 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeState Regularized Policy Optimization on Data with Dynamics Shift
Paper and Code
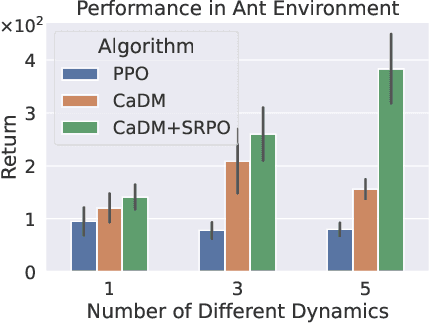
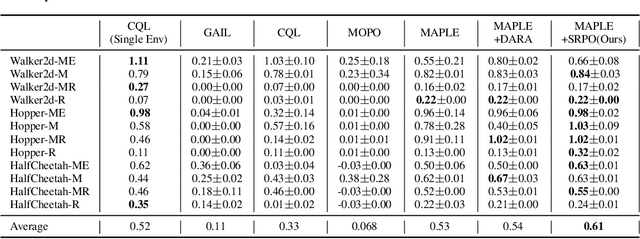
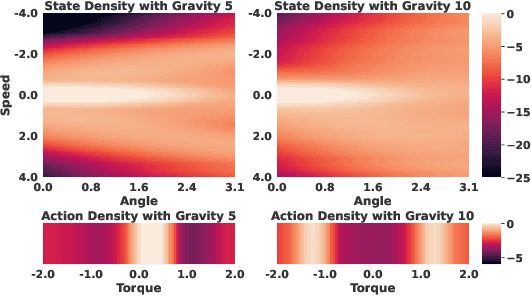
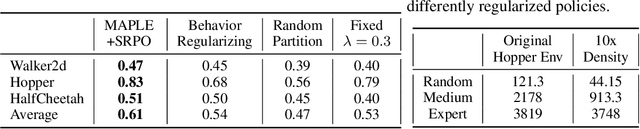
In many real-world scenarios, Reinforcement Learning (RL) algorithms are trained on data with dynamics shift, i.e., with different underlying environment dynamics. A majority of current methods address such issue by training context encoders to identify environment parameters. Data with dynamics shift are separated according to their environment parameters to train the corresponding policy. However, these methods can be sample inefficient as data are used \textit{ad hoc}, and policies trained for one dynamics cannot benefit from data collected in all other environments with different dynamics. In this paper, we find that in many environments with similar structures and different dynamics, optimal policies have similar stationary state distributions. We exploit such property and learn the stationary state distribution from data with dynamics shift for efficient data reuse. Such distribution is used to regularize the policy trained in a new environment, leading to the SRPO (\textbf{S}tate \textbf{R}egularized \textbf{P}olicy \textbf{O}ptimization) algorithm. To conduct theoretical analyses, the intuition of similar environment structures is characterized by the notion of homomorphous MDPs. We then demonstrate a lower-bound performance guarantee on policies regularized by the stationary state distribution. In practice, SRPO can be an add-on module to context-based algorithms in both online and offline RL settings. Experimental results show that SRPO can make several context-based algorithms far more data efficient and significantly improve their overall performance.