 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALTo: Adaptive-Length Tokenizer for Autoregressive Mask Generation
May 22, 2025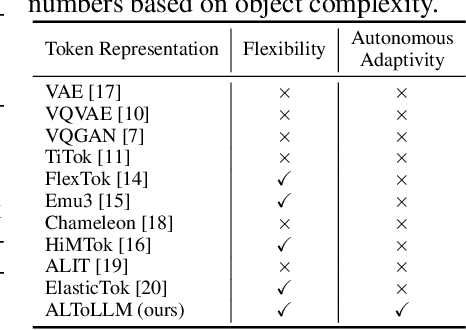
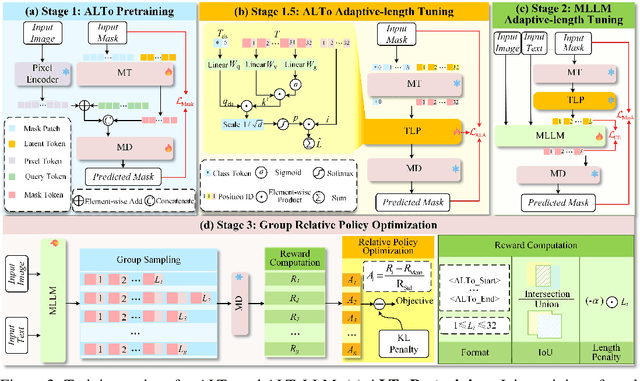
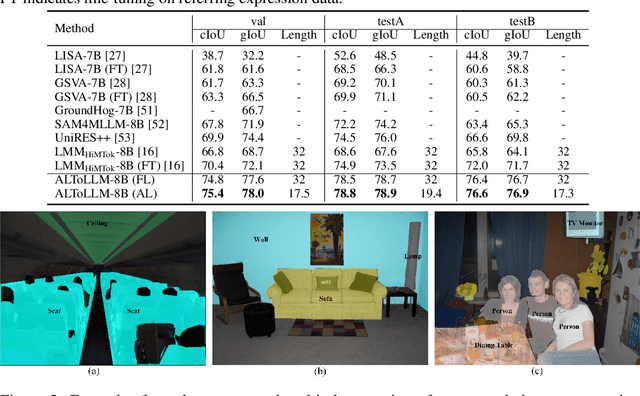
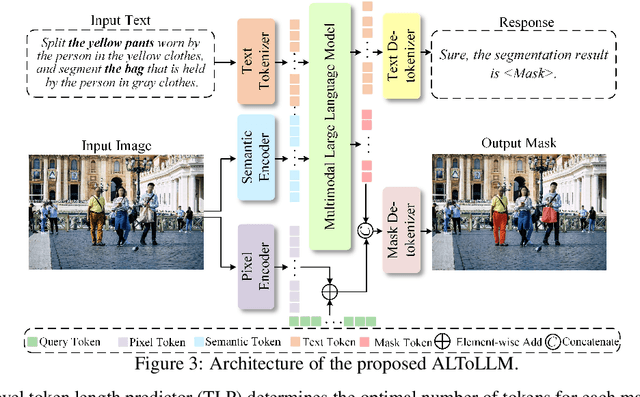
While humans effortlessly draw visual objects and shapes by adaptively allocating attention based on their complexity, existing multimodal large language models (MLLMs) remain constrained by rigid token representations. Bridging this gap, we propose ALTo, an adaptive length tokenizer for autoregressive mask generation. To achieve this, a novel token length predictor is designed, along with a length regularization term and a differentiable token chunking strategy. We further build ALToLLM that seamlessly integrates ALTo into MLLM. Preferences on the trade-offs between mask quality and efficiency is implemented by group relative policy optimization (GRPO). Experiments demonstrate that ALToLLM achieves state-of-the-art performance with adaptive token cost on popular segmentation benchmarks. Code and models are released at https://github.com/yayafengzi/ALToLLM.
WanJuanSiLu: A High-Quality Open-Source Webtext Dataset for Low-Resource Languages
Jan 24, 2025



This paper introduces the open-source dataset WanJuanSiLu, designed to provide high-quality training corpora for low-resource languages, thereby advancing the research and development of multilingual models. To achieve this, we have developed a systematic data processing framework tailored for low-resource languages. This framework encompasses key stages such as data extraction, corpus cleaning, content deduplication, security filtering, quality evaluation, and theme classification. Through the implementation of this framework, we have significantly improved both the quality and security of the dataset, while maintaining its linguistic diversity. As of now, data for all five languages have been fully open-sourced. The dataset can be accessed at https://opendatalab.com/applyMultilingualCorpus, and GitHub repository is available at https://github.com/opendatalab/WanJuan3.0
Event-Customized Image Generation
Oct 03, 2024
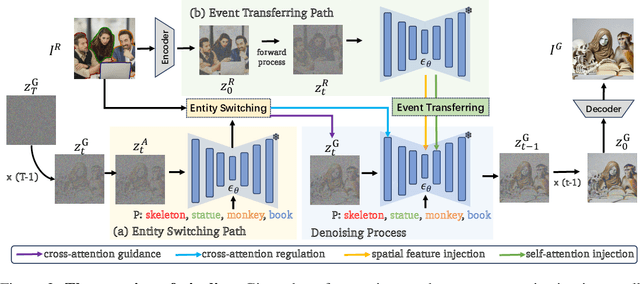


Customized Image Generation, generating customized images with user-specified concepts, has raised significant attention due to its creativity and novelty. With impressive progress achieved in subject customization, some pioneer works further explored the customization of action and interaction beyond entity (i.e., human, animal, and object) appearance. However, these approaches only focus on basic actions and interactions between two entities, and their effects are limited by insufficient ''exactly same'' reference images. To extend customized image generation to more complex scenes for general real-world applications, we propose a new task: event-customized image generation. Given a single reference image, we define the ''event'' as all specific actions, poses, relations, or interactions between different entities in the scene. This task aims at accurately capturing the complex event and generating customized images with various target entities. To solve this task, we proposed a novel training-free event customization method: FreeEvent. Specifically, FreeEvent introduces two extra paths alongside the general diffusion denoising process: 1) Entity switching path: it applies cross-attention guidance and regulation for target entity generation. 2) Event transferring path: it injects the spatial feature and self-attention maps from the reference image to the target image for event generation. To further facilitate this new task, we collected two evaluation benchmarks: SWiG-Event and Real-Event. Extensive experiments and ablations have demonstrated the effectiveness of FreeEvent.
KuaiSim: A Comprehensive Simulator for Recommender Systems
Sep 22, 2023



Reinforcement Learning (RL)-based recommender systems (RSs) have garnered considerable attention due to their ability to learn optimal recommendation policies and maximize long-term user rewards. However, deploying RL models directly in online environments and generating authentic data through A/B tests can pose challenges and require substantial resources. Simulators offer an alternative approach by providing training and evaluation environments for RS models, reducing reliance on real-world data. Existing simulators have shown promising results but also have limitations such as simplified user feedback, lacking consistency with real-world data, the challenge of simulator evaluation, and difficulties in migration and expansion across RSs. To address these challenges, we propose KuaiSim, a comprehensive user environment that provides user feedback with multi-behavior and cross-session responses. The resulting simulator can support three levels of recommendation problems: the request level list-wise recommendation task, the whole-session level sequential recommendation task, and the cross-session level retention optimization task. For each task, KuaiSim also provides evaluation protocols and baseline recommendation algorithms that further serve as benchmarks for future research. We also restructure existing competitive simulators on the KuaiRand Dataset and compare them against KuaiSim to future assess their performance and behavioral differences. Furthermore, to showcase KuaiSim's flexibility in accommodating different datasets, we demonstrate its versatility and robustness when deploying it on the ML-1m dataset.
Generative Flow Network for Listwise Recommendation
Jun 09, 2023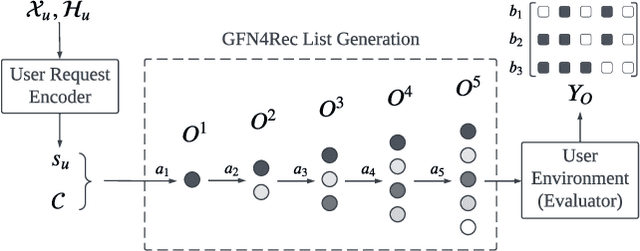

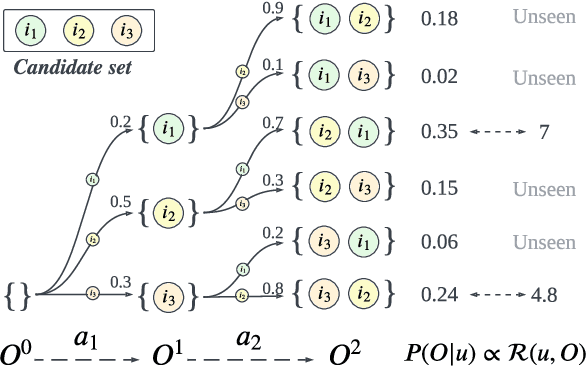
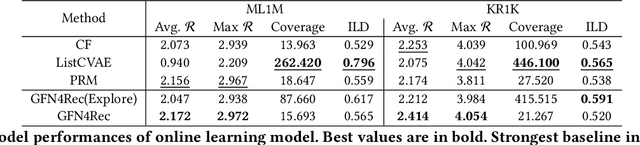
Personalized recommender systems fulfill the daily demands of customers and boost online businesses. The goal is to learn a policy that can generate a list of items that matches the user's demand or interest. While most existing methods learn a pointwise scoring model that predicts the ranking score of each individual item, recent research shows that the listwise approach can further improve the recommendation quality by modeling the intra-list correlations of items that are exposed together. This has motivated the recent list reranking and generative recommendation approaches that optimize the overall utility of the entire list. However, it is challenging to explore the combinatorial space of list actions and existing methods that use cross-entropy loss may suffer from low diversity issues. In this work, we aim to learn a policy that can generate sufficiently diverse item lists for users while maintaining high recommendation quality. The proposed solution, GFN4Rec, is a generative method that takes the insight of the flow network to ensure the alignment between list generation probability and its reward. The key advantages of our solution are the log scale reward matching loss that intrinsically improves the generation diversity and the autoregressive item selection model that captures the item mutual influences while capturing future reward of the list. As validation of our method's effectiveness and its superior diversity during active exploration, we conduct experiments on simulated online environments as well as an offline evaluation framework for two real-world datasets.
* 11 pages, 5 figures, 7 tables
State Regularized Policy Optimization on Data with Dynamics Shift
Jun 06, 2023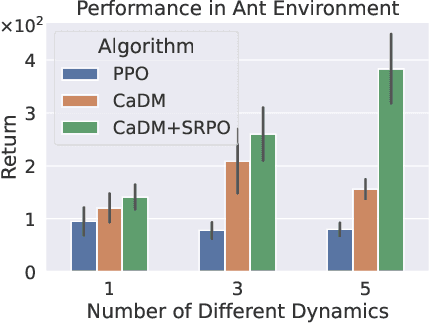
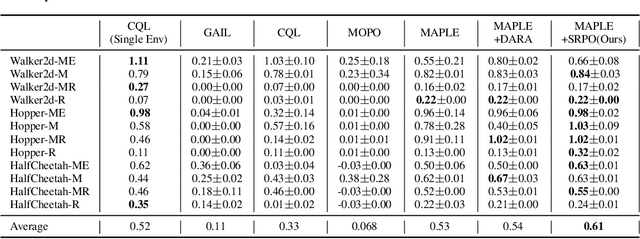
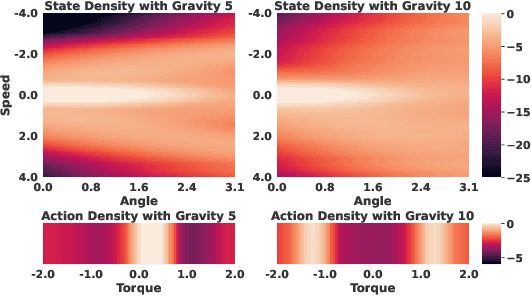
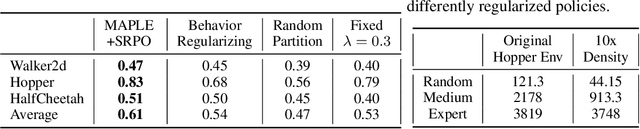
In many real-world scenarios, Reinforcement Learning (RL) algorithms are trained on data with dynamics shift, i.e., with different underlying environment dynamics. A majority of current methods address such issue by training context encoders to identify environment parameters. Data with dynamics shift are separated according to their environment parameters to train the corresponding policy. However, these methods can be sample inefficient as data are used \textit{ad hoc}, and policies trained for one dynamics cannot benefit from data collected in all other environments with different dynamics. In this paper, we find that in many environments with similar structures and different dynamics, optimal policies have similar stationary state distributions. We exploit such property and learn the stationary state distribution from data with dynamics shift for efficient data reuse. Such distribution is used to regularize the policy trained in a new environment, leading to the SRPO (\textbf{S}tate \textbf{R}egularized \textbf{P}olicy \textbf{O}ptimization) algorithm. To conduct theoretical analyses, the intuition of similar environment structures is characterized by the notion of homomorphous MDPs. We then demonstrate a lower-bound performance guarantee on policies regularized by the stationary state distribution. In practice, SRPO can be an add-on module to context-based algorithms in both online and offline RL settings. Experimental results show that SRPO can make several context-based algorithms far more data efficient and significantly improve their overall performance.
Reinforcing User Retention in a Billion Scale Short Video Recommender System
Feb 12, 2023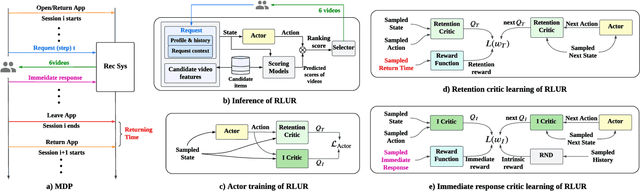
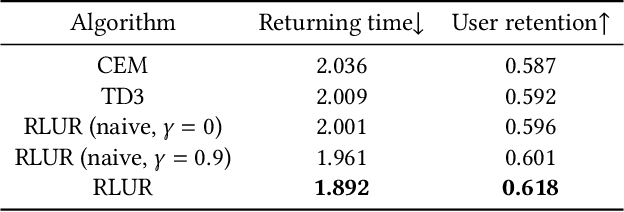
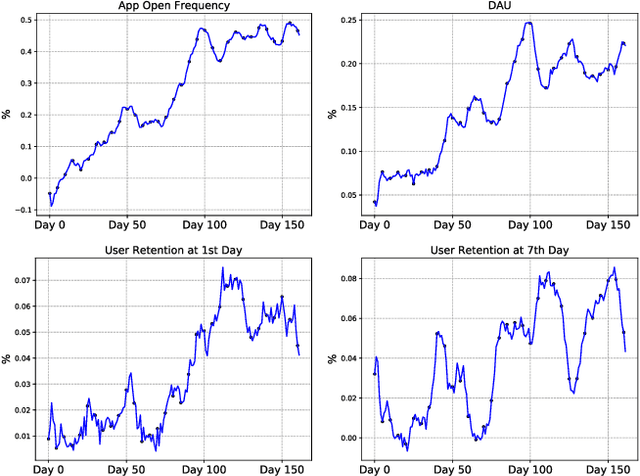
Recently, short video platforms have achieved rapid user growth by recommending interesting content to users. The objective of the recommendation is to optimize user retention, thereby driving the growth of DAU (Daily Active Users). Retention is a long-term feedback after multiple interactions of users and the system, and it is hard to decompose retention reward to each item or a list of items. Thus traditional point-wise and list-wise models are not able to optimize retention. In this paper, we choose reinforcement learning methods to optimize the retention as they are designed to maximize the long-term performance. We formulate the problem as an infinite-horizon request-based Markov Decision Process, and our objective is to minimize the accumulated time interval of multiple sessions, which is equal to improving the app open frequency and user retention. However, current reinforcement learning algorithms can not be directly applied in this setting due to uncertainty, bias, and long delay time incurred by the properties of user retention. We propose a novel method, dubbed RLUR, to address the aforementioned challenges. Both offline and live experiments show that RLUR can significantly improve user retention. RLUR has been fully launched in Kuaishou app for a long time, and achieves consistent performance improvement on user retention and DAU.
Exploration and Regularization of the Latent Action Space in Recommendation
Feb 08, 2023



In recommender systems, reinforcement learning solutions have effectively boosted recommendation performance because of their ability to capture long-term user-system interaction. However, the action space of the recommendation policy is a list of items, which could be extremely large with a dynamic candidate item pool. To overcome this challenge, we propose a hyper-actor and critic learning framework where the policy decomposes the item list generation process into a hyper-action inference step and an effect-action selection step. The first step maps the given state space into a vectorized hyper-action space, and the second step selects the item list based on the hyper-action. In order to regulate the discrepancy between the two action spaces, we design an alignment module along with a kernel mapping function for items to ensure inference accuracy and include a supervision module to stabilize the learning process. We build simulated environments on public datasets and empirically show that our framework is superior in recommendation compared to standard RL baselines.
Multi-Task Recommendations with Reinforcement Learning
Feb 07, 2023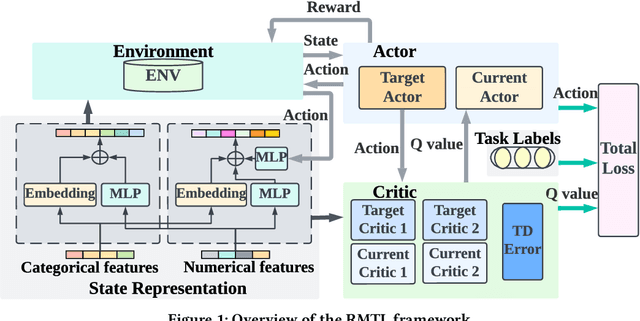
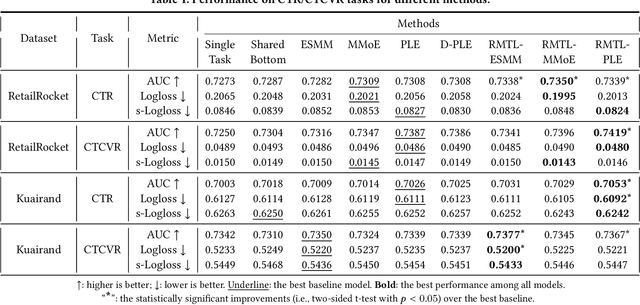
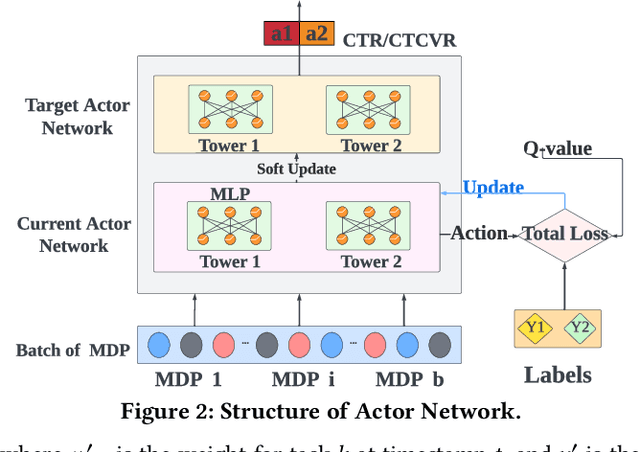
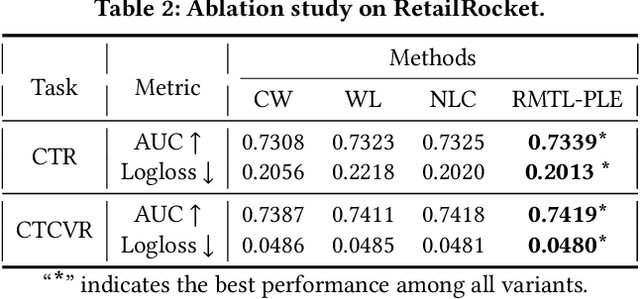
In recent years, Multi-task Learning (MTL) has yielded immense success in Recommender System (RS) applications. However, current MTL-based recommendation models tend to disregard the session-wise patterns of user-item interactions because they are predominantly constructed based on item-wise datasets. Moreover, balancing multiple objectives has always been a challenge in this field, which is typically avoided via linear estimations in existing works. To address these issues, in this paper, we propose a Reinforcement Learning (RL) enhanced MTL framework, namely RMTL, to combine the losses of different recommendation tasks using dynamic weights. To be specific, the RMTL structure can address the two aforementioned issues by (i) constructing an MTL environment from session-wise interactions and (ii) training multi-task actor-critic network structure, which is compatible with most existing MTL-based recommendation models, and (iii) optimizing and fine-tuning the MTL loss function using the weights generated by critic networks. Experiments on two real-world public datasets demonstrate the effectiveness of RMTL with a higher AUC against state-of-the-art MTL-based recommendation models. Additionally, we evaluate and validate RMTL's compatibility and transferability across various MTL models.
Two-Stage Constrained Actor-Critic for Short Video Recommendation
Feb 06, 2023
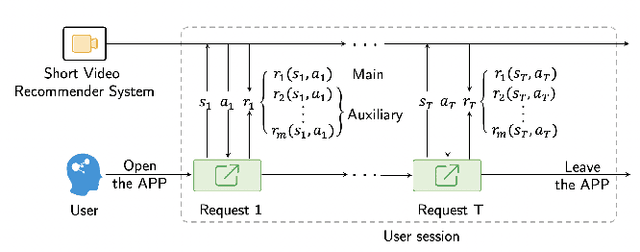
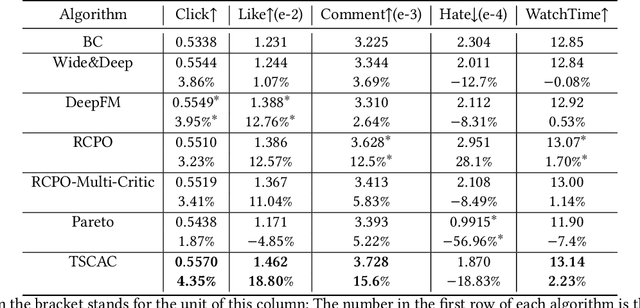
The wide popularity of short videos on social media poses new opportunities and challenges to optimize recommender systems on the video-sharing platforms. Users sequentially interact with the system and provide complex and multi-faceted responses, including watch time and various types of interactions with multiple videos. One the one hand, the platforms aims at optimizing the users' cumulative watch time (main goal) in long term, which can be effectively optimized by Reinforcement Learning. On the other hand, the platforms also needs to satisfy the constraint of accommodating the responses of multiple user interactions (auxiliary goals) such like, follow, share etc. In this paper, we formulate the problem of short video recommendation as a Constrained Markov Decision Process (CMDP). We find that traditional constrained reinforcement learning algorithms can not work well in this setting. We propose a novel two-stage constrained actor-critic method: At stage one, we learn individual policies to optimize each auxiliary signal. At stage two, we learn a policy to (i) optimize the main signal and (ii) stay close to policies learned at the first stage, which effectively guarantees the performance of this main policy on the auxiliaries. Through extensive offline evaluations, we demonstrate effectiveness of our method over alternatives in both optimizing the main goal as well as balancing the others. We further show the advantage of our method in live experiments of short video recommendations, where it significantly outperforms other baselines in terms of both watch time and interactions. Our approach has been fully launched in the production system to optimize user experiences on the platform.
* arXiv admin note: substantial text overlap with arXiv:2205.13248