 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Regional and Temporal Learning for Facial Action Unit Recognition
Apr 01, 2022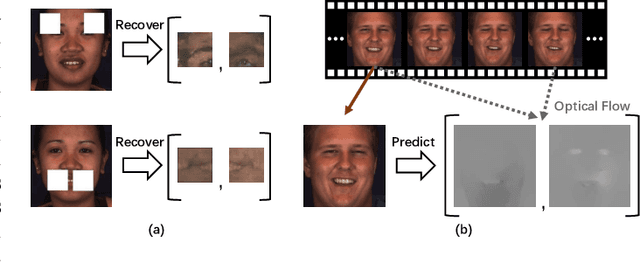
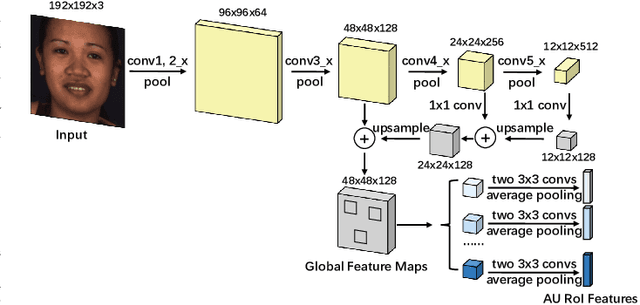
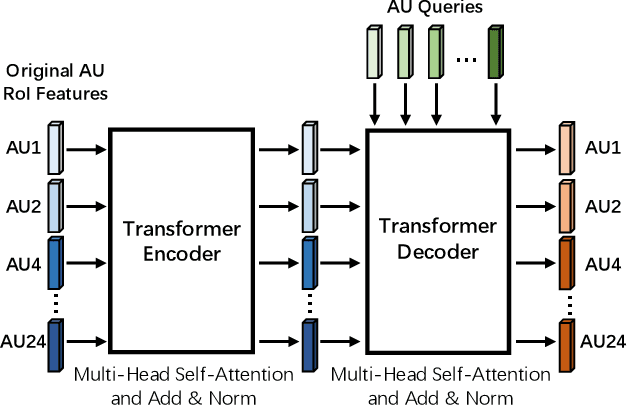
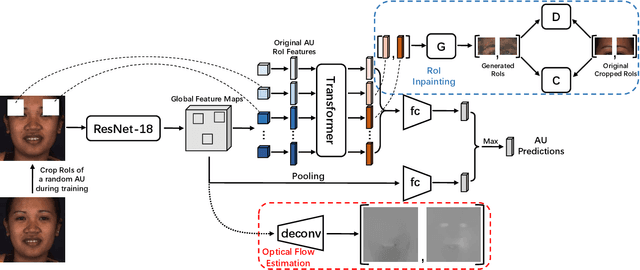
Automatic facial action unit (AU) recognition is a challenging task due to the scarcity of manual annotations. To alleviate this problem, a large amount of efforts has been dedicated to exploiting various weakly supervised methods which leverage numerous unlabeled data. However, many aspects with regard to some unique properties of AUs, such as the regional and relational characteristics, are not sufficiently explored in previous works. Motivated by this, we take the AU properties into consideration and propose two auxiliary AU related tasks to bridge the gap between limited annotations and the model performance in a self-supervised manner via the unlabeled data. Specifically, to enhance the discrimination of regional features with AU relation embedding, we design a task of RoI inpainting to recover the randomly cropped AU patches. Meanwhile, a single image based optical flow estimation task is proposed to leverage the dynamic change of facial muscles and encode the motion information into the global feature representation. Based on these two self-supervised auxiliary tasks, local features, mutual relation and motion cues of AUs are better captured in the backbone network. Furthermore, by incorporating semi-supervised learning, we propose an end-to-end trainable framework named weakly supervised regional and temporal learning (WSRTL) for AU recognition. Extensive experiments on BP4D and DISFA demonstrate the superiority of our method and new state-of-the-art performances are achieved.
Unimodal-Concentrated Loss: Fully Adaptive Label Distribution Learning for Ordinal Regression
Apr 01, 2022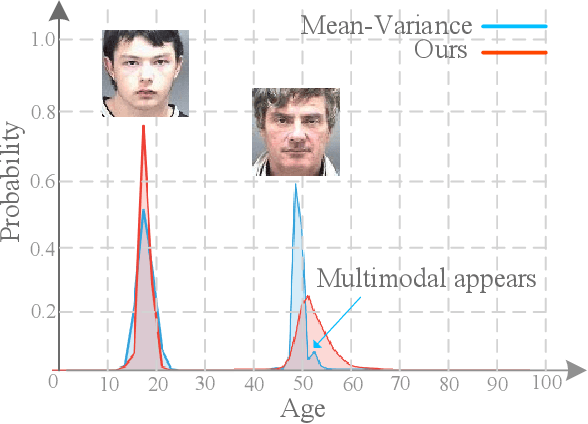
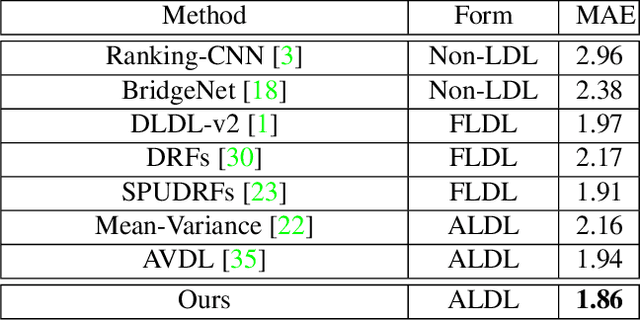
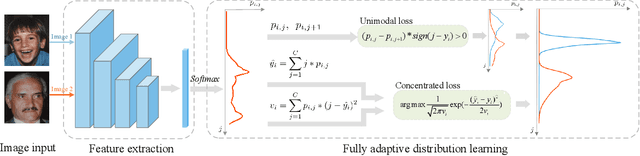
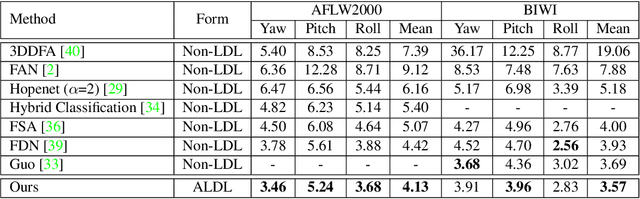
Learning from a label distribution has achieved promising results on ordinal regression tasks such as facial age and head pose estimation wherein, the concept of adaptive label distribution learning (ALDL) has drawn lots of attention recently for its superiority in theory. However, compared with the methods assuming fixed form label distribution, ALDL methods have not achieved better performance. We argue that existing ALDL algorithms do not fully exploit the intrinsic properties of ordinal regression. In this paper, we emphatically summarize that learning an adaptive label distribution on ordinal regression tasks should follow three principles. First, the probability corresponding to the ground-truth should be the highest in label distribution. Second, the probabilities of neighboring labels should decrease with the increase of distance away from the ground-truth, i.e., the distribution is unimodal. Third, the label distribution should vary with samples changing, and even be distinct for different instances with the same label, due to the different levels of difficulty and ambiguity. Under the premise of these principles, we propose a novel loss function for fully adaptive label distribution learning, namely unimodal-concentrated loss. Specifically, the unimodal loss derived from the learning to rank strategy constrains the distribution to be unimodal. Furthermore, the estimation error and the variance of the predicted distribution for a specific sample are integrated into the proposed concentrated loss to make the predicted distribution maximize at the ground-truth and vary according to the predicting uncertainty. Extensive experimental results on typical ordinal regression tasks including age and head pose estimation, show the superiority of our proposed unimodal-concentrated loss compared with existing loss functions.
Self-Supervised Regional and Temporal Auxiliary Tasks for Facial Action Unit Recognition
Jul 30, 2021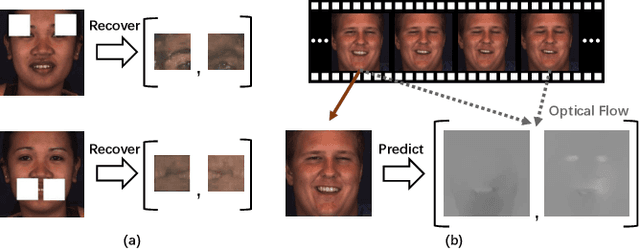
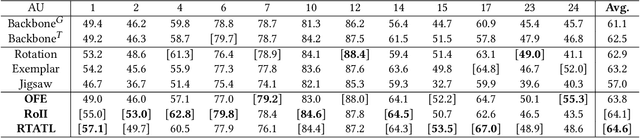
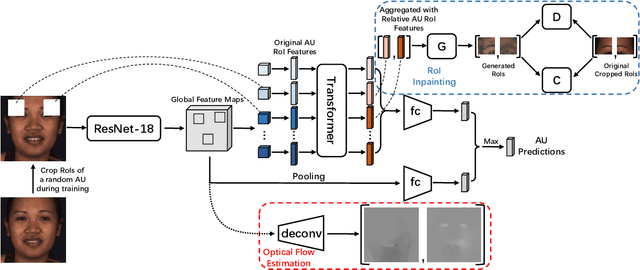
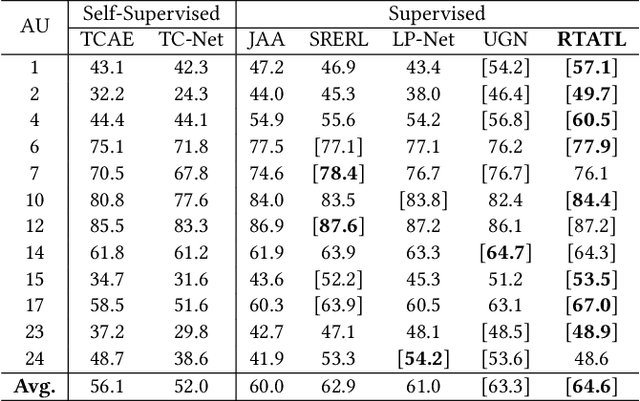
Automatic facial action unit (AU) recognition is a challenging task due to the scarcity of manual annotations. To alleviate this problem, a large amount of efforts has been dedicated to exploiting various methods which leverage numerous unlabeled data. However, many aspects with regard to some unique properties of AUs, such as the regional and relational characteristics, are not sufficiently explored in previous works. Motivated by this, we take the AU properties into consideration and propose two auxiliary AU related tasks to bridge the gap between limited annotations and the model performance in a self-supervised manner via the unlabeled data. Specifically, to enhance the discrimination of regional features with AU relation embedding, we design a task of RoI inpainting to recover the randomly cropped AU patches. Meanwhile, a single image based optical flow estimation task is proposed to leverage the dynamic change of facial muscles and encode the motion information into the global feature representation. Based on these two self-supervised auxiliary tasks, local features, mutual relation and motion cues of AUs are better captured in the backbone network with the proposed regional and temporal based auxiliary task learning (RTATL) framework. Extensive experiments on BP4D and DISFA demonstrate the superiority of our method and new state-of-the-art performances are achieved.
Multi-Level Adaptive Region of Interest and Graph Learning for Facial Action Unit Recognition
Feb 24, 2021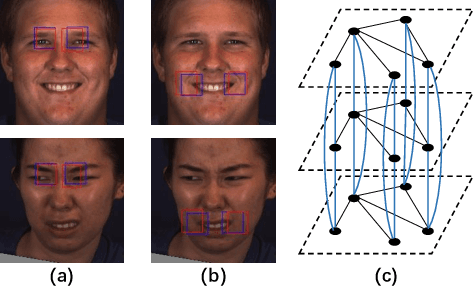

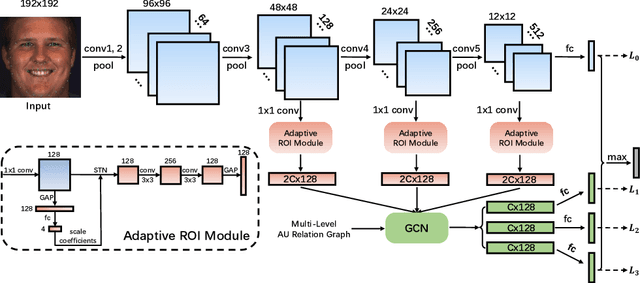
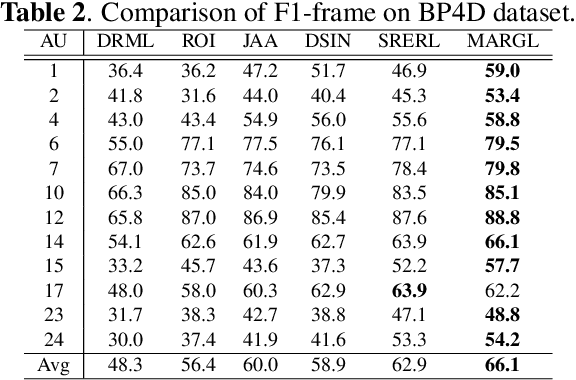
In facial action unit (AU) recognition tasks, regional feature learning and AU relation modeling are two effective aspects which are worth exploring. However, the limited representation capacity of regional features makes it difficult for relation models to embed AU relationship knowledge. In this paper, we propose a novel multi-level adaptive ROI and graph learning (MARGL) framework to tackle this problem. Specifically, an adaptive ROI learning module is designed to automatically adjust the location and size of the predefined AU regions. Meanwhile, besides relationship between AUs, there exists strong relevance between regional features across multiple levels of the backbone network as level-wise features focus on different aspects of representation. In order to incorporate the intra-level AU relation and inter-level AU regional relevance simultaneously, a multi-level AU relation graph is constructed and graph convolution is performed to further enhance AU regional features of each level. Experiments on BP4D and DISFA demonstrate the proposed MARGL significantly outperforms the previous state-of-the-art methods.