 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallelism and Generation Order in Masked Diffusion Language Models: Limits Today, Potential Tomorrow
Jan 22, 2026Masked Diffusion Language Models (MDLMs) promise parallel token generation and arbitrary-order decoding, yet it remains unclear to what extent current models truly realize these capabilities. We characterize MDLM behavior along two dimensions -- parallelism strength and generation order -- using Average Finalization Parallelism (AFP) and Kendall's tau. We evaluate eight mainstream MDLMs (up to 100B parameters) on 58 benchmarks spanning knowledge, reasoning, and programming. The results show that MDLMs still lag behind comparably sized autoregressive models, mainly because parallel probabilistic modeling weakens inter-token dependencies. Meanwhile, MDLMs exhibit adaptive decoding behavior: their parallelism and generation order vary significantly with the task domain, the stage of reasoning, and whether the output is correct. On tasks that require "backward information" (e.g., Sudoku), MDLMs adopt a solution order that tends to fill easier Sudoku blanks first, highlighting their advantages. Finally, we provide theoretical motivation and design insights supporting a Generate-then-Edit paradigm, which mitigates dependency loss while retaining the efficiency of parallel decoding.
TextVidBench: A Benchmark for Long Video Scene Text Understanding
Jun 05, 2025Despite recent progress on the short-video Text-Visual Question Answering (ViteVQA) task - largely driven by benchmarks such as M4-ViteVQA - existing datasets still suffer from limited video duration and narrow evaluation scopes, making it difficult to adequately assess the growing capabilities of powerful multimodal large language models (MLLMs). To address these limitations, we introduce TextVidBench, the first benchmark specifically designed for long-video text question answering (>3 minutes). TextVidBench makes three key contributions: 1) Cross-domain long-video coverage: Spanning 9 categories (e.g., news, sports, gaming), with an average video length of 2306 seconds, enabling more realistic evaluation of long-video understanding. 2) A three-stage evaluation framework: "Text Needle-in-Haystack -> Temporal Grounding -> Text Dynamics Captioning". 3) High-quality fine-grained annotations: Containing over 5,000 question-answer pairs with detailed semantic labeling. Furthermore, we propose an efficient paradigm for improving large models through: (i) introducing the IT-Rope mechanism and temporal prompt engineering to enhance temporal perception, (ii) adopting non-uniform positional encoding to better handle long video sequences, and (iii) applying lightweight fine-tuning on video-text data. Extensive experiments on multiple public datasets as well as TextVidBench demonstrate that our new benchmark presents significant challenges to existing models, while our proposed method offers valuable insights into improving long-video scene text understanding capabilities.
ALTo: Adaptive-Length Tokenizer for Autoregressive Mask Generation
May 22, 2025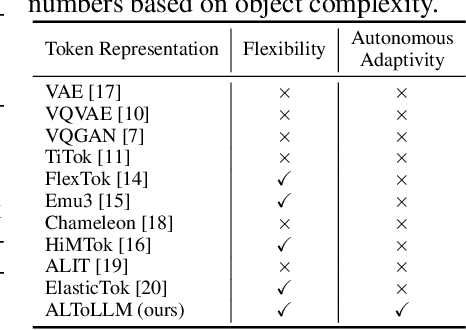
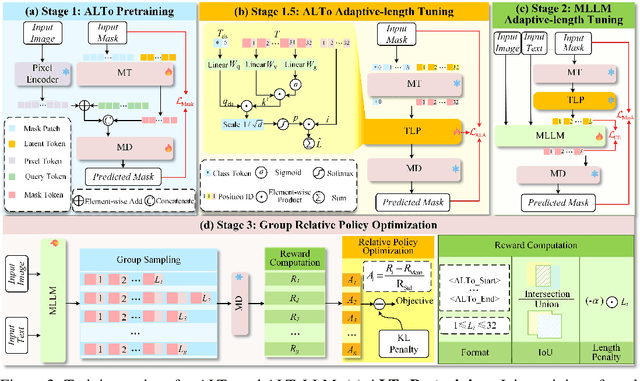
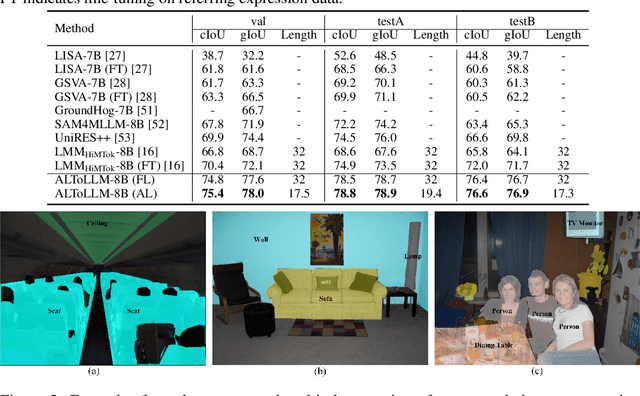
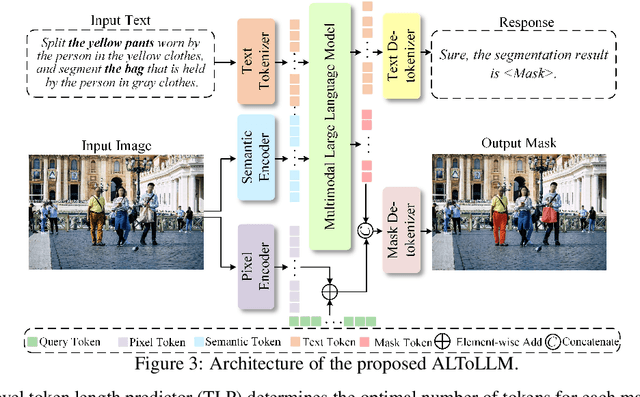
While humans effortlessly draw visual objects and shapes by adaptively allocating attention based on their complexity, existing multimodal large language models (MLLMs) remain constrained by rigid token representations. Bridging this gap, we propose ALTo, an adaptive length tokenizer for autoregressive mask generation. To achieve this, a novel token length predictor is designed, along with a length regularization term and a differentiable token chunking strategy. We further build ALToLLM that seamlessly integrates ALTo into MLLM. Preferences on the trade-offs between mask quality and efficiency is implemented by group relative policy optimization (GRPO). Experiments demonstrate that ALToLLM achieves state-of-the-art performance with adaptive token cost on popular segmentation benchmarks. Code and models are released at https://github.com/yayafengzi/ALToLLM.
Adept: Annotation-Denoising Auxiliary Tasks with Discrete Cosine Transform Map and Keypoint for Human-Centric Pretraining
Apr 29, 2025Human-centric perception is the core of diverse computer vision tasks and has been a long-standing research focus. However, previous research studied these human-centric tasks individually, whose performance is largely limited to the size of the public task-specific datasets. Recent human-centric methods leverage the additional modalities, e.g., depth, to learn fine-grained semantic information, which limits the benefit of pretraining models due to their sensitivity to camera views and the scarcity of RGB-D data on the Internet. This paper improves the data scalability of human-centric pretraining methods by discarding depth information and exploring semantic information of RGB images in the frequency space by Discrete Cosine Transform (DCT). We further propose new annotation denoising auxiliary tasks with keypoints and DCT maps to enforce the RGB image extractor to learn fine-grained semantic information of human bodies. Our extensive experiments show that when pretrained on large-scale datasets (COCO and AIC datasets) without depth annotation, our model achieves better performance than state-of-the-art methods by +0.5 mAP on COCO, +1.4 PCKh on MPII and -0.51 EPE on Human3.6M for pose estimation, by +4.50 mIoU on Human3.6M for human parsing, by -3.14 MAE on SHA and -0.07 MAE on SHB for crowd counting, by +1.1 F1 score on SHA and +0.8 F1 score on SHA for crowd localization, and by +0.1 mAP on Market1501 and +0.8 mAP on MSMT for person ReID. We also validate the effectiveness of our method on MPII+NTURGBD datasets
Unveiling the Impact of Multi-Modal Interactions on User Engagement: A Comprehensive Evaluation in AI-driven Conversations
Jun 21, 2024Large Language Models (LLMs) have significantly advanced user-bot interactions, enabling more complex and coherent dialogues. However, the prevalent text-only modality might not fully exploit the potential for effective user engagement. This paper explores the impact of multi-modal interactions, which incorporate images and audio alongside text, on user engagement in chatbot conversations. We conduct a comprehensive analysis using a diverse set of chatbots and real-user interaction data, employing metrics such as retention rate and conversation length to evaluate user engagement. Our findings reveal a significant enhancement in user engagement with multi-modal interactions compared to text-only dialogues. Notably, the incorporation of a third modality significantly amplifies engagement beyond the benefits observed with just two modalities. These results suggest that multi-modal interactions optimize cognitive processing and facilitate richer information comprehension. This study underscores the importance of multi-modality in chatbot design, offering valuable insights for creating more engaging and immersive AI communication experiences and informing the broader AI community about the benefits of multi-modal interactions in enhancing user engagement.