 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Optimal Token Baseline: Variance Reduction for Long-Horizon LLM-RL
Feb 06, 2026Reinforcement Learning (RL) for Large Language Models (LLMs) often suffers from training collapse in long-horizon tasks due to exploding gradient variance. To mitigate this, a baseline is commonly introduced for advantage computation; however, traditional value models remain difficult to optimize, and standard group-based baselines overlook sequence heterogeneity. Although classic optimal baseline theory can achieve global variance reduction, it neglects token heterogeneity and requires prohibitive gradient-based computation. In this work, we derive the Optimal Token Baseline (OTB) from first principles, proving that gradient updates should be weighted inversely to their cumulative gradient norm. To ensure efficiency, we propose the Logit-Gradient Proxy that approximates the gradient norm using only forward-pass probabilities. Our method achieves training stability and matches the performance of large group sizes ($N=32$) with only $N=4$, reducing token consumption by over 65% across single-turn and tool-integrated reasoning tasks.
Group-in-Group Policy Optimization for LLM Agent Training
May 16, 2025Recent advances in group-based reinforcement learning (RL) have driven frontier large language models (LLMs) in single-turn tasks like mathematical reasoning. However, their scalability to long-horizon LLM agent training remains limited. Unlike static tasks, agent-environment interactions unfold over many steps and often yield sparse or delayed rewards, making credit assignment across individual steps significantly more challenging. In this work, we propose Group-in-Group Policy Optimization (GiGPO), a novel RL algorithm that achieves fine-grained credit assignment for LLM agents while preserving the appealing properties of group-based RL: critic-free, low memory, and stable convergence. GiGPO introduces a two-level structure for estimating relative advantage: (i) At the episode-level, GiGPO computes macro relative advantages based on groups of complete trajectories; (ii) At the step-level, GiGPO introduces an anchor state grouping mechanism that retroactively constructs step-level groups by identifying repeated environment states across trajectories. Actions stemming from the same state are grouped together, enabling micro relative advantage estimation. This hierarchical structure effectively captures both global trajectory quality and local step effectiveness without relying on auxiliary models or additional rollouts. We evaluate GiGPO on two challenging agent benchmarks, ALFWorld and WebShop, using Qwen2.5-1.5B-Instruct and Qwen2.5-7B-Instruct. Crucially, GiGPO delivers fine-grained per-step credit signals and achieves performance gains of > 12\% on ALFWorld and > 9\% on WebShop over the GRPO baseline: all while maintaining the same GPU memory overhead, identical LLM rollout, and incurring little to no additional time cost.
Policy Regularization on Globally Accessible States in Cross-Dynamics Reinforcement Learning
Mar 10, 2025To learn from data collected in diverse dynamics, Imitation from Observation (IfO) methods leverage expert state trajectories based on the premise that recovering expert state distributions in other dynamics facilitates policy learning in the current one. However, Imitation Learning inherently imposes a performance upper bound of learned policies. Additionally, as the environment dynamics change, certain expert states may become inaccessible, rendering their distributions less valuable for imitation. To address this, we propose a novel framework that integrates reward maximization with IfO, employing F-distance regularized policy optimization. This framework enforces constraints on globally accessible states--those with nonzero visitation frequency across all considered dynamics--mitigating the challenge posed by inaccessible states. By instantiating F-distance in different ways, we derive two theoretical analysis and develop a practical algorithm called Accessible State Oriented Policy Regularization (ASOR). ASOR serves as a general add-on module that can be incorporated into various RL approaches, including offline RL and off-policy RL. Extensive experiments across multiple benchmarks demonstrate ASOR's effectiveness in enhancing state-of-the-art cross-domain policy transfer algorithms, significantly improving their performance.
Modeling User Retention through Generative Flow Networks
Jun 10, 2024



Recommender systems aim to fulfill the user's daily demands. While most existing research focuses on maximizing the user's engagement with the system, it has recently been pointed out that how frequently the users come back for the service also reflects the quality and stability of recommendations. However, optimizing this user retention behavior is non-trivial and poses several challenges including the intractable leave-and-return user activities, the sparse and delayed signal, and the uncertain relations between users' retention and their immediate feedback towards each item in the recommendation list. In this work, we regard the retention signal as an overall estimation of the user's end-of-session satisfaction and propose to estimate this signal through a probabilistic flow. This flow-based modeling technique can back-propagate the retention reward towards each recommended item in the user session, and we show that the flow combined with traditional learning-to-rank objectives eventually optimizes a non-discounted cumulative reward for both immediate user feedback and user retention. We verify the effectiveness of our method through both offline empirical studies on two public datasets and online A/B tests in an industrial platform.
S$^2$AC: Energy-Based Reinforcement Learning with Stein Soft Actor Critic
May 02, 2024Learning expressive stochastic policies instead of deterministic ones has been proposed to achieve better stability, sample complexity, and robustness. Notably, in Maximum Entropy Reinforcement Learning (MaxEnt RL), the policy is modeled as an expressive Energy-Based Model (EBM) over the Q-values. However, this formulation requires the estimation of the entropy of such EBMs, which is an open problem. To address this, previous MaxEnt RL methods either implicitly estimate the entropy, resulting in high computational complexity and variance (SQL), or follow a variational inference procedure that fits simplified actor distributions (e.g., Gaussian) for tractability (SAC). We propose Stein Soft Actor-Critic (S$^2$AC), a MaxEnt RL algorithm that learns expressive policies without compromising efficiency. Specifically, S$^2$AC uses parameterized Stein Variational Gradient Descent (SVGD) as the underlying policy. We derive a closed-form expression of the entropy of such policies. Our formula is computationally efficient and only depends on first-order derivatives and vector products. Empirical results show that S$^2$AC yields more optimal solutions to the MaxEnt objective than SQL and SAC in the multi-goal environment, and outperforms SAC and SQL on the MuJoCo benchmark. Our code is available at: https://github.com/SafaMessaoud/S2AC-Energy-Based-RL-with-Stein-Soft-Actor-Critic
AgentStudio: A Toolkit for Building General Virtual Agents
Mar 26, 2024Creating autonomous virtual agents capable of using arbitrary software on any digital device remains a major challenge for artificial intelligence. Two key obstacles hinder progress: insufficient infrastructure for building virtual agents in real-world environments, and the need for in-the-wild evaluation of fundamental agent abilities. To address this, we introduce AgentStudio, an online, realistic, and multimodal toolkit that covers the entire lifecycle of agent development. This includes environment setups, data collection, agent evaluation, and visualization. The observation and action spaces are highly generic, supporting both function calling and human-computer interfaces. This versatility is further enhanced by AgentStudio's graphical user interfaces, which allow efficient development of datasets and benchmarks in real-world settings. To illustrate, we introduce a visual grounding dataset and a real-world benchmark suite, both created with our graphical interfaces. Furthermore, we present several actionable insights derived from AgentStudio, e.g., general visual grounding, open-ended tool creation, learning from videos, etc. We have open-sourced the environments, datasets, benchmarks, and interfaces to promote research towards developing general virtual agents for the future.
AdaRec: Adaptive Sequential Recommendation for Reinforcing Long-term User Engagement
Oct 06, 2023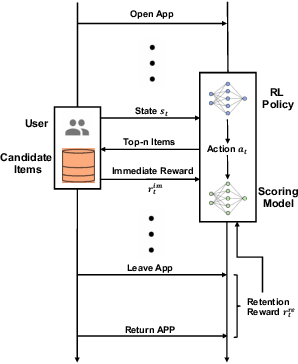
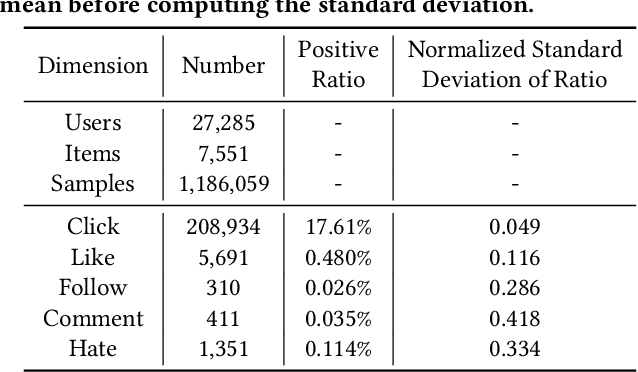
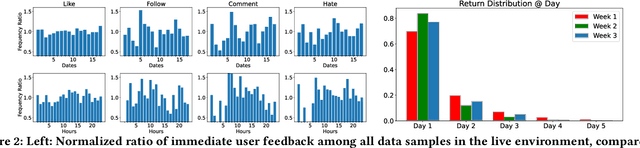
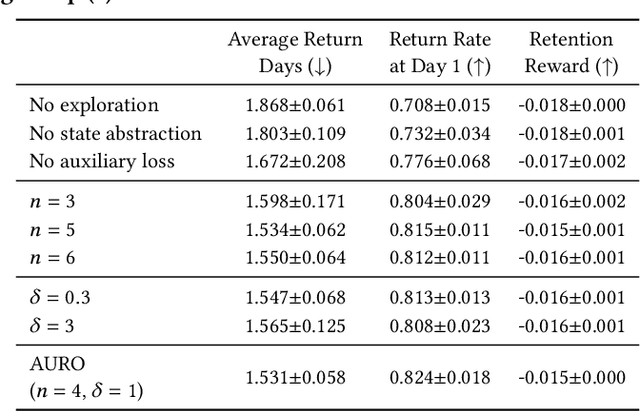
Growing attention has been paid to Reinforcement Learning (RL) algorithms when optimizing long-term user engagement in sequential recommendation tasks. One challenge in large-scale online recommendation systems is the constant and complicated changes in users' behavior patterns, such as interaction rates and retention tendencies. When formulated as a Markov Decision Process (MDP), the dynamics and reward functions of the recommendation system are continuously affected by these changes. Existing RL algorithms for recommendation systems will suffer from distribution shift and struggle to adapt in such an MDP. In this paper, we introduce a novel paradigm called Adaptive Sequential Recommendation (AdaRec) to address this issue. AdaRec proposes a new distance-based representation loss to extract latent information from users' interaction trajectories. Such information reflects how RL policy fits to current user behavior patterns, and helps the policy to identify subtle changes in the recommendation system. To make rapid adaptation to these changes, AdaRec encourages exploration with the idea of optimism under uncertainty. The exploration is further guarded by zero-order action optimization to ensure stable recommendation quality in complicated environments. We conduct extensive empirical analyses in both simulator-based and live sequential recommendation tasks, where AdaRec exhibits superior long-term performance compared to all baseline algorithms.
A Large Language Model Enhanced Conversational Recommender System
Aug 11, 2023Conversational recommender systems (CRSs) aim to recommend high-quality items to users through a dialogue interface. It usually contains multiple sub-tasks, such as user preference elicitation, recommendation, explanation, and item information search. To develop effective CRSs, there are some challenges: 1) how to properly manage sub-tasks; 2) how to effectively solve different sub-tasks; and 3) how to correctly generate responses that interact with users. Recently, Large Language Models (LLMs) have exhibited an unprecedented ability to reason and generate, presenting a new opportunity to develop more powerful CRSs. In this work, we propose a new LLM-based CRS, referred to as LLMCRS, to address the above challenges. For sub-task management, we leverage the reasoning ability of LLM to effectively manage sub-task. For sub-task solving, we collaborate LLM with expert models of different sub-tasks to achieve the enhanced performance. For response generation, we utilize the generation ability of LLM as a language interface to better interact with users. Specifically, LLMCRS divides the workflow into four stages: sub-task detection, model matching, sub-task execution, and response generation. LLMCRS also designs schema-based instruction, demonstration-based instruction, dynamic sub-task and model matching, and summary-based generation to instruct LLM to generate desired results in the workflow. Finally, to adapt LLM to conversational recommendations, we also propose to fine-tune LLM with reinforcement learning from CRSs performance feedback, referred to as RLPF. Experimental results on benchmark datasets show that LLMCRS with RLPF outperforms the existing methods.
State Regularized Policy Optimization on Data with Dynamics Shift
Jun 06, 2023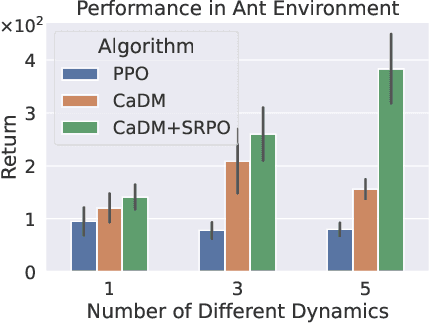
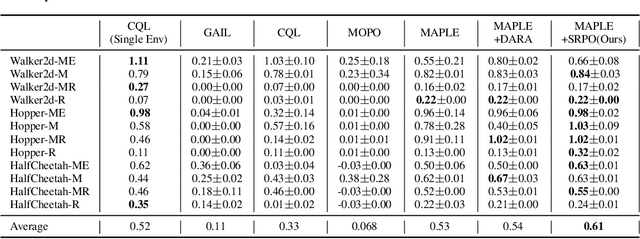
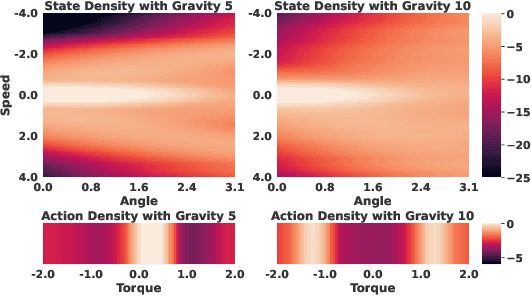
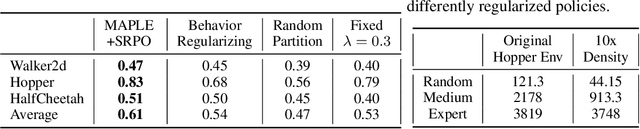
In many real-world scenarios, Reinforcement Learning (RL) algorithms are trained on data with dynamics shift, i.e., with different underlying environment dynamics. A majority of current methods address such issue by training context encoders to identify environment parameters. Data with dynamics shift are separated according to their environment parameters to train the corresponding policy. However, these methods can be sample inefficient as data are used \textit{ad hoc}, and policies trained for one dynamics cannot benefit from data collected in all other environments with different dynamics. In this paper, we find that in many environments with similar structures and different dynamics, optimal policies have similar stationary state distributions. We exploit such property and learn the stationary state distribution from data with dynamics shift for efficient data reuse. Such distribution is used to regularize the policy trained in a new environment, leading to the SRPO (\textbf{S}tate \textbf{R}egularized \textbf{P}olicy \textbf{O}ptimization) algorithm. To conduct theoretical analyses, the intuition of similar environment structures is characterized by the notion of homomorphous MDPs. We then demonstrate a lower-bound performance guarantee on policies regularized by the stationary state distribution. In practice, SRPO can be an add-on module to context-based algorithms in both online and offline RL settings. Experimental results show that SRPO can make several context-based algorithms far more data efficient and significantly improve their overall performance.
Guarded Policy Optimization with Imperfect Online Demonstrations
Mar 03, 2023The Teacher-Student Framework (TSF) is a reinforcement learning setting where a teacher agent guards the training of a student agent by intervening and providing online demonstrations. Assuming optimal, the teacher policy has the perfect timing and capability to intervene in the learning process of the student agent, providing safety guarantee and exploration guidance. Nevertheless, in many real-world settings it is expensive or even impossible to obtain a well-performing teacher policy. In this work, we relax the assumption of a well-performing teacher and develop a new method that can incorporate arbitrary teacher policies with modest or inferior performance. We instantiate an Off-Policy Reinforcement Learning algorithm, termed Teacher-Student Shared Control (TS2C), which incorporates teacher intervention based on trajectory-based value estimation. Theoretical analysis validates that the proposed TS2C algorithm attains efficient exploration and substantial safety guarantee without being affected by the teacher's own performance. Experiments on various continuous control tasks show that our method can exploit teacher policies at different performance levels while maintaining a low training cost. Moreover, the student policy surpasses the imperfect teacher policy in terms of higher accumulated reward in held-out testing environments. Code is available at https://metadriverse.github.io/TS2C.