 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Scale Wavelet Transformer for Face Forgery Detection
Oct 08, 2022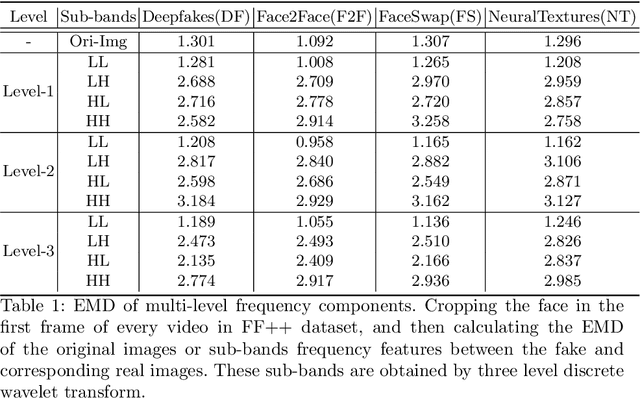


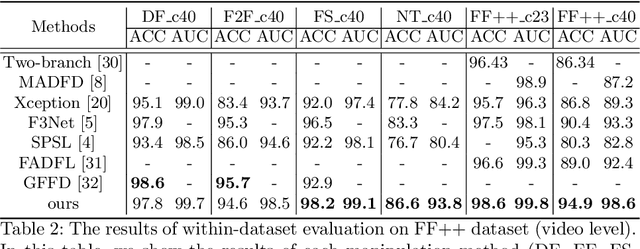
Currently, many face forgery detection methods aggregate spatial and frequency features to enhance the generalization ability and gain promising performance under the cross-dataset scenario. However, these methods only leverage one level frequency information which limits their expressive ability. To overcome these limitations, we propose a multi-scale wavelet transformer framework for face forgery detection. Specifically, to take full advantage of the multi-scale and multi-frequency wavelet representation, we gradually aggregate the multi-scale wavelet representation at different stages of the backbone network. To better fuse the frequency feature with the spatial features, frequency-based spatial attention is designed to guide the spatial feature extractor to concentrate more on forgery traces. Meanwhile, cross-modality attention is proposed to fuse the frequency features with the spatial features. These two attention modules are calculated through a unified transformer block for efficiency. A wide variety of experiments demonstrate that the proposed method is efficient and effective for both within and cross datasets.
Weakly Supervised Regional and Temporal Learning for Facial Action Unit Recognition
Apr 01, 2022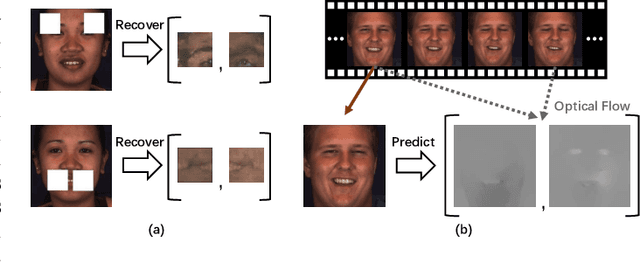
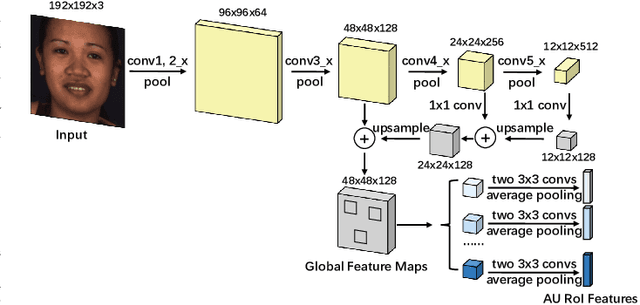
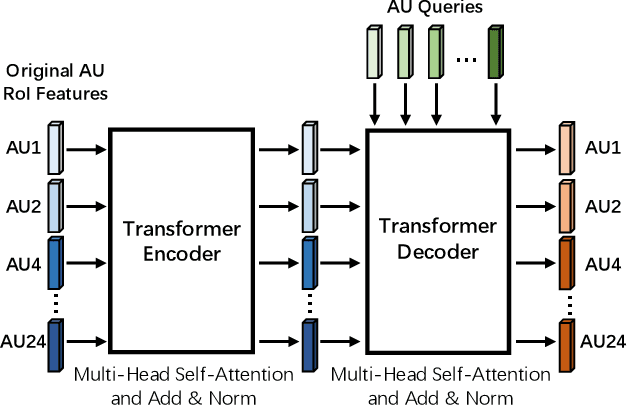
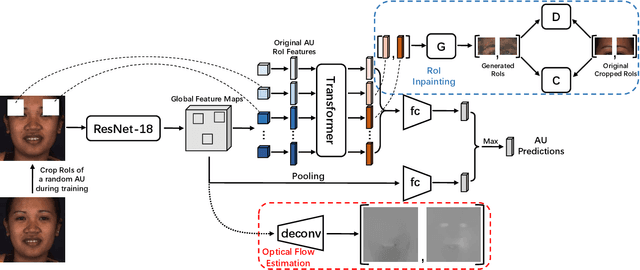
Automatic facial action unit (AU) recognition is a challenging task due to the scarcity of manual annotations. To alleviate this problem, a large amount of efforts has been dedicated to exploiting various weakly supervised methods which leverage numerous unlabeled data. However, many aspects with regard to some unique properties of AUs, such as the regional and relational characteristics, are not sufficiently explored in previous works. Motivated by this, we take the AU properties into consideration and propose two auxiliary AU related tasks to bridge the gap between limited annotations and the model performance in a self-supervised manner via the unlabeled data. Specifically, to enhance the discrimination of regional features with AU relation embedding, we design a task of RoI inpainting to recover the randomly cropped AU patches. Meanwhile, a single image based optical flow estimation task is proposed to leverage the dynamic change of facial muscles and encode the motion information into the global feature representation. Based on these two self-supervised auxiliary tasks, local features, mutual relation and motion cues of AUs are better captured in the backbone network. Furthermore, by incorporating semi-supervised learning, we propose an end-to-end trainable framework named weakly supervised regional and temporal learning (WSRTL) for AU recognition. Extensive experiments on BP4D and DISFA demonstrate the superiority of our method and new state-of-the-art performances are achieved.
Few-shot One-class Domain Adaptation Based on Frequency for Iris Presentation Attack Detection
Apr 01, 2022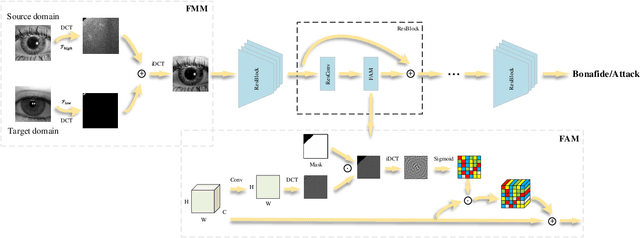
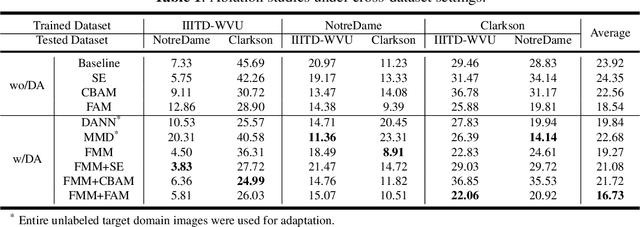
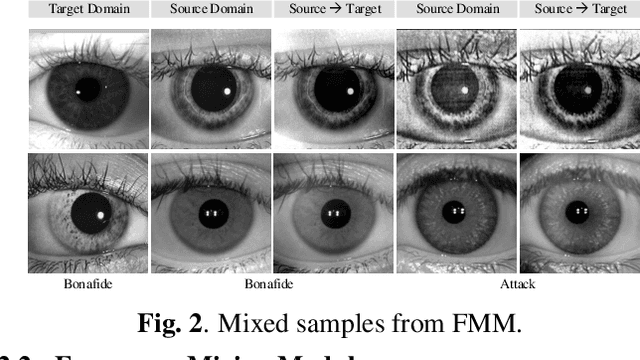
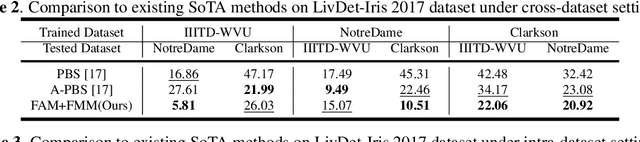
Iris presentation attack detection (PAD) has achieved remarkable success to ensure the reliability and security of iris recognition systems. Most existing methods exploit discriminative features in the spatial domain and report outstanding performance under intra-dataset settings. However, the degradation of performance is inevitable under cross-dataset settings, suffering from domain shift. In consideration of real-world applications, a small number of bonafide samples are easily accessible. We thus define a new domain adaptation setting called Few-shot One-class Domain Adaptation (FODA), where adaptation only relies on a limited number of target bonafide samples. To address this problem, we propose a novel FODA framework based on the expressive power of frequency information. Specifically, our method integrates frequency-related information through two proposed modules. Frequency-based Attention Module (FAM) aggregates frequency information into spatial attention and explicitly emphasizes high-frequency fine-grained features. Frequency Mixing Module (FMM) mixes certain frequency components to generate large-scale target-style samples for adaptation with limited target bonafide samples. Extensive experiments on LivDet-Iris 2017 dataset demonstrate the proposed method achieves state-of-the-art or competitive performance under both cross-dataset and intra-dataset settings.
Unimodal-Concentrated Loss: Fully Adaptive Label Distribution Learning for Ordinal Regression
Apr 01, 2022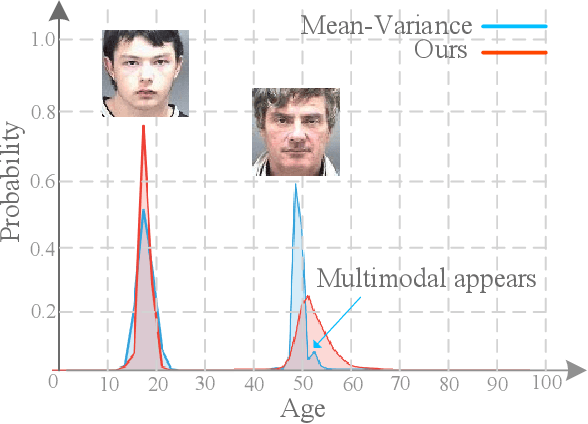
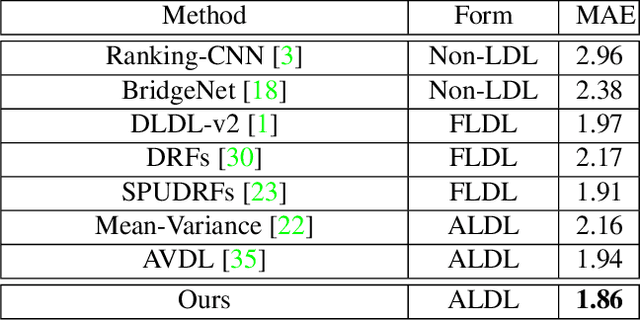
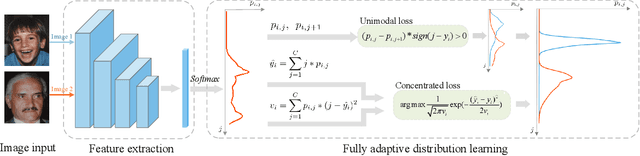
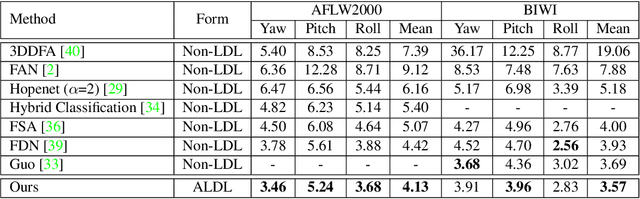
Learning from a label distribution has achieved promising results on ordinal regression tasks such as facial age and head pose estimation wherein, the concept of adaptive label distribution learning (ALDL) has drawn lots of attention recently for its superiority in theory. However, compared with the methods assuming fixed form label distribution, ALDL methods have not achieved better performance. We argue that existing ALDL algorithms do not fully exploit the intrinsic properties of ordinal regression. In this paper, we emphatically summarize that learning an adaptive label distribution on ordinal regression tasks should follow three principles. First, the probability corresponding to the ground-truth should be the highest in label distribution. Second, the probabilities of neighboring labels should decrease with the increase of distance away from the ground-truth, i.e., the distribution is unimodal. Third, the label distribution should vary with samples changing, and even be distinct for different instances with the same label, due to the different levels of difficulty and ambiguity. Under the premise of these principles, we propose a novel loss function for fully adaptive label distribution learning, namely unimodal-concentrated loss. Specifically, the unimodal loss derived from the learning to rank strategy constrains the distribution to be unimodal. Furthermore, the estimation error and the variance of the predicted distribution for a specific sample are integrated into the proposed concentrated loss to make the predicted distribution maximize at the ground-truth and vary according to the predicting uncertainty. Extensive experimental results on typical ordinal regression tasks including age and head pose estimation, show the superiority of our proposed unimodal-concentrated loss compared with existing loss functions.
Learning Multiple Explainable and Generalizable Cues for Face Anti-spoofing
Feb 21, 2022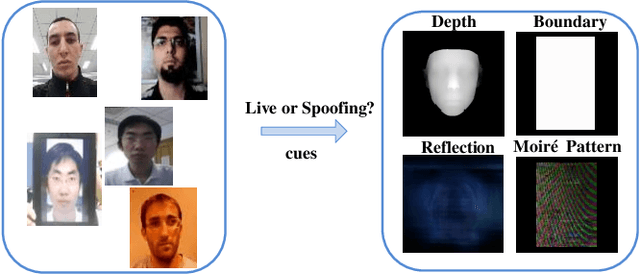
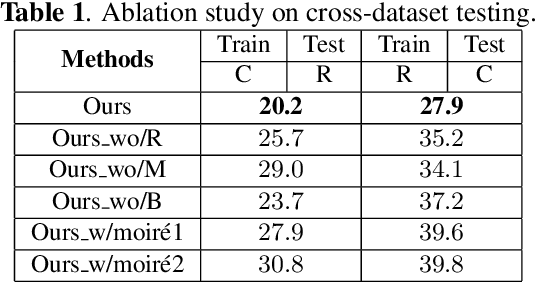
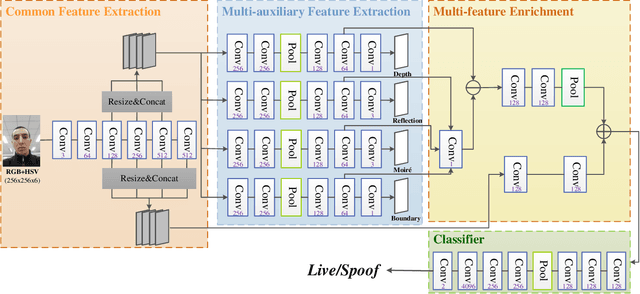
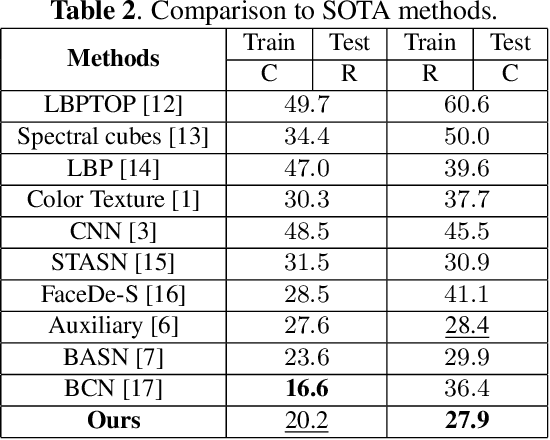
Although previous CNN based face anti-spoofing methods have achieved promising performance under intra-dataset testing, they suffer from poor generalization under cross-dataset testing. The main reason is that they learn the network with only binary supervision, which may learn arbitrary cues overfitting on the training dataset. To make the learned feature explainable and more generalizable, some researchers introduce facial depth and reflection map as the auxiliary supervision. However, many other generalizable cues are unexplored for face anti-spoofing, which limits their performance under cross-dataset testing. To this end, we propose a novel framework to learn multiple explainable and generalizable cues (MEGC) for face anti-spoofing. Specifically, inspired by the process of human decision, four mainly used cues by humans are introduced as auxiliary supervision including the boundary of spoof medium, moir\'e pattern, reflection artifacts and facial depth in addition to the binary supervision. To avoid extra labelling cost, corresponding synthetic methods are proposed to generate these auxiliary supervision maps. Extensive experiments on public datasets validate the effectiveness of these cues, and state-of-the-art performances are achieved by our proposed method.
Self-Supervised Regional and Temporal Auxiliary Tasks for Facial Action Unit Recognition
Jul 30, 2021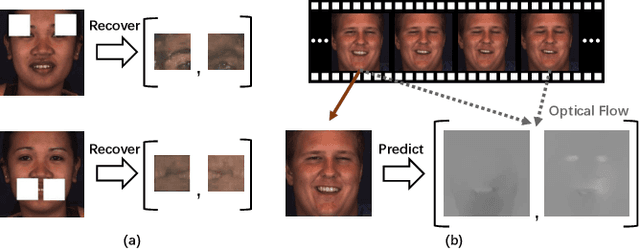
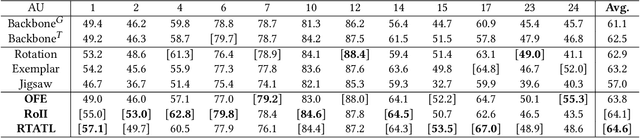
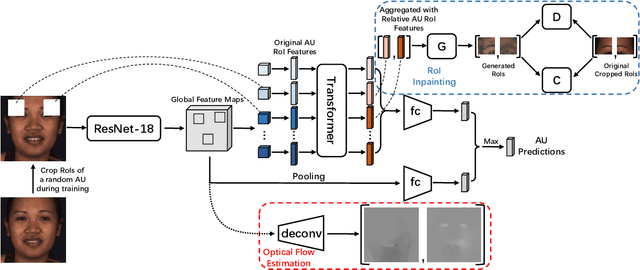
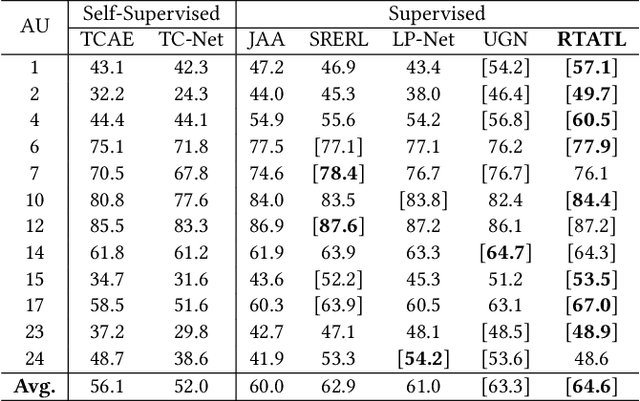
Automatic facial action unit (AU) recognition is a challenging task due to the scarcity of manual annotations. To alleviate this problem, a large amount of efforts has been dedicated to exploiting various methods which leverage numerous unlabeled data. However, many aspects with regard to some unique properties of AUs, such as the regional and relational characteristics, are not sufficiently explored in previous works. Motivated by this, we take the AU properties into consideration and propose two auxiliary AU related tasks to bridge the gap between limited annotations and the model performance in a self-supervised manner via the unlabeled data. Specifically, to enhance the discrimination of regional features with AU relation embedding, we design a task of RoI inpainting to recover the randomly cropped AU patches. Meanwhile, a single image based optical flow estimation task is proposed to leverage the dynamic change of facial muscles and encode the motion information into the global feature representation. Based on these two self-supervised auxiliary tasks, local features, mutual relation and motion cues of AUs are better captured in the backbone network with the proposed regional and temporal based auxiliary task learning (RTATL) framework. Extensive experiments on BP4D and DISFA demonstrate the superiority of our method and new state-of-the-art performances are achieved.
Multi-Level Adaptive Region of Interest and Graph Learning for Facial Action Unit Recognition
Feb 24, 2021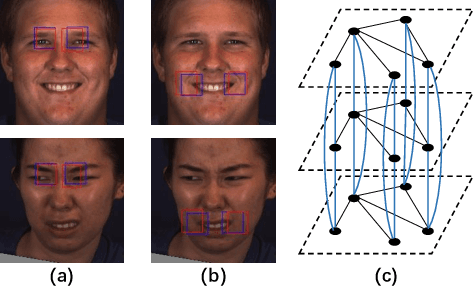

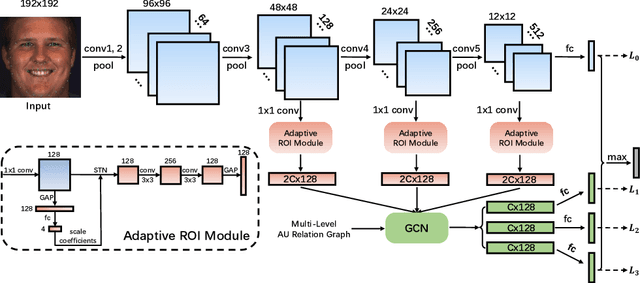
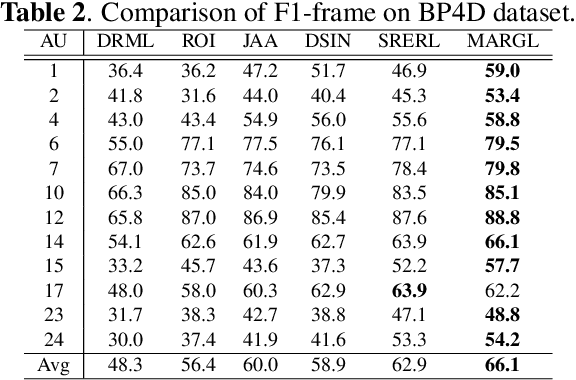
In facial action unit (AU) recognition tasks, regional feature learning and AU relation modeling are two effective aspects which are worth exploring. However, the limited representation capacity of regional features makes it difficult for relation models to embed AU relationship knowledge. In this paper, we propose a novel multi-level adaptive ROI and graph learning (MARGL) framework to tackle this problem. Specifically, an adaptive ROI learning module is designed to automatically adjust the location and size of the predefined AU regions. Meanwhile, besides relationship between AUs, there exists strong relevance between regional features across multiple levels of the backbone network as level-wise features focus on different aspects of representation. In order to incorporate the intra-level AU relation and inter-level AU regional relevance simultaneously, a multi-level AU relation graph is constructed and graph convolution is performed to further enhance AU regional features of each level. Experiments on BP4D and DISFA demonstrate the proposed MARGL significantly outperforms the previous state-of-the-art methods.
Self-Domain Adaptation for Face Anti-Spoofing
Feb 24, 2021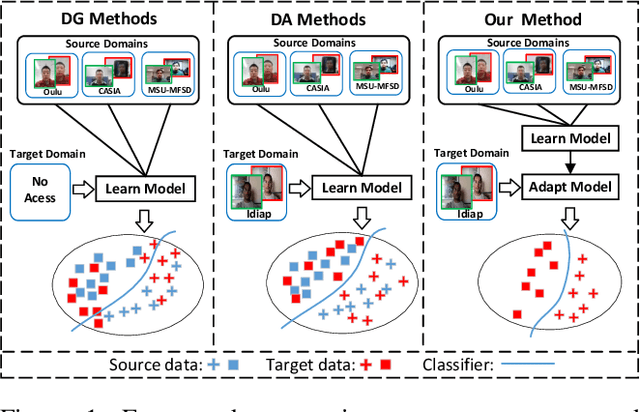
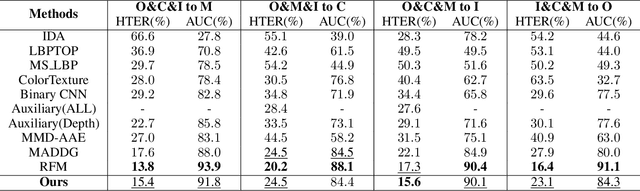
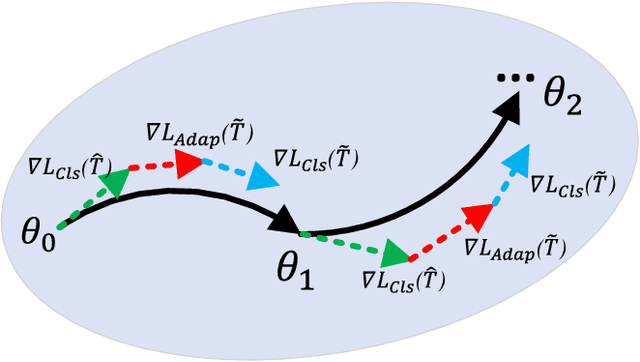

Although current face anti-spoofing methods achieve promising results under intra-dataset testing, they suffer from poor generalization to unseen attacks. Most existing works adopt domain adaptation (DA) or domain generalization (DG) techniques to address this problem. However, the target domain is often unknown during training which limits the utilization of DA methods. DG methods can conquer this by learning domain invariant features without seeing any target data. However, they fail in utilizing the information of target data. In this paper, we propose a self-domain adaptation framework to leverage the unlabeled test domain data at inference. Specifically, a domain adaptor is designed to adapt the model for test domain. In order to learn a better adaptor, a meta-learning based adaptor learning algorithm is proposed using the data of multiple source domains at the training step. At test time, the adaptor is updated using only the test domain data according to the proposed unsupervised adaptor loss to further improve the performance. Extensive experiments on four public datasets validate the effectiveness of the proposed method.