 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle Domain Dynamic Generalization for Iris Presentation Attack Detection
May 22, 2023Iris presentation attack detection (PAD) has achieved great success under intra-domain settings but easily degrades on unseen domains. Conventional domain generalization methods mitigate the gap by learning domain-invariant features. However, they ignore the discriminative information in the domain-specific features. Moreover, we usually face a more realistic scenario with only one single domain available for training. To tackle the above issues, we propose a Single Domain Dynamic Generalization (SDDG) framework, which simultaneously exploits domain-invariant and domain-specific features on a per-sample basis and learns to generalize to various unseen domains with numerous natural images. Specifically, a dynamic block is designed to adaptively adjust the network with a dynamic adaptor. And an information maximization loss is further combined to increase diversity. The whole network is integrated into the meta-learning paradigm. We generate amplitude perturbed images and cover diverse domains with natural images. Therefore, the network can learn to generalize to the perturbed domains in the meta-test phase. Extensive experiments show the proposed method is effective and outperforms the state-of-the-art on LivDet-Iris 2017 dataset.
Few-shot One-class Domain Adaptation Based on Frequency for Iris Presentation Attack Detection
Apr 01, 2022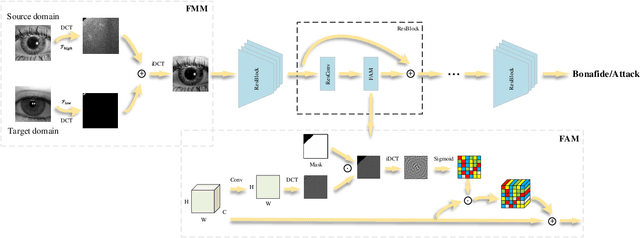
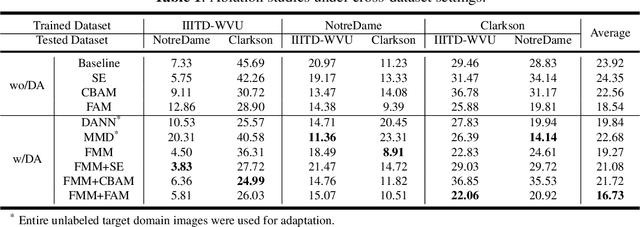
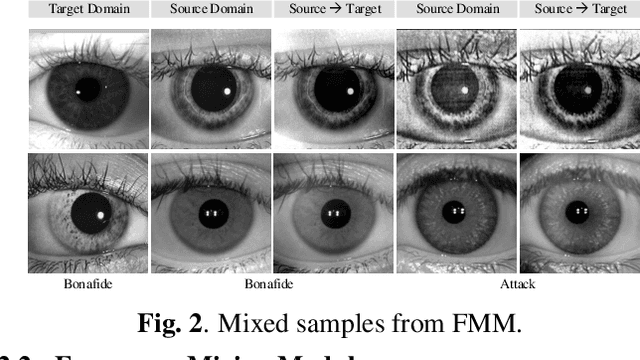
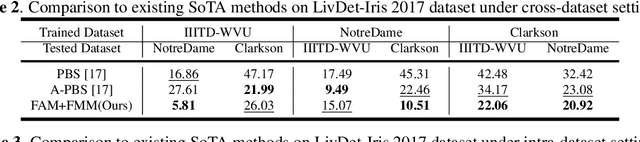
Iris presentation attack detection (PAD) has achieved remarkable success to ensure the reliability and security of iris recognition systems. Most existing methods exploit discriminative features in the spatial domain and report outstanding performance under intra-dataset settings. However, the degradation of performance is inevitable under cross-dataset settings, suffering from domain shift. In consideration of real-world applications, a small number of bonafide samples are easily accessible. We thus define a new domain adaptation setting called Few-shot One-class Domain Adaptation (FODA), where adaptation only relies on a limited number of target bonafide samples. To address this problem, we propose a novel FODA framework based on the expressive power of frequency information. Specifically, our method integrates frequency-related information through two proposed modules. Frequency-based Attention Module (FAM) aggregates frequency information into spatial attention and explicitly emphasizes high-frequency fine-grained features. Frequency Mixing Module (FMM) mixes certain frequency components to generate large-scale target-style samples for adaptation with limited target bonafide samples. Extensive experiments on LivDet-Iris 2017 dataset demonstrate the proposed method achieves state-of-the-art or competitive performance under both cross-dataset and intra-dataset settings.
Unimodal-Concentrated Loss: Fully Adaptive Label Distribution Learning for Ordinal Regression
Apr 01, 2022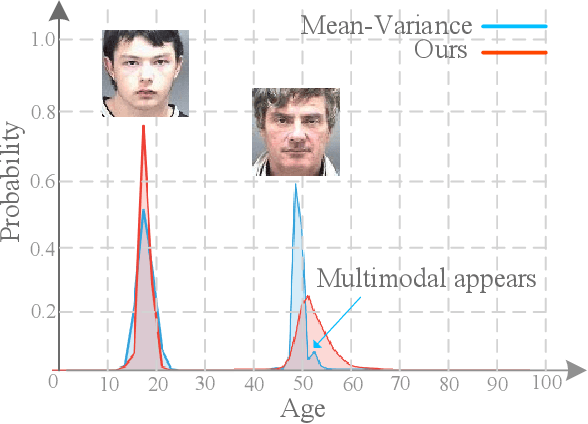
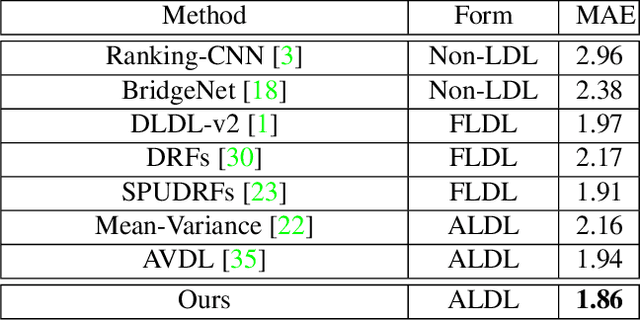
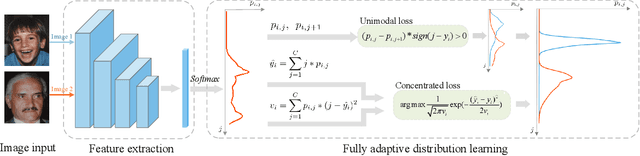
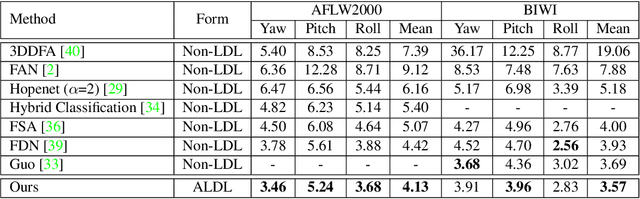
Learning from a label distribution has achieved promising results on ordinal regression tasks such as facial age and head pose estimation wherein, the concept of adaptive label distribution learning (ALDL) has drawn lots of attention recently for its superiority in theory. However, compared with the methods assuming fixed form label distribution, ALDL methods have not achieved better performance. We argue that existing ALDL algorithms do not fully exploit the intrinsic properties of ordinal regression. In this paper, we emphatically summarize that learning an adaptive label distribution on ordinal regression tasks should follow three principles. First, the probability corresponding to the ground-truth should be the highest in label distribution. Second, the probabilities of neighboring labels should decrease with the increase of distance away from the ground-truth, i.e., the distribution is unimodal. Third, the label distribution should vary with samples changing, and even be distinct for different instances with the same label, due to the different levels of difficulty and ambiguity. Under the premise of these principles, we propose a novel loss function for fully adaptive label distribution learning, namely unimodal-concentrated loss. Specifically, the unimodal loss derived from the learning to rank strategy constrains the distribution to be unimodal. Furthermore, the estimation error and the variance of the predicted distribution for a specific sample are integrated into the proposed concentrated loss to make the predicted distribution maximize at the ground-truth and vary according to the predicting uncertainty. Extensive experimental results on typical ordinal regression tasks including age and head pose estimation, show the superiority of our proposed unimodal-concentrated loss compared with existing loss functions.
Re-Identification Supervised Texture Generation
Apr 06, 2019



The estimation of 3D human body pose and shape from a single image has been extensively studied in recent years. However, the texture generation problem has not been fully discussed. In this paper, we propose an end-to-end learning strategy to generate textures of human bodies under the supervision of person re-identification. We render the synthetic images with textures extracted from the inputs and maximize the similarity between the rendered and input images by using the re-identification network as the perceptual metrics. Experiment results on pedestrian images show that our model can generate the texture from a single image and demonstrate that our textures are of higher quality than those generated by other available methods. Furthermore, we extend the application scope to other categories and explore the possible utilization of our generated textures.