 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallelism and Generation Order in Masked Diffusion Language Models: Limits Today, Potential Tomorrow
Jan 22, 2026Masked Diffusion Language Models (MDLMs) promise parallel token generation and arbitrary-order decoding, yet it remains unclear to what extent current models truly realize these capabilities. We characterize MDLM behavior along two dimensions -- parallelism strength and generation order -- using Average Finalization Parallelism (AFP) and Kendall's tau. We evaluate eight mainstream MDLMs (up to 100B parameters) on 58 benchmarks spanning knowledge, reasoning, and programming. The results show that MDLMs still lag behind comparably sized autoregressive models, mainly because parallel probabilistic modeling weakens inter-token dependencies. Meanwhile, MDLMs exhibit adaptive decoding behavior: their parallelism and generation order vary significantly with the task domain, the stage of reasoning, and whether the output is correct. On tasks that require "backward information" (e.g., Sudoku), MDLMs adopt a solution order that tends to fill easier Sudoku blanks first, highlighting their advantages. Finally, we provide theoretical motivation and design insights supporting a Generate-then-Edit paradigm, which mitigates dependency loss while retaining the efficiency of parallel decoding.
ROSE: Remove Objects with Side Effects in Videos
Aug 26, 2025Video object removal has achieved advanced performance due to the recent success of video generative models. However, when addressing the side effects of objects, e.g., their shadows and reflections, existing works struggle to eliminate these effects for the scarcity of paired video data as supervision. This paper presents ROSE, termed Remove Objects with Side Effects, a framework that systematically studies the object's effects on environment, which can be categorized into five common cases: shadows, reflections, light, translucency and mirror. Given the challenges of curating paired videos exhibiting the aforementioned effects, we leverage a 3D rendering engine for synthetic data generation. We carefully construct a fully-automatic pipeline for data preparation, which simulates a large-scale paired dataset with diverse scenes, objects, shooting angles, and camera trajectories. ROSE is implemented as an video inpainting model built on diffusion transformer. To localize all object-correlated areas, the entire video is fed into the model for reference-based erasing. Moreover, additional supervision is introduced to explicitly predict the areas affected by side effects, which can be revealed through the differential mask between the paired videos. To fully investigate the model performance on various side effect removal, we presents a new benchmark, dubbed ROSE-Bench, incorporating both common scenarios and the five special side effects for comprehensive evaluation. Experimental results demonstrate that ROSE achieves superior performance compared to existing video object erasing models and generalizes well to real-world video scenarios. The project page is https://rose2025-inpaint.github.io/.
TextVidBench: A Benchmark for Long Video Scene Text Understanding
Jun 05, 2025Despite recent progress on the short-video Text-Visual Question Answering (ViteVQA) task - largely driven by benchmarks such as M4-ViteVQA - existing datasets still suffer from limited video duration and narrow evaluation scopes, making it difficult to adequately assess the growing capabilities of powerful multimodal large language models (MLLMs). To address these limitations, we introduce TextVidBench, the first benchmark specifically designed for long-video text question answering (>3 minutes). TextVidBench makes three key contributions: 1) Cross-domain long-video coverage: Spanning 9 categories (e.g., news, sports, gaming), with an average video length of 2306 seconds, enabling more realistic evaluation of long-video understanding. 2) A three-stage evaluation framework: "Text Needle-in-Haystack -> Temporal Grounding -> Text Dynamics Captioning". 3) High-quality fine-grained annotations: Containing over 5,000 question-answer pairs with detailed semantic labeling. Furthermore, we propose an efficient paradigm for improving large models through: (i) introducing the IT-Rope mechanism and temporal prompt engineering to enhance temporal perception, (ii) adopting non-uniform positional encoding to better handle long video sequences, and (iii) applying lightweight fine-tuning on video-text data. Extensive experiments on multiple public datasets as well as TextVidBench demonstrate that our new benchmark presents significant challenges to existing models, while our proposed method offers valuable insights into improving long-video scene text understanding capabilities.
Adept: Annotation-Denoising Auxiliary Tasks with Discrete Cosine Transform Map and Keypoint for Human-Centric Pretraining
Apr 29, 2025Human-centric perception is the core of diverse computer vision tasks and has been a long-standing research focus. However, previous research studied these human-centric tasks individually, whose performance is largely limited to the size of the public task-specific datasets. Recent human-centric methods leverage the additional modalities, e.g., depth, to learn fine-grained semantic information, which limits the benefit of pretraining models due to their sensitivity to camera views and the scarcity of RGB-D data on the Internet. This paper improves the data scalability of human-centric pretraining methods by discarding depth information and exploring semantic information of RGB images in the frequency space by Discrete Cosine Transform (DCT). We further propose new annotation denoising auxiliary tasks with keypoints and DCT maps to enforce the RGB image extractor to learn fine-grained semantic information of human bodies. Our extensive experiments show that when pretrained on large-scale datasets (COCO and AIC datasets) without depth annotation, our model achieves better performance than state-of-the-art methods by +0.5 mAP on COCO, +1.4 PCKh on MPII and -0.51 EPE on Human3.6M for pose estimation, by +4.50 mIoU on Human3.6M for human parsing, by -3.14 MAE on SHA and -0.07 MAE on SHB for crowd counting, by +1.1 F1 score on SHA and +0.8 F1 score on SHA for crowd localization, and by +0.1 mAP on Market1501 and +0.8 mAP on MSMT for person ReID. We also validate the effectiveness of our method on MPII+NTURGBD datasets
Instruct-ReID++: Towards Universal Purpose Instruction-Guided Person Re-identification
May 28, 2024



Human intelligence can retrieve any person according to both visual and language descriptions. However, the current computer vision community studies specific person re-identification (ReID) tasks in different scenarios separately, which limits the applications in the real world. This paper strives to resolve this problem by proposing a novel instruct-ReID task that requires the model to retrieve images according to the given image or language instructions. Instruct-ReID is the first exploration of a general ReID setting, where existing 6 ReID tasks can be viewed as special cases by assigning different instructions. To facilitate research in this new instruct-ReID task, we propose a large-scale OmniReID++ benchmark equipped with diverse data and comprehensive evaluation methods e.g., task specific and task-free evaluation settings. In the task-specific evaluation setting, gallery sets are categorized according to specific ReID tasks. We propose a novel baseline model, IRM, with an adaptive triplet loss to handle various retrieval tasks within a unified framework. For task-free evaluation setting, where target person images are retrieved from task-agnostic gallery sets, we further propose a new method called IRM++ with novel memory bank-assisted learning. Extensive evaluations of IRM and IRM++ on OmniReID++ benchmark demonstrate the superiority of our proposed methods, achieving state-of-the-art performance on 10 test sets. The datasets, the model, and the code will be available at https://github.com/hwz-zju/Instruct-ReID
Triplet Attention Transformer for Spatiotemporal Predictive Learning
Oct 28, 2023



Spatiotemporal predictive learning offers a self-supervised learning paradigm that enables models to learn both spatial and temporal patterns by predicting future sequences based on historical sequences. Mainstream methods are dominated by recurrent units, yet they are limited by their lack of parallelization and often underperform in real-world scenarios. To improve prediction quality while maintaining computational efficiency, we propose an innovative triplet attention transformer designed to capture both inter-frame dynamics and intra-frame static features. Specifically, the model incorporates the Triplet Attention Module (TAM), which replaces traditional recurrent units by exploring self-attention mechanisms in temporal, spatial, and channel dimensions. In this configuration: (i) temporal tokens contain abstract representations of inter-frame, facilitating the capture of inherent temporal dependencies; (ii) spatial and channel attention combine to refine the intra-frame representation by performing fine-grained interactions across spatial and channel dimensions. Alternating temporal, spatial, and channel-level attention allows our approach to learn more complex short- and long-range spatiotemporal dependencies. Extensive experiments demonstrate performance surpassing existing recurrent-based and recurrent-free methods, achieving state-of-the-art under multi-scenario examination including moving object trajectory prediction, traffic flow prediction, driving scene prediction, and human motion capture.
Retrieve Anyone: A General-purpose Person Re-identification Task with Instructions
Jul 04, 2023



Human intelligence can retrieve any person according to both visual and language descriptions. However, the current computer vision community studies specific person re-identification (ReID) tasks in different scenarios separately, which limits the applications in the real world. This paper strives to resolve this problem by proposing a new instruct-ReID task that requires the model to retrieve images according to the given image or language instructions.Our instruct-ReID is a more general ReID setting, where existing ReID tasks can be viewed as special cases by designing different instructions. We propose a large-scale OmniReID benchmark and an adaptive triplet loss as a baseline method to facilitate research in this new setting. Experimental results show that the baseline model trained on our OmniReID benchmark can improve +0.6%, +1.4%, 0.2% mAP on Market1501, CUHK03, MSMT17 for traditional ReID, +0.8%, +2.0%, +13.4% mAP on PRCC, VC-Clothes, LTCC for clothes-changing ReID, +11.7% mAP on COCAS+ real2 for clothestemplate based clothes-changing ReID when using only RGB images, +25.4% mAP on COCAS+ real2 for our newly defined language-instructed ReID. The dataset, model, and code will be available at https://github.com/hwz-zju/Instruct-ReID.
Learning Domain Adaptive Object Detection with Probabilistic Teacher
Jun 13, 2022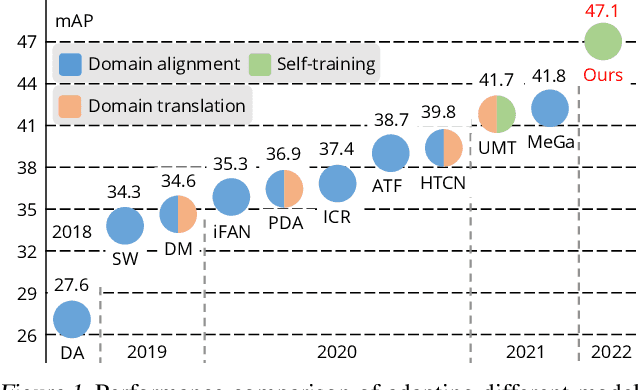
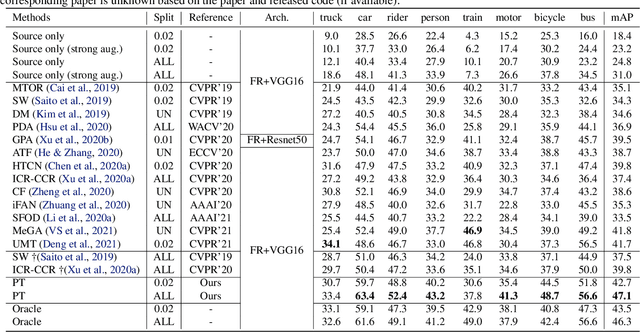
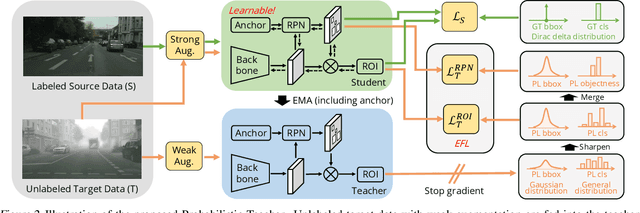
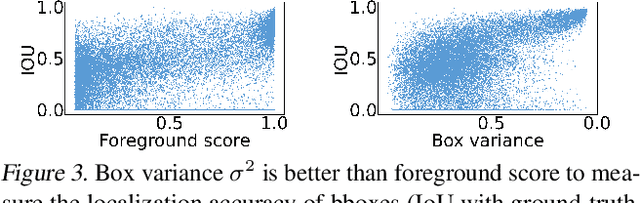
Self-training for unsupervised domain adaptive object detection is a challenging task, of which the performance depends heavily on the quality of pseudo boxes. Despite the promising results, prior works have largely overlooked the uncertainty of pseudo boxes during self-training. In this paper, we present a simple yet effective framework, termed as Probabilistic Teacher (PT), which aims to capture the uncertainty of unlabeled target data from a gradually evolving teacher and guides the learning of a student in a mutually beneficial manner. Specifically, we propose to leverage the uncertainty-guided consistency training to promote classification adaptation and localization adaptation, rather than filtering pseudo boxes via an elaborate confidence threshold. In addition, we conduct anchor adaptation in parallel with localization adaptation, since anchor can be regarded as a learnable parameter. Together with this framework, we also present a novel Entropy Focal Loss (EFL) to further facilitate the uncertainty-guided self-training. Equipped with EFL, PT outperforms all previous baselines by a large margin and achieve new state-of-the-arts.
* To appear in ICML 2022. Code is coming soon: https://github.com/hikvision-research/ProbabilisticTeacher