 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbodiedBrain: Expanding Performance Boundaries of Task Planning for Embodied Intelligence
Oct 23, 2025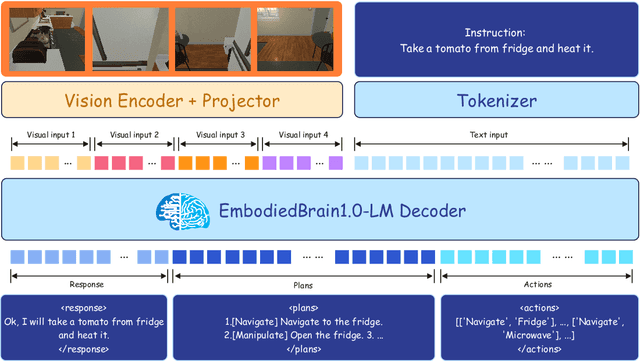
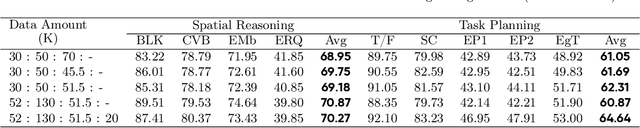

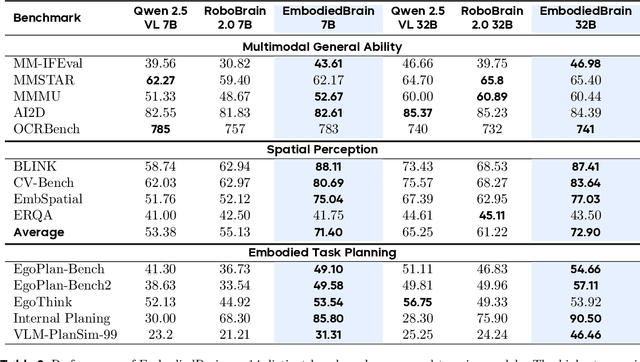
The realization of Artificial General Intelligence (AGI) necessitates Embodied AI agents capable of robust spatial perception, effective task planning, and adaptive execution in physical environments. However, current large language models (LLMs) and multimodal LLMs (MLLMs) for embodied tasks suffer from key limitations, including a significant gap between model design and agent requirements, an unavoidable trade-off between real-time latency and performance, and the use of unauthentic, offline evaluation metrics. To address these challenges, we propose EmbodiedBrain, a novel vision-language foundation model available in both 7B and 32B parameter sizes. Our framework features an agent-aligned data structure and employs a powerful training methodology that integrates large-scale Supervised Fine-Tuning (SFT) with Step-Augumented Group Relative Policy Optimization (Step-GRPO), which boosts long-horizon task success by integrating preceding steps as Guided Precursors. Furthermore, we incorporate a comprehensive reward system, including a Generative Reward Model (GRM) accelerated at the infrastructure level, to improve training efficiency. For enable thorough validation, we establish a three-part evaluation system encompassing General, Planning, and End-to-End Simulation Benchmarks, highlighted by the proposal and open-sourcing of a novel, challenging simulation environment. Experimental results demonstrate that EmbodiedBrain achieves superior performance across all metrics, establishing a new state-of-the-art for embodied foundation models. Towards paving the way for the next generation of generalist embodied agents, we open-source all of our data, model weight, and evaluating methods, which are available at https://zterobot.github.io/EmbodiedBrain.github.io.
ALTo: Adaptive-Length Tokenizer for Autoregressive Mask Generation
May 22, 2025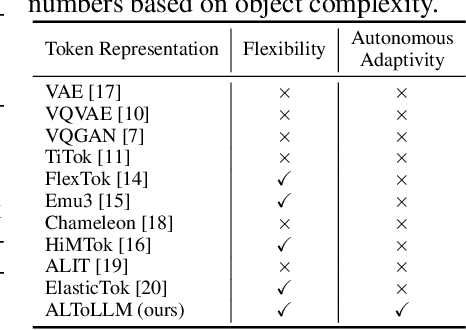
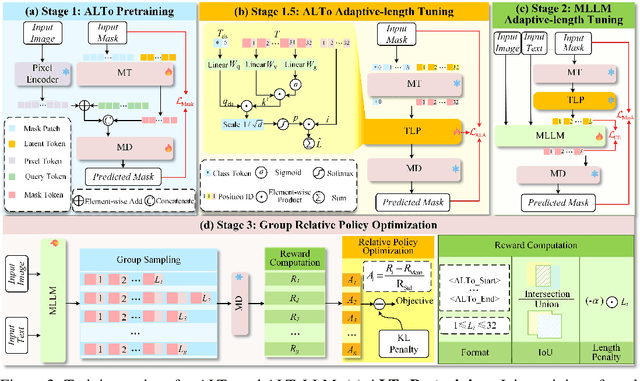
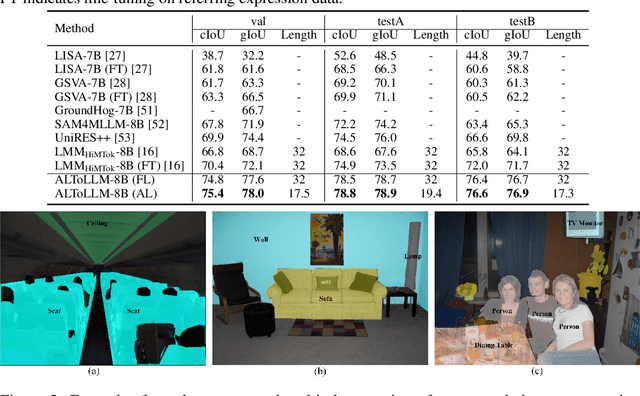
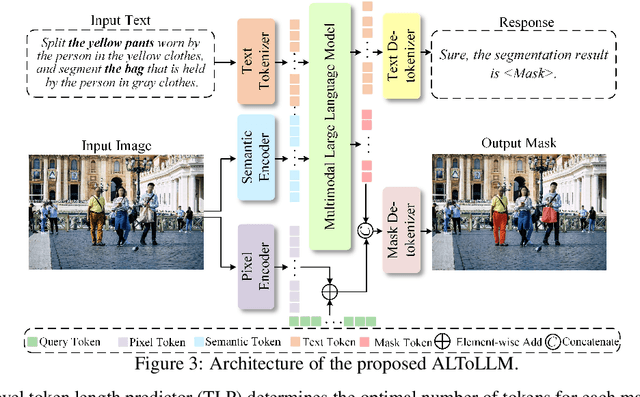
While humans effortlessly draw visual objects and shapes by adaptively allocating attention based on their complexity, existing multimodal large language models (MLLMs) remain constrained by rigid token representations. Bridging this gap, we propose ALTo, an adaptive length tokenizer for autoregressive mask generation. To achieve this, a novel token length predictor is designed, along with a length regularization term and a differentiable token chunking strategy. We further build ALToLLM that seamlessly integrates ALTo into MLLM. Preferences on the trade-offs between mask quality and efficiency is implemented by group relative policy optimization (GRPO). Experiments demonstrate that ALToLLM achieves state-of-the-art performance with adaptive token cost on popular segmentation benchmarks. Code and models are released at https://github.com/yayafengzi/ALToLLM.
HiMTok: Learning Hierarchical Mask Tokens for Image Segmentation with Large Multimodal Model
Mar 17, 2025



The remarkable performance of large multimodal models (LMMs) has attracted significant interest from the image segmentation community. To align with the next-token-prediction paradigm, current LMM-driven segmentation methods either use object boundary points to represent masks or introduce special segmentation tokens, whose hidden states are decoded by a segmentation model requiring the original image as input. However, these approaches often suffer from inadequate mask representation and complex architectures, limiting the potential of LMMs. In this work, we propose the Hierarchical Mask Tokenizer (HiMTok), which represents segmentation masks with up to 32 tokens and eliminates the need for the original image during mask de-tokenization. HiMTok allows for compact and coarse-to-fine mask representations, aligning well with the LLM next-token-prediction paradigm and facilitating the direct acquisition of segmentation capabilities. We develop a 3-stage training recipe for progressive learning of segmentation and visual capabilities, featuring a hierarchical mask loss for effective coarse-to-fine learning. Additionally, we enable bidirectional information flow, allowing conversion between bounding boxes and mask tokens to fully leverage multi-task training potential. Extensive experiments demonstrate that our method achieves state-of-the-art performance across various segmentation tasks,while also enhancing visual grounding and maintaining overall visual understanding.
Technique Report of CVPR 2024 PBDL Challenges
Jun 15, 2024



The intersection of physics-based vision and deep learning presents an exciting frontier for advancing computer vision technologies. By leveraging the principles of physics to inform and enhance deep learning models, we can develop more robust and accurate vision systems. Physics-based vision aims to invert the processes to recover scene properties such as shape, reflectance, light distribution, and medium properties from images. In recent years, deep learning has shown promising improvements for various vision tasks, and when combined with physics-based vision, these approaches can enhance the robustness and accuracy of vision systems. This technical report summarizes the outcomes of the Physics-Based Vision Meets Deep Learning (PBDL) 2024 challenge, held in CVPR 2024 workshop. The challenge consisted of eight tracks, focusing on Low-Light Enhancement and Detection as well as High Dynamic Range (HDR) Imaging. This report details the objectives, methodologies, and results of each track, highlighting the top-performing solutions and their innovative approaches.
Hybrid CNN-Transformer Model For Facial Affect Recognition In the ABAW4 Challenge
Jul 20, 2022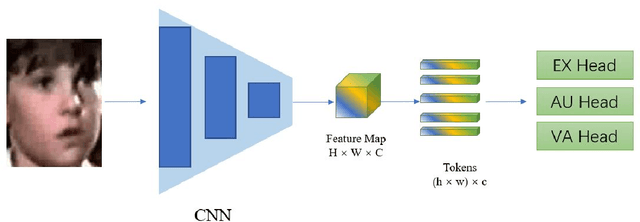

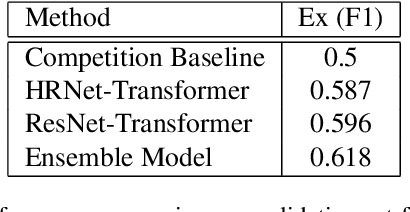
This paper describes our submission to the fourth Affective Behavior Analysis (ABAW) competition. We proposed a hybrid CNN-Transformer model for the Multi-Task-Learning (MTL) and Learning from Synthetic Data (LSD) task. Experimental results on validation dataset shows that our method achieves better performance than baseline model, which verifies that the effectiveness of proposed network.
Multi-modal Multi-label Facial Action Unit Detection with Transformer
Mar 28, 2022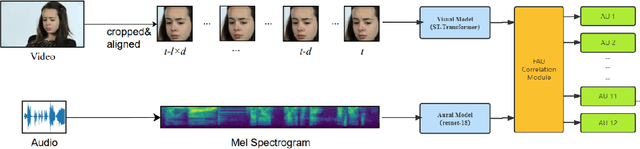
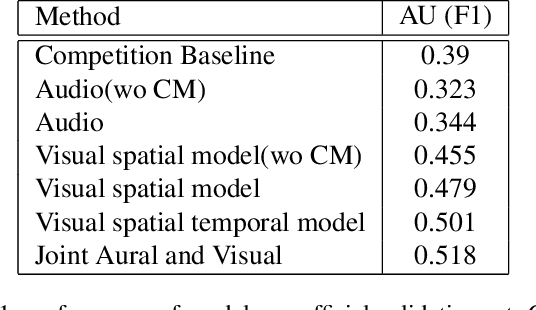
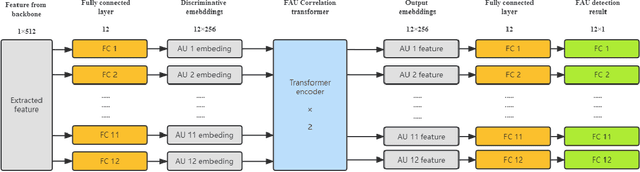
Facial Action Coding System is an important approach of facial expression analysis.This paper describes our submission to the third Affective Behavior Analysis (ABAW) 2022 competition. We proposed a transfomer based model to detect facial action unit (FAU) in video. To be specific, we firstly trained a multi-modal model to extract both audio and visual feature. After that, we proposed a action units correlation module to learn relationships between each action unit labels and refine action unit detection result. Experimental results on validation dataset shows that our method achieves better performance than baseline model, which verifies that the effectiveness of proposed network.
A Multi-task Mean Teacher for Semi-supervised Facial Affective Behavior Analysis
Jul 13, 2021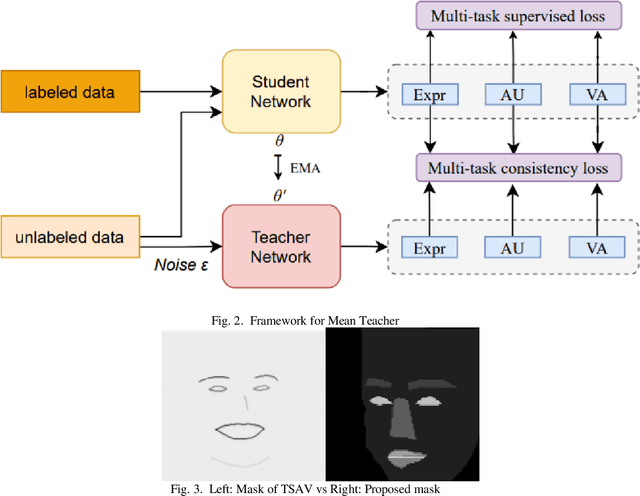
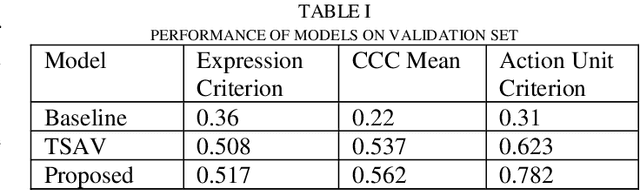
Affective Behavior Analysis is an important part in human-computer interaction. Existing successful affective behavior analysis method such as TSAV[9] suffer from challenge of incomplete labeled datasets. To boost its performance, this paper presents a multi-task mean teacher model for semi-supervised Affective Behavior Analysis to learn from missing labels and exploring the learning of multiple correlated task simultaneously. To be specific, we first utilize TSAV as baseline model to simultaneously recognize the three tasks. We have modified the preprocessing method of rendering mask to provide better semantics information. After that, we extended TSAV model to semi-supervised model using mean teacher, which allow it to be benefited from unlabeled data. Experimental results on validation datasets show that our method achieves better performance than TSAV model, which verifies that the proposed network can effectively learn additional unlabeled data to boost the affective behavior analysis performance.
Deep Discriminative Clustering Analysis
May 05, 2019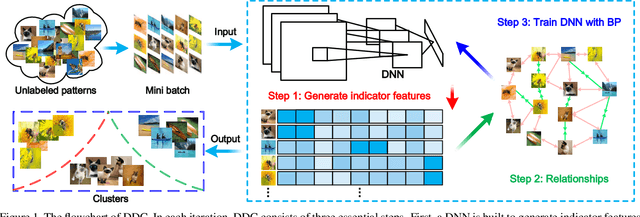
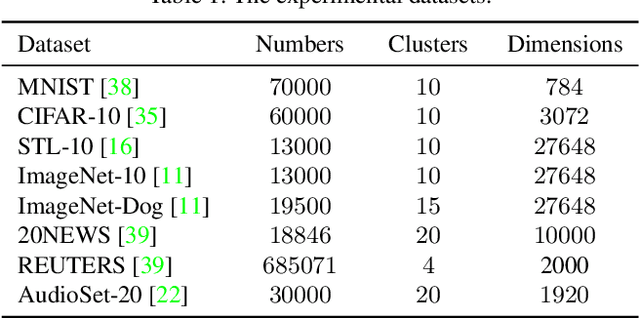
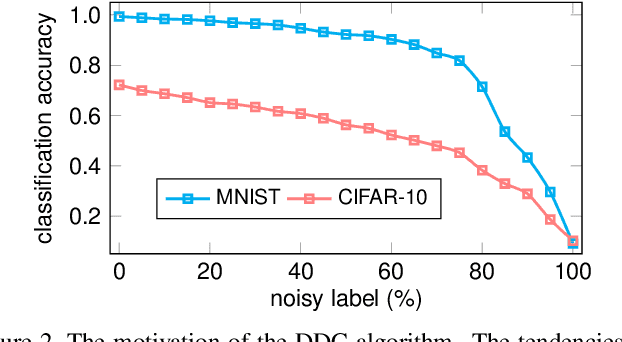
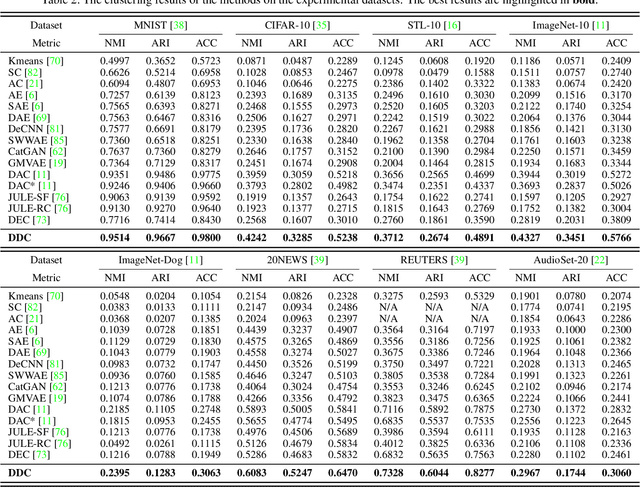
Traditional clustering methods often perform clustering with low-level indiscriminative representations and ignore relationships between patterns, resulting in slight achievements in the era of deep learning. To handle this problem, we develop Deep Discriminative Clustering (DDC) that models the clustering task by investigating relationships between patterns with a deep neural network. Technically, a global constraint is introduced to adaptively estimate the relationships, and a local constraint is developed to endow the network with the capability of learning high-level discriminative representations. By iteratively training the network and estimating the relationships in a mini-batch manner, DDC theoretically converges and the trained network enables to generate a group of discriminative representations that can be treated as clustering centers for straightway clustering. Extensive experiments strongly demonstrate that DDC outperforms current methods on eight image, text and audio datasets concurrently.
Semantic Labeling in Very High Resolution Images via a Self-Cascaded Convolutional Neural Network
Jul 30, 2018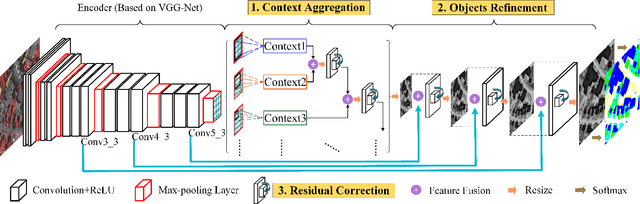


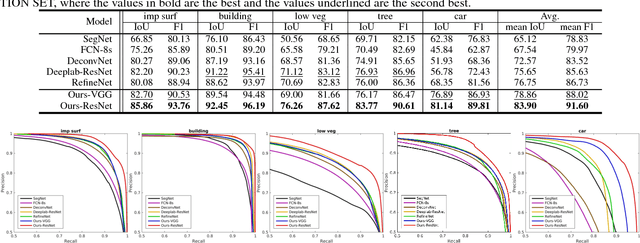
Semantic labeling for very high resolution (VHR) images in urban areas, is of significant importance in a wide range of remote sensing applications. However, many confusing manmade objects and intricate fine-structured objects make it very difficult to obtain both coherent and accurate labeling results. For this challenging task, we propose a novel deep model with convolutional neural networks (CNNs), i.e., an end-to-end self-cascaded network (ScasNet). Specifically, for confusing manmade objects, ScasNet improves the labeling coherence with sequential global-to-local contexts aggregation. Technically, multi-scale contexts are captured on the output of a CNN encoder, and then they are successively aggregated in a self-cascaded manner. Meanwhile, for fine-structured objects, ScasNet boosts the labeling accuracy with a coarse-to-fine refinement strategy. It progressively refines the target objects using the low-level features learned by CNN's shallow layers. In addition, to correct the latent fitting residual caused by multi-feature fusion inside ScasNet, a dedicated residual correction scheme is proposed. It greatly improves the effectiveness of ScasNet. Extensive experimental results on three public datasets, including two challenging benchmarks, show that ScasNet achieves the state-of-the-art performance.