 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Fourth Monocular Depth Estimation Challenge
Apr 24, 2025


This paper presents the results of the fourth edition of the Monocular Depth Estimation Challenge (MDEC), which focuses on zero-shot generalization to the SYNS-Patches benchmark, a dataset featuring challenging environments in both natural and indoor settings. In this edition, we revised the evaluation protocol to use least-squares alignment with two degrees of freedom to support disparity and affine-invariant predictions. We also revised the baselines and included popular off-the-shelf methods: Depth Anything v2 and Marigold. The challenge received a total of 24 submissions that outperformed the baselines on the test set; 10 of these included a report describing their approach, with most leading methods relying on affine-invariant predictions. The challenge winners improved the 3D F-Score over the previous edition's best result, raising it from 22.58% to 23.05%.
Unbiased Evaluation of Large Language Models from a Causal Perspective
Feb 10, 2025



Benchmark contamination has become a significant concern in the LLM evaluation community. Previous Agents-as-an-Evaluator address this issue by involving agents in the generation of questions. Despite their success, the biases in Agents-as-an-Evaluator methods remain largely unexplored. In this paper, we present a theoretical formulation of evaluation bias, providing valuable insights into designing unbiased evaluation protocols. Furthermore, we identify two type of bias in Agents-as-an-Evaluator through carefully designed probing tasks on a minimal Agents-as-an-Evaluator setup. To address these issues, we propose the Unbiased Evaluator, an evaluation protocol that delivers a more comprehensive, unbiased, and interpretable assessment of LLMs.Extensive experiments reveal significant room for improvement in current LLMs. Additionally, we demonstrate that the Unbiased Evaluator not only offers strong evidence of benchmark contamination but also provides interpretable evaluation results.
Gaze Label Alignment: Alleviating Domain Shift for Gaze Estimation
Dec 20, 2024Gaze estimation methods encounter significant performance deterioration when being evaluated across different domains, because of the domain gap between the testing and training data. Existing methods try to solve this issue by reducing the deviation of data distribution, however, they ignore the existence of label deviation in the data due to the acquisition mechanism of the gaze label and the individual physiological differences. In this paper, we first point out that the influence brought by the label deviation cannot be ignored, and propose a gaze label alignment algorithm (GLA) to eliminate the label distribution deviation. Specifically, we first train the feature extractor on all domains to get domain invariant features, and then select an anchor domain to train the gaze regressor. We predict the gaze label on remaining domains and use a mapping function to align the labels. Finally, these aligned labels can be used to train gaze estimation models. Therefore, our method can be combined with any existing method. Experimental results show that our GLA method can effectively alleviate the label distribution shift, and SOTA gaze estimation methods can be further improved obviously.
LG-Gaze: Learning Geometry-aware Continuous Prompts for Language-Guided Gaze Estimation
Nov 13, 2024The ability of gaze estimation models to generalize is often significantly hindered by various factors unrelated to gaze, especially when the training dataset is limited. Current strategies aim to address this challenge through different domain generalization techniques, yet they have had limited success due to the risk of overfitting when solely relying on value labels for regression. Recent progress in pre-trained vision-language models has motivated us to capitalize on the abundant semantic information available. We propose a novel approach in this paper, reframing the gaze estimation task as a vision-language alignment issue. Our proposed framework, named Language-Guided Gaze Estimation (LG-Gaze), learns continuous and geometry-sensitive features for gaze estimation benefit from the rich prior knowledges of vision-language models. Specifically, LG-Gaze aligns gaze features with continuous linguistic features through our proposed multimodal contrastive regression loss, which customizes adaptive weights for different negative samples. Furthermore, to better adapt to the labels for gaze estimation task, we propose a geometry-aware interpolation method to obtain more precise gaze embeddings. Through extensive experiments, we validate the efficacy of our framework in four different cross-domain evaluation tasks.
Distilling Vision-Language Foundation Models: A Data-Free Approach via Prompt Diversification
Jul 21, 2024



Data-Free Knowledge Distillation (DFKD) has shown great potential in creating a compact student model while alleviating the dependency on real training data by synthesizing surrogate data. However, prior arts are seldom discussed under distribution shifts, which may be vulnerable in real-world applications. Recent Vision-Language Foundation Models, e.g., CLIP, have demonstrated remarkable performance in zero-shot out-of-distribution generalization, yet consuming heavy computation resources. In this paper, we discuss the extension of DFKD to Vision-Language Foundation Models without access to the billion-level image-text datasets. The objective is to customize a student model for distribution-agnostic downstream tasks with given category concepts, inheriting the out-of-distribution generalization capability from the pre-trained foundation models. In order to avoid generalization degradation, the primary challenge of this task lies in synthesizing diverse surrogate images driven by text prompts. Since not only category concepts but also style information are encoded in text prompts, we propose three novel Prompt Diversification methods to encourage image synthesis with diverse styles, namely Mix-Prompt, Random-Prompt, and Contrastive-Prompt. Experiments on out-of-distribution generalization datasets demonstrate the effectiveness of the proposed methods, with Contrastive-Prompt performing the best.
Arbitrary-Scale Point Cloud Upsampling by Voxel-Based Network with Latent Geometric-Consistent Learning
Mar 08, 2024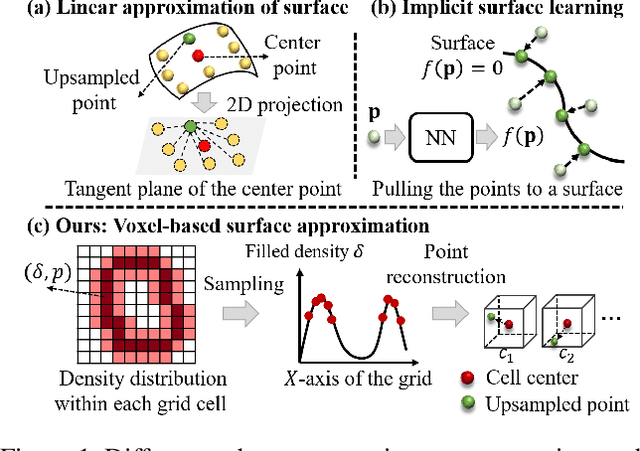
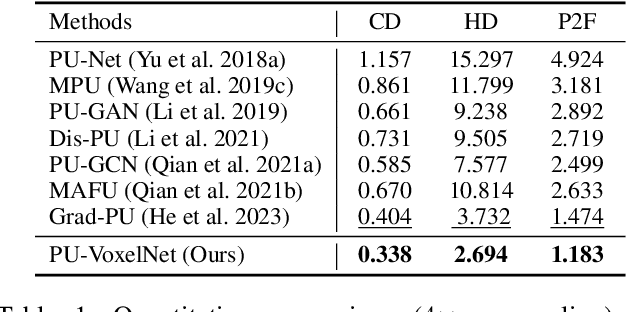
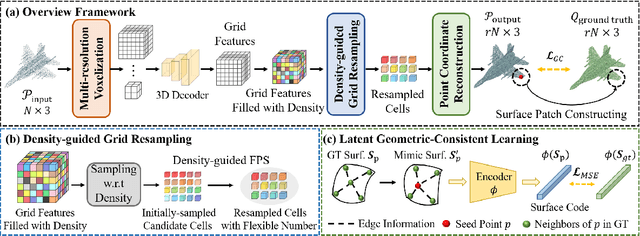
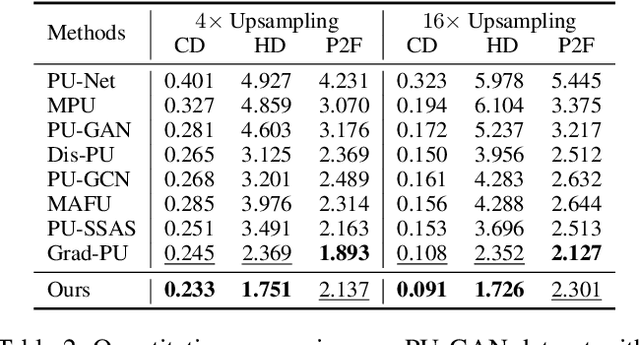
Recently, arbitrary-scale point cloud upsampling mechanism became increasingly popular due to its efficiency and convenience for practical applications. To achieve this, most previous approaches formulate it as a problem of surface approximation and employ point-based networks to learn surface representations. However, learning surfaces from sparse point clouds is more challenging, and thus they often suffer from the low-fidelity geometry approximation. To address it, we propose an arbitrary-scale Point cloud Upsampling framework using Voxel-based Network (\textbf{PU-VoxelNet}). Thanks to the completeness and regularity inherited from the voxel representation, voxel-based networks are capable of providing predefined grid space to approximate 3D surface, and an arbitrary number of points can be reconstructed according to the predicted density distribution within each grid cell. However, we investigate the inaccurate grid sampling caused by imprecise density predictions. To address this issue, a density-guided grid resampling method is developed to generate high-fidelity points while effectively avoiding sampling outliers. Further, to improve the fine-grained details, we present an auxiliary training supervision to enforce the latent geometric consistency among local surface patches. Extensive experiments indicate the proposed approach outperforms the state-of-the-art approaches not only in terms of fixed upsampling rates but also for arbitrary-scale upsampling.
CLIP-Gaze: Towards General Gaze Estimation via Visual-Linguistic Model
Mar 08, 2024Gaze estimation methods often experience significant performance degradation when evaluated across different domains, due to the domain gap between the testing and training data. Existing methods try to address this issue using various domain generalization approaches, but with little success because of the limited diversity of gaze datasets, such as appearance, wearable, and image quality. To overcome these limitations, we propose a novel framework called CLIP-Gaze that utilizes a pre-trained vision-language model to leverage its transferable knowledge. Our framework is the first to leverage the vision-and-language cross-modality approach for gaze estimation task. Specifically, we extract gaze-relevant feature by pushing it away from gaze-irrelevant features which can be flexibly constructed via language descriptions. To learn more suitable prompts, we propose a personalized context optimization method for text prompt tuning. Furthermore, we utilize the relationship among gaze samples to refine the distribution of gaze-relevant features, thereby improving the generalization capability of the gaze estimation model. Extensive experiments demonstrate the excellent performance of CLIP-Gaze over existing methods on four cross-domain evaluations.
Learning Expressive And Generalizable Motion Features For Face Forgery Detection
Mar 08, 2024Previous face forgery detection methods mainly focus on appearance features, which may be easily attacked by sophisticated manipulation. Considering the majority of current face manipulation methods generate fake faces based on a single frame, which do not take frame consistency and coordination into consideration, artifacts on frame sequences are more effective for face forgery detection. However, current sequence-based face forgery detection methods use general video classification networks directly, which discard the special and discriminative motion information for face manipulation detection. To this end, we propose an effective sequence-based forgery detection framework based on an existing video classification method. To make the motion features more expressive for manipulation detection, we propose an alternative motion consistency block instead of the original motion features module. To make the learned features more generalizable, we propose an auxiliary anomaly detection block. With these two specially designed improvements, we make a general video classification network achieve promising results on three popular face forgery datasets.
"Lossless" Compression of Deep Neural Networks: A High-dimensional Neural Tangent Kernel Approach
Mar 01, 2024Modern deep neural networks (DNNs) are extremely powerful; however, this comes at the price of increased depth and having more parameters per layer, making their training and inference more computationally challenging. In an attempt to address this key limitation, efforts have been devoted to the compression (e.g., sparsification and/or quantization) of these large-scale machine learning models, so that they can be deployed on low-power IoT devices. In this paper, building upon recent advances in neural tangent kernel (NTK) and random matrix theory (RMT), we provide a novel compression approach to wide and fully-connected \emph{deep} neural nets. Specifically, we demonstrate that in the high-dimensional regime where the number of data points $n$ and their dimension $p$ are both large, and under a Gaussian mixture model for the data, there exists \emph{asymptotic spectral equivalence} between the NTK matrices for a large family of DNN models. This theoretical result enables "lossless" compression of a given DNN to be performed, in the sense that the compressed network yields asymptotically the same NTK as the original (dense and unquantized) network, with its weights and activations taking values \emph{only} in $\{ 0, \pm 1 \}$ up to a scaling. Experiments on both synthetic and real-world data are conducted to support the advantages of the proposed compression scheme, with code available at \url{https://github.com/Model-Compression/Lossless_Compression}.
Adapt Anything: Tailor Any Image Classifiers across Domains And Categories Using Text-to-Image Diffusion Models
Oct 25, 2023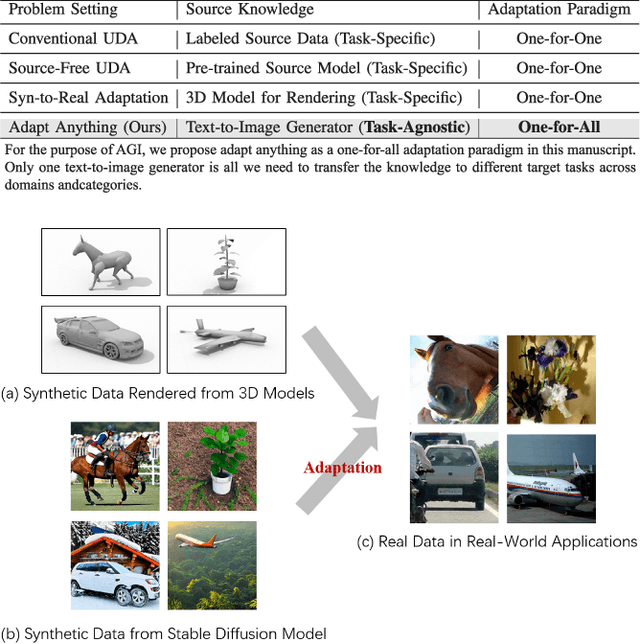

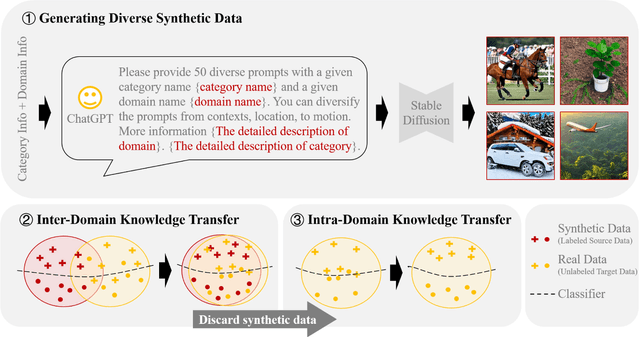
We do not pursue a novel method in this paper, but aim to study if a modern text-to-image diffusion model can tailor any task-adaptive image classifier across domains and categories. Existing domain adaptive image classification works exploit both source and target data for domain alignment so as to transfer the knowledge learned from the labeled source data to the unlabeled target data. However, as the development of the text-to-image diffusion model, we wonder if the high-fidelity synthetic data from the text-to-image generator can serve as a surrogate of the source data in real world. In this way, we do not need to collect and annotate the source data for each domain adaptation task in a one-for-one manner. Instead, we utilize only one off-the-shelf text-to-image model to synthesize images with category labels derived from the corresponding text prompts, and then leverage the surrogate data as a bridge to transfer the knowledge embedded in the task-agnostic text-to-image generator to the task-oriented image classifier via domain adaptation. Such a one-for-all adaptation paradigm allows us to adapt anything in the world using only one text-to-image generator as well as the corresponding unlabeled target data. Extensive experiments validate the feasibility of the proposed idea, which even surpasses the state-of-the-art domain adaptation works using the source data collected and annotated in real world.