 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Vision-Language Foundation Models: A Data-Free Approach via Prompt Diversification
Jul 21, 2024



Data-Free Knowledge Distillation (DFKD) has shown great potential in creating a compact student model while alleviating the dependency on real training data by synthesizing surrogate data. However, prior arts are seldom discussed under distribution shifts, which may be vulnerable in real-world applications. Recent Vision-Language Foundation Models, e.g., CLIP, have demonstrated remarkable performance in zero-shot out-of-distribution generalization, yet consuming heavy computation resources. In this paper, we discuss the extension of DFKD to Vision-Language Foundation Models without access to the billion-level image-text datasets. The objective is to customize a student model for distribution-agnostic downstream tasks with given category concepts, inheriting the out-of-distribution generalization capability from the pre-trained foundation models. In order to avoid generalization degradation, the primary challenge of this task lies in synthesizing diverse surrogate images driven by text prompts. Since not only category concepts but also style information are encoded in text prompts, we propose three novel Prompt Diversification methods to encourage image synthesis with diverse styles, namely Mix-Prompt, Random-Prompt, and Contrastive-Prompt. Experiments on out-of-distribution generalization datasets demonstrate the effectiveness of the proposed methods, with Contrastive-Prompt performing the best.
Label Matching Semi-Supervised Object Detection
Jun 14, 2022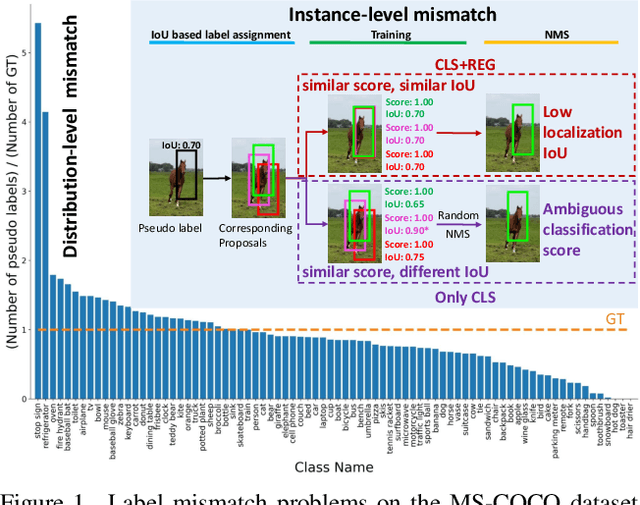
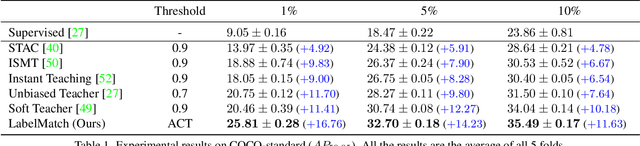
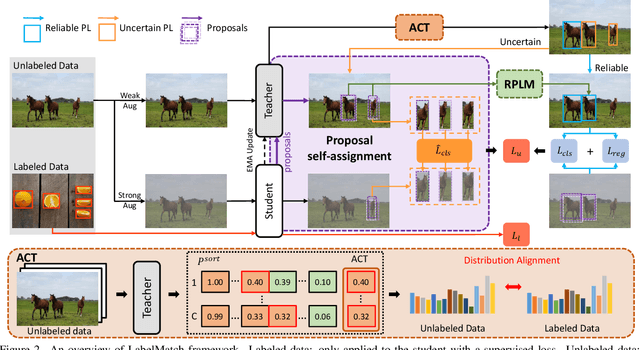

Semi-supervised object detection has made significant progress with the development of mean teacher driven self-training. Despite the promising results, the label mismatch problem is not yet fully explored in the previous works, leading to severe confirmation bias during self-training. In this paper, we delve into this problem and propose a simple yet effective LabelMatch framework from two different yet complementary perspectives, i.e., distribution-level and instance-level. For the former one, it is reasonable to approximate the class distribution of the unlabeled data from that of the labeled data according to Monte Carlo Sampling. Guided by this weakly supervision cue, we introduce a re-distribution mean teacher, which leverages adaptive label-distribution-aware confidence thresholds to generate unbiased pseudo labels to drive student learning. For the latter one, there exists an overlooked label assignment ambiguity problem across teacher-student models. To remedy this issue, we present a novel label assignment mechanism for self-training framework, namely proposal self-assignment, which injects the proposals from student into teacher and generates accurate pseudo labels to match each proposal in the student model accordingly. Experiments on both MS-COCO and PASCAL-VOC datasets demonstrate the considerable superiority of our proposed framework to other state-of-the-arts. Code will be available at https://github.com/hikvision-research/SSOD.
* To appear in CVPR 2022. Code is coming soon: https://github.com/hikvision-research/SSOD