 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Vision-Language Foundation Models: A Data-Free Approach via Prompt Diversification
Jul 21, 2024



Data-Free Knowledge Distillation (DFKD) has shown great potential in creating a compact student model while alleviating the dependency on real training data by synthesizing surrogate data. However, prior arts are seldom discussed under distribution shifts, which may be vulnerable in real-world applications. Recent Vision-Language Foundation Models, e.g., CLIP, have demonstrated remarkable performance in zero-shot out-of-distribution generalization, yet consuming heavy computation resources. In this paper, we discuss the extension of DFKD to Vision-Language Foundation Models without access to the billion-level image-text datasets. The objective is to customize a student model for distribution-agnostic downstream tasks with given category concepts, inheriting the out-of-distribution generalization capability from the pre-trained foundation models. In order to avoid generalization degradation, the primary challenge of this task lies in synthesizing diverse surrogate images driven by text prompts. Since not only category concepts but also style information are encoded in text prompts, we propose three novel Prompt Diversification methods to encourage image synthesis with diverse styles, namely Mix-Prompt, Random-Prompt, and Contrastive-Prompt. Experiments on out-of-distribution generalization datasets demonstrate the effectiveness of the proposed methods, with Contrastive-Prompt performing the best.
Adapt Anything: Tailor Any Image Classifiers across Domains And Categories Using Text-to-Image Diffusion Models
Oct 25, 2023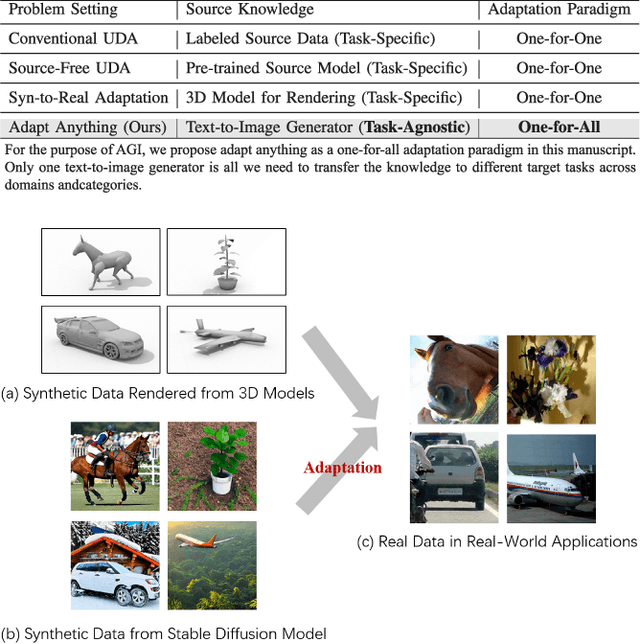

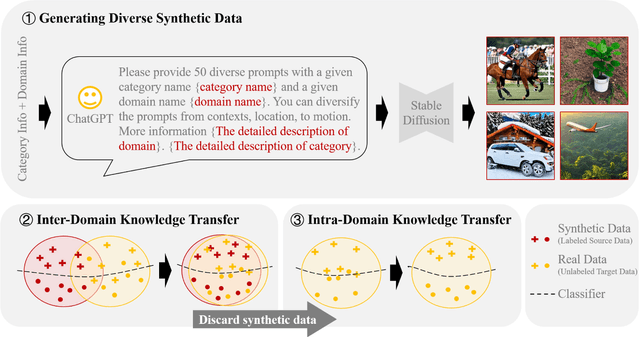
We do not pursue a novel method in this paper, but aim to study if a modern text-to-image diffusion model can tailor any task-adaptive image classifier across domains and categories. Existing domain adaptive image classification works exploit both source and target data for domain alignment so as to transfer the knowledge learned from the labeled source data to the unlabeled target data. However, as the development of the text-to-image diffusion model, we wonder if the high-fidelity synthetic data from the text-to-image generator can serve as a surrogate of the source data in real world. In this way, we do not need to collect and annotate the source data for each domain adaptation task in a one-for-one manner. Instead, we utilize only one off-the-shelf text-to-image model to synthesize images with category labels derived from the corresponding text prompts, and then leverage the surrogate data as a bridge to transfer the knowledge embedded in the task-agnostic text-to-image generator to the task-oriented image classifier via domain adaptation. Such a one-for-all adaptation paradigm allows us to adapt anything in the world using only one text-to-image generator as well as the corresponding unlabeled target data. Extensive experiments validate the feasibility of the proposed idea, which even surpasses the state-of-the-art domain adaptation works using the source data collected and annotated in real world.
1st Place Solution for ECCV 2022 OOD-CV Challenge Object Detection Track
Jan 12, 2023



OOD-CV challenge is an out-of-distribution generalization task. To solve this problem in object detection track, we propose a simple yet effective Generalize-then-Adapt (G&A) framework, which is composed of a two-stage domain generalization part and a one-stage domain adaptation part. The domain generalization part is implemented by a Supervised Model Pretraining stage using source data for model warm-up and a Weakly Semi-Supervised Model Pretraining stage using both source data with box-level label and auxiliary data (ImageNet-1K) with image-level label for performance boosting. The domain adaptation part is implemented as a Source-Free Domain Adaptation paradigm, which only uses the pre-trained model and the unlabeled target data to further optimize in a self-supervised training manner. The proposed G&A framework help us achieve the first place on the object detection leaderboard of the OOD-CV challenge. Code will be released in https://github.com/hikvision-research/OOD-CV.
1st Place Solution for ECCV 2022 OOD-CV Challenge Image Classification Track
Jan 12, 2023OOD-CV challenge is an out-of-distribution generalization task. In this challenge, our core solution can be summarized as that Noisy Label Learning Is A Strong Test-Time Domain Adaptation Optimizer. Briefly speaking, our main pipeline can be divided into two stages, a pre-training stage for domain generalization and a test-time training stage for domain adaptation. We only exploit labeled source data in the pre-training stage and only exploit unlabeled target data in the test-time training stage. In the pre-training stage, we propose a simple yet effective Mask-Level Copy-Paste data augmentation strategy to enhance out-of-distribution generalization ability so as to resist shape, pose, context, texture, occlusion, and weather domain shifts in this challenge. In the test-time training stage, we use the pre-trained model to assign noisy label for the unlabeled target data, and propose a Label-Periodically-Updated DivideMix method for noisy label learning. After integrating Test-Time Augmentation and Model Ensemble strategies, our solution ranks the first place on the Image Classification Leaderboard of the OOD-CV Challenge. Code will be released in https://github.com/hikvision-research/OOD-CV.
Attention Diversification for Domain Generalization
Oct 09, 2022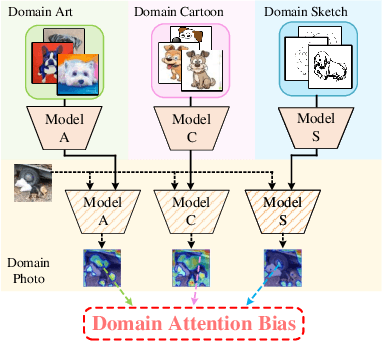
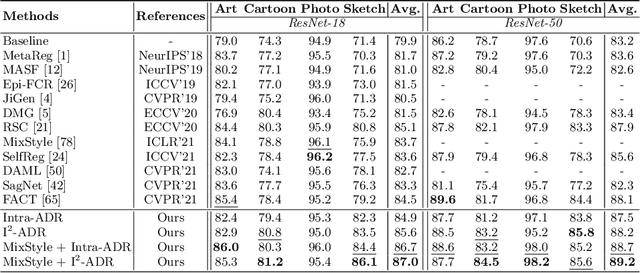
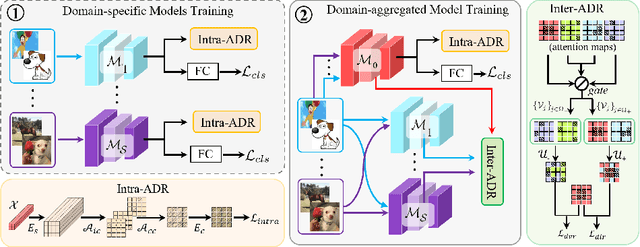
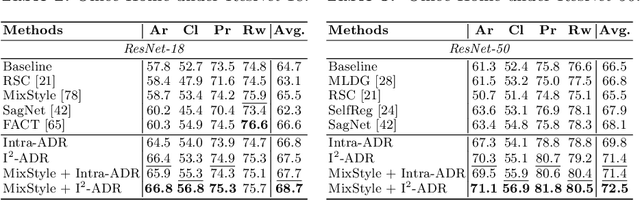
Convolutional neural networks (CNNs) have demonstrated gratifying results at learning discriminative features. However, when applied to unseen domains, state-of-the-art models are usually prone to errors due to domain shift. After investigating this issue from the perspective of shortcut learning, we find the devils lie in the fact that models trained on different domains merely bias to different domain-specific features yet overlook diverse task-related features. Under this guidance, a novel Attention Diversification framework is proposed, in which Intra-Model and Inter-Model Attention Diversification Regularization are collaborated to reassign appropriate attention to diverse task-related features. Briefly, Intra-Model Attention Diversification Regularization is equipped on the high-level feature maps to achieve in-channel discrimination and cross-channel diversification via forcing different channels to pay their most salient attention to different spatial locations. Besides, Inter-Model Attention Diversification Regularization is proposed to further provide task-related attention diversification and domain-related attention suppression, which is a paradigm of "simulate, divide and assemble": simulate domain shift via exploiting multiple domain-specific models, divide attention maps into task-related and domain-related groups, and assemble them within each group respectively to execute regularization. Extensive experiments and analyses are conducted on various benchmarks to demonstrate that our method achieves state-of-the-art performance over other competing methods. Code is available at https://github.com/hikvision-research/DomainGeneralization.
* ECCV 2022. Code available at https://github.com/hikvision-research/DomainGeneralization
Slimmable Domain Adaptation
Jun 14, 2022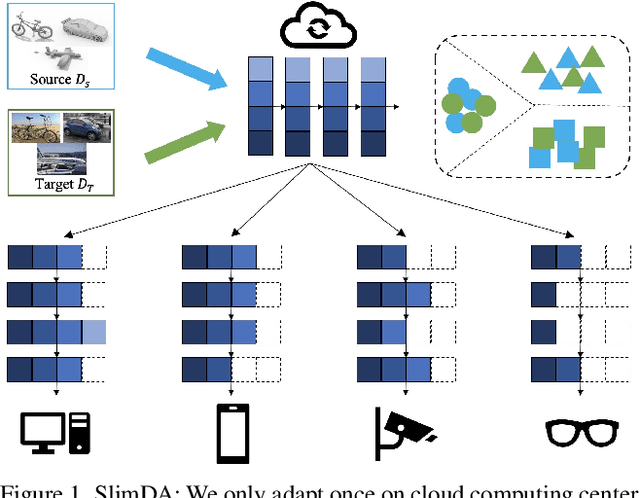

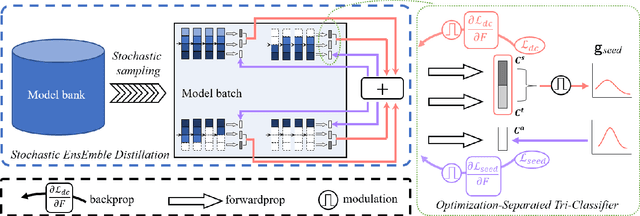
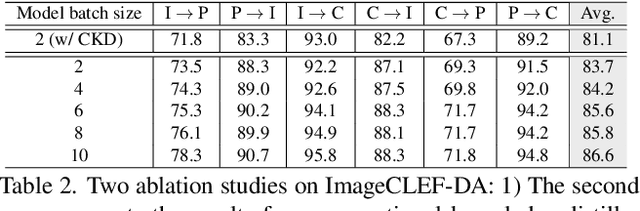
Vanilla unsupervised domain adaptation methods tend to optimize the model with fixed neural architecture, which is not very practical in real-world scenarios since the target data is usually processed by different resource-limited devices. It is therefore of great necessity to facilitate architecture adaptation across various devices. In this paper, we introduce a simple framework, Slimmable Domain Adaptation, to improve cross-domain generalization with a weight-sharing model bank, from which models of different capacities can be sampled to accommodate different accuracy-efficiency trade-offs. The main challenge in this framework lies in simultaneously boosting the adaptation performance of numerous models in the model bank. To tackle this problem, we develop a Stochastic EnsEmble Distillation method to fully exploit the complementary knowledge in the model bank for inter-model interaction. Nevertheless, considering the optimization conflict between inter-model interaction and intra-model adaptation, we augment the existing bi-classifier domain confusion architecture into an Optimization-Separated Tri-Classifier counterpart. After optimizing the model bank, architecture adaptation is leveraged via our proposed Unsupervised Performance Evaluation Metric. Under various resource constraints, our framework surpasses other competing approaches by a very large margin on multiple benchmarks. It is also worth emphasizing that our framework can preserve the performance improvement against the source-only model even when the computing complexity is reduced to $1/64$. Code will be available at https://github.com/hikvision-research/SlimDA.
* To appear in CVPR 2022. Code is coming soon: https://github.com/hikvision-research/SlimDA
Label Matching Semi-Supervised Object Detection
Jun 14, 2022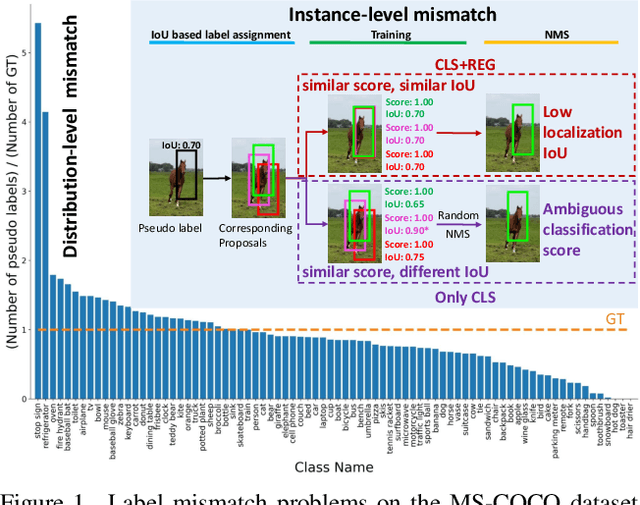
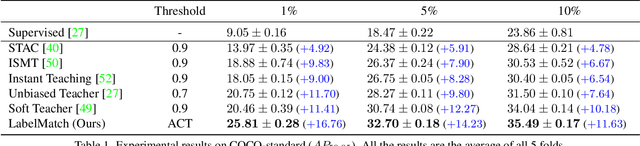
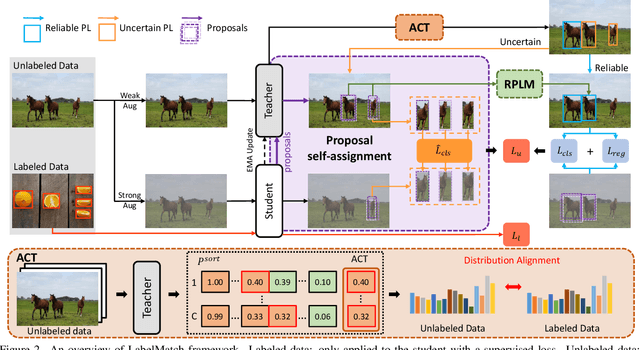

Semi-supervised object detection has made significant progress with the development of mean teacher driven self-training. Despite the promising results, the label mismatch problem is not yet fully explored in the previous works, leading to severe confirmation bias during self-training. In this paper, we delve into this problem and propose a simple yet effective LabelMatch framework from two different yet complementary perspectives, i.e., distribution-level and instance-level. For the former one, it is reasonable to approximate the class distribution of the unlabeled data from that of the labeled data according to Monte Carlo Sampling. Guided by this weakly supervision cue, we introduce a re-distribution mean teacher, which leverages adaptive label-distribution-aware confidence thresholds to generate unbiased pseudo labels to drive student learning. For the latter one, there exists an overlooked label assignment ambiguity problem across teacher-student models. To remedy this issue, we present a novel label assignment mechanism for self-training framework, namely proposal self-assignment, which injects the proposals from student into teacher and generates accurate pseudo labels to match each proposal in the student model accordingly. Experiments on both MS-COCO and PASCAL-VOC datasets demonstrate the considerable superiority of our proposed framework to other state-of-the-arts. Code will be available at https://github.com/hikvision-research/SSOD.
* To appear in CVPR 2022. Code is coming soon: https://github.com/hikvision-research/SSOD
Learning Domain Adaptive Object Detection with Probabilistic Teacher
Jun 13, 2022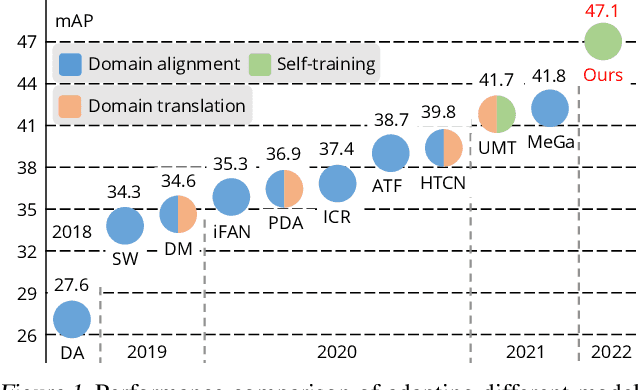
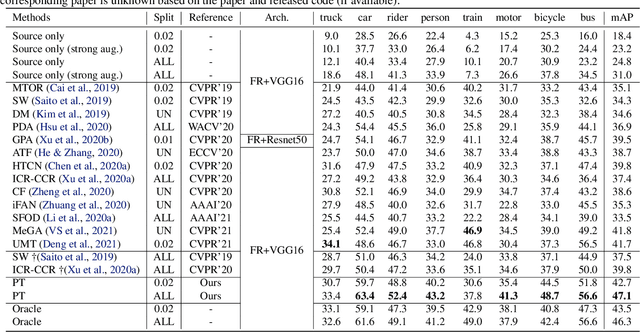
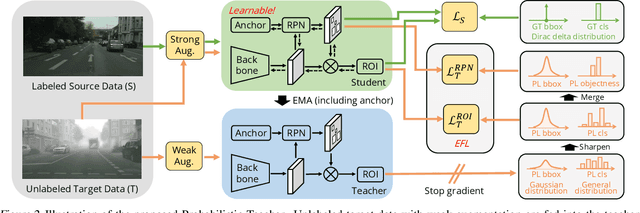
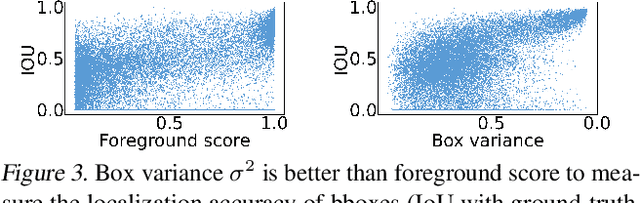
Self-training for unsupervised domain adaptive object detection is a challenging task, of which the performance depends heavily on the quality of pseudo boxes. Despite the promising results, prior works have largely overlooked the uncertainty of pseudo boxes during self-training. In this paper, we present a simple yet effective framework, termed as Probabilistic Teacher (PT), which aims to capture the uncertainty of unlabeled target data from a gradually evolving teacher and guides the learning of a student in a mutually beneficial manner. Specifically, we propose to leverage the uncertainty-guided consistency training to promote classification adaptation and localization adaptation, rather than filtering pseudo boxes via an elaborate confidence threshold. In addition, we conduct anchor adaptation in parallel with localization adaptation, since anchor can be regarded as a learnable parameter. Together with this framework, we also present a novel Entropy Focal Loss (EFL) to further facilitate the uncertainty-guided self-training. Equipped with EFL, PT outperforms all previous baselines by a large margin and achieve new state-of-the-arts.
* To appear in ICML 2022. Code is coming soon: https://github.com/hikvision-research/ProbabilisticTeacher
Transductive CLIP with Class-Conditional Contrastive Learning
Jun 13, 2022

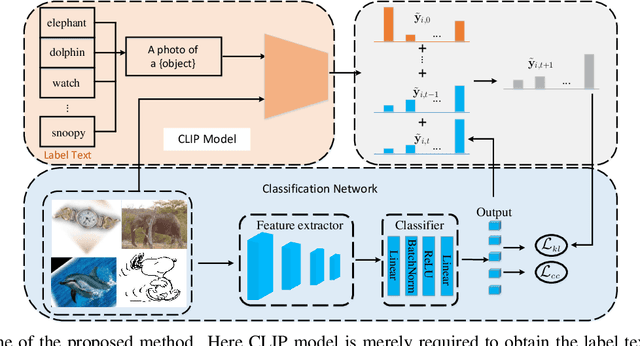
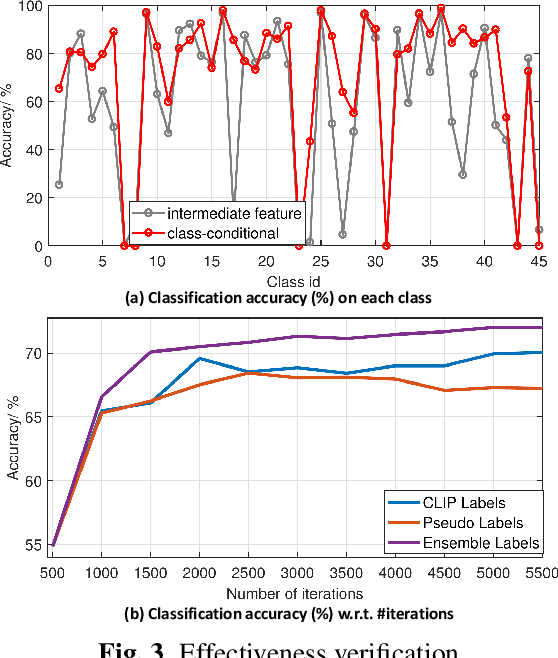
Inspired by the remarkable zero-shot generalization capacity of vision-language pre-trained model, we seek to leverage the supervision from CLIP model to alleviate the burden of data labeling. However, such supervision inevitably contains the label noise, which significantly degrades the discriminative power of the classification model. In this work, we propose Transductive CLIP, a novel framework for learning a classification network with noisy labels from scratch. Firstly, a class-conditional contrastive learning mechanism is proposed to mitigate the reliance on pseudo labels and boost the tolerance to noisy labels. Secondly, ensemble labels is adopted as a pseudo label updating strategy to stabilize the training of deep neural networks with noisy labels. This framework can reduce the impact of noisy labels from CLIP model effectively by combining both techniques. Experiments on multiple benchmark datasets demonstrate the substantial improvements over other state-of-the-art methods.
* Published in IEEE ICASSP 2022
2nd Place Solution for ICCV 2021 VIPriors Image Classification Challenge: An Attract-and-Repulse Learning Approach
Jun 13, 2022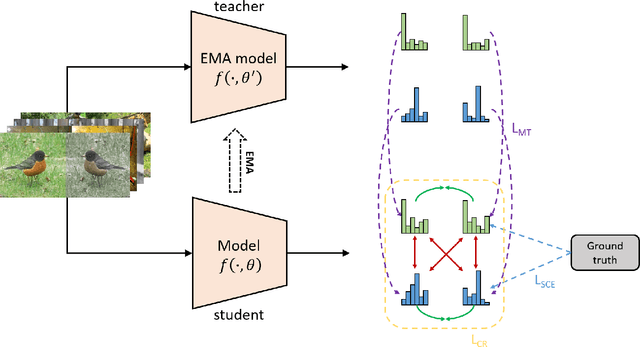

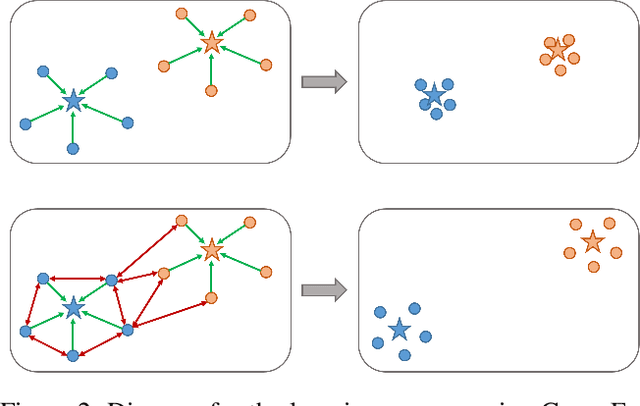

Convolutional neural networks (CNNs) have achieved significant success in image classification by utilizing large-scale datasets. However, it is still of great challenge to learn from scratch on small-scale datasets efficiently and effectively. With limited training datasets, the concepts of categories will be ambiguous since the over-parameterized CNNs tend to simply memorize the dataset, leading to poor generalization capacity. Therefore, it is crucial to study how to learn more discriminative representations while avoiding over-fitting. Since the concepts of categories tend to be ambiguous, it is important to catch more individual-wise information. Thus, we propose a new framework, termed Attract-and-Repulse, which consists of Contrastive Regularization (CR) to enrich the feature representations, Symmetric Cross Entropy (SCE) to balance the fitting for different classes and Mean Teacher to calibrate label information. Specifically, SCE and CR learn discriminative representations while alleviating over-fitting by the adaptive trade-off between the information of classes (attract) and instances (repulse). After that, Mean Teacher is used to further improve the performance via calibrating more accurate soft pseudo labels. Sufficient experiments validate the effectiveness of the Attract-and-Repulse framework. Together with other strategies, such as aggressive data augmentation, TenCrop inference, and models ensembling, we achieve the second place in ICCV 2021 VIPriors Image Classification Challenge.