flexibility in accommodating different datasets, we demonstrate its versatility and robustness when deploying it on the ML-1m dataset.
AutoAssign+: Automatic Shared Embedding Assignment in Streaming Recommendation
Aug 14, 2023In the domain of streaming recommender systems, conventional methods for addressing new user IDs or item IDs typically involve assigning initial ID embeddings randomly. However, this practice results in two practical challenges: (i) Items or users with limited interactive data may yield suboptimal prediction performance. (ii) Embedding new IDs or low-frequency IDs necessitates consistently expanding the embedding table, leading to unnecessary memory consumption. In light of these concerns, we introduce a reinforcement learning-driven framework, namely AutoAssign+, that facilitates Automatic Shared Embedding Assignment Plus. To be specific, AutoAssign+ utilizes an Identity Agent as an actor network, which plays a dual role: (i) Representing low-frequency IDs field-wise with a small set of shared embeddings to enhance the embedding initialization, and (ii) Dynamically determining which ID features should be retained or eliminated in the embedding table. The policy of the agent is optimized with the guidance of a critic network. To evaluate the effectiveness of our approach, we perform extensive experiments on three commonly used benchmark datasets. Our experiment results demonstrate that AutoAssign+ is capable of significantly enhancing recommendation performance by mitigating the cold-start problem. Furthermore, our framework yields a reduction in memory usage of approximately 20-30%, verifying its practical effectiveness and efficiency for streaming recommender systems.
Learning Empirical Bregman Divergence for Uncertain Distance Representation
Apr 18, 2023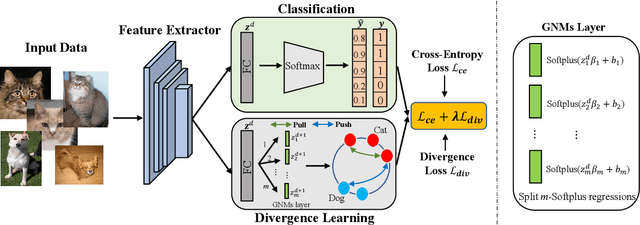
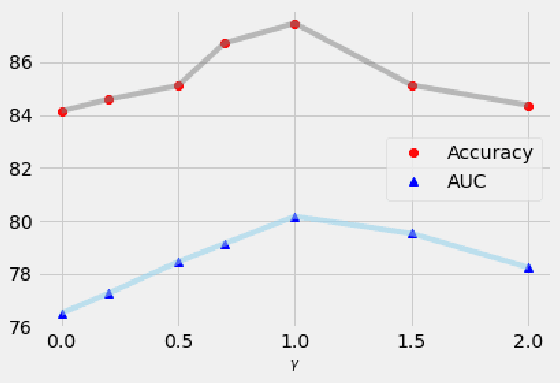
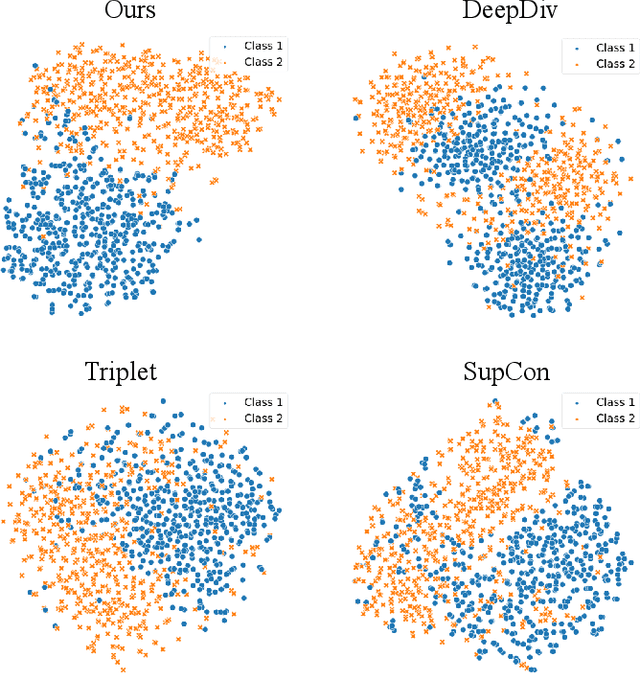

Deep metric learning techniques have been used for visual representation in various supervised and unsupervised learning tasks through learning embeddings of samples with deep networks. However, classic approaches, which employ a fixed distance metric as a similarity function between two embeddings, may lead to suboptimal performance for capturing the complex data distribution. The Bregman divergence generalizes measures of various distance metrics and arises throughout many fields of deep metric learning. In this paper, we first show how deep metric learning loss can arise from the Bregman divergence. We then introduce a novel method for learning empirical Bregman divergence directly from data based on parameterizing the convex function underlying the Bregman divergence with a deep learning setting. We further experimentally show that our approach performs effectively on five popular public datasets compared to other SOTA deep metric learning methods, particularly for pattern recognition problems.