 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurvey of Vision-Language-Action Models for Embodied Manipulation
Aug 21, 2025Embodied intelligence systems, which enhance agent capabilities through continuous environment interactions, have garnered significant attention from both academia and industry. Vision-Language-Action models, inspired by advancements in large foundation models, serve as universal robotic control frameworks that substantially improve agent-environment interaction capabilities in embodied intelligence systems. This expansion has broadened application scenarios for embodied AI robots. This survey comprehensively reviews VLA models for embodied manipulation. Firstly, it chronicles the developmental trajectory of VLA architectures. Subsequently, we conduct a detailed analysis of current research across 5 critical dimensions: VLA model structures, training datasets, pre-training methods, post-training methods, and model evaluation. Finally, we synthesize key challenges in VLA development and real-world deployment, while outlining promising future research directions.
LPO: Towards Accurate GUI Agent Interaction via Location Preference Optimization
Jun 11, 2025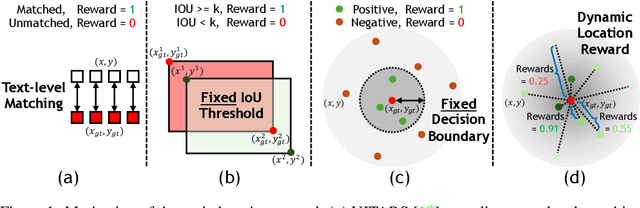
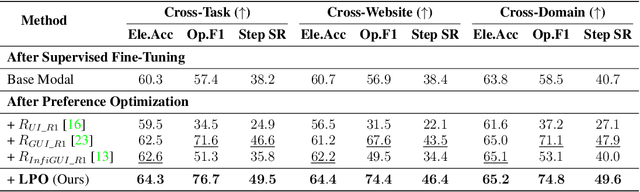
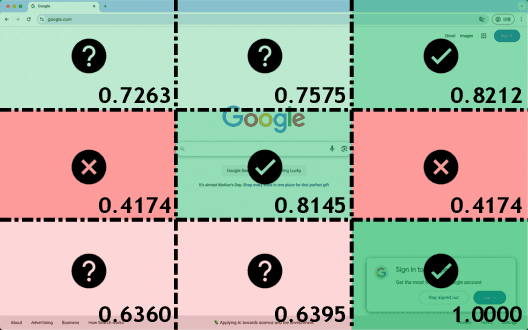
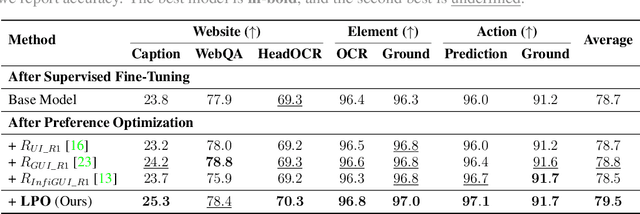
The advent of autonomous agents is transforming interactions with Graphical User Interfaces (GUIs) by employing natural language as a powerful intermediary. Despite the predominance of Supervised Fine-Tuning (SFT) methods in current GUI agents for achieving spatial localization, these methods face substantial challenges due to their limited capacity to accurately perceive positional data. Existing strategies, such as reinforcement learning, often fail to assess positional accuracy effectively, thereby restricting their utility. In response, we introduce Location Preference Optimization (LPO), a novel approach that leverages locational data to optimize interaction preferences. LPO uses information entropy to predict interaction positions by focusing on zones rich in information. Besides, it further introduces a dynamic location reward function based on physical distance, reflecting the varying importance of interaction positions. Supported by Group Relative Preference Optimization (GRPO), LPO facilitates an extensive exploration of GUI environments and significantly enhances interaction precision. Comprehensive experiments demonstrate LPO's superior performance, achieving SOTA results across both offline benchmarks and real-world online evaluations. Our code will be made publicly available soon, at https://github.com/AIDC-AI/LPO.
TeViR: Text-to-Video Reward with Diffusion Models for Efficient Reinforcement Learning
May 26, 2025Developing scalable and generalizable reward engineering for reinforcement learning (RL) is crucial for creating general-purpose agents, especially in the challenging domain of robotic manipulation. While recent advances in reward engineering with Vision-Language Models (VLMs) have shown promise, their sparse reward nature significantly limits sample efficiency. This paper introduces TeViR, a novel method that leverages a pre-trained text-to-video diffusion model to generate dense rewards by comparing the predicted image sequence with current observations. Experimental results across 11 complex robotic tasks demonstrate that TeViR outperforms traditional methods leveraging sparse rewards and other state-of-the-art (SOTA) methods, achieving better sample efficiency and performance without ground truth environmental rewards. TeViR's ability to efficiently guide agents in complex environments highlights its potential to advance reinforcement learning applications in robotic manipulation.
ConRFT: A Reinforced Fine-tuning Method for VLA Models via Consistency Policy
Feb 08, 2025



Vision-Language-Action (VLA) models have shown substantial potential in real-world robotic manipulation. However, fine-tuning these models through supervised learning struggles to achieve robust performance due to limited, inconsistent demonstrations, especially in contact-rich environments. In this paper, we propose a reinforced fine-tuning approach for VLA models, named ConRFT, which consists of offline and online fine-tuning with a unified consistency-based training objective, to address these challenges. In the offline stage, our method integrates behavior cloning and Q-learning to effectively extract policy from a small set of demonstrations and stabilize value estimating. In the online stage, the VLA model is further fine-tuned via consistency policy, with human interventions to ensure safe exploration and high sample efficiency. We evaluate our approach on eight diverse real-world manipulation tasks. It achieves an average success rate of 96.3% within 45-90 minutes of online fine-tuning, outperforming prior supervised methods with a 144% improvement in success rate and 1.9x shorter episode length. This work highlights the potential of integrating reinforcement learning to enhance the performance of VLA models for real-world robotic applications.
Boosting Continuous Control with Consistency Policy
Oct 10, 2023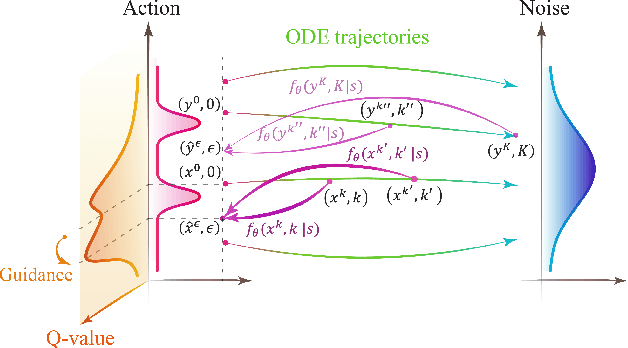



Due to its training stability and strong expression, the diffusion model has attracted considerable attention in offline reinforcement learning. However, several challenges have also come with it: 1) The demand for a large number of diffusion steps makes the diffusion-model-based methods time inefficient and limits their applications in real-time control; 2) How to achieve policy improvement with accurate guidance for diffusion model-based policy is still an open problem. Inspired by the consistency model, we propose a novel time-efficiency method named Consistency Policy with Q-Learning (CPQL), which derives action from noise by a single step. By establishing a mapping from the reverse diffusion trajectories to the desired policy, we simultaneously address the issues of time efficiency and inaccurate guidance when updating diffusion model-based policy with the learned Q-function. We demonstrate that CPQL can achieve policy improvement with accurate guidance for offline reinforcement learning, and can be seamlessly extended for online RL tasks. Experimental results indicate that CPQL achieves new state-of-the-art performance on 11 offline and 21 online tasks, significantly improving inference speed by nearly 45 times compared to Diffusion-QL. We will release our code later.
Single Domain Dynamic Generalization for Iris Presentation Attack Detection
May 22, 2023Iris presentation attack detection (PAD) has achieved great success under intra-domain settings but easily degrades on unseen domains. Conventional domain generalization methods mitigate the gap by learning domain-invariant features. However, they ignore the discriminative information in the domain-specific features. Moreover, we usually face a more realistic scenario with only one single domain available for training. To tackle the above issues, we propose a Single Domain Dynamic Generalization (SDDG) framework, which simultaneously exploits domain-invariant and domain-specific features on a per-sample basis and learns to generalize to various unseen domains with numerous natural images. Specifically, a dynamic block is designed to adaptively adjust the network with a dynamic adaptor. And an information maximization loss is further combined to increase diversity. The whole network is integrated into the meta-learning paradigm. We generate amplitude perturbed images and cover diverse domains with natural images. Therefore, the network can learn to generalize to the perturbed domains in the meta-test phase. Extensive experiments show the proposed method is effective and outperforms the state-of-the-art on LivDet-Iris 2017 dataset.
Few-shot One-class Domain Adaptation Based on Frequency for Iris Presentation Attack Detection
Apr 01, 2022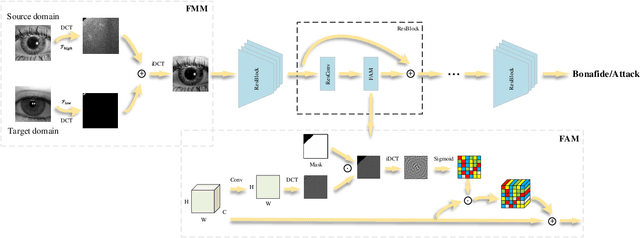
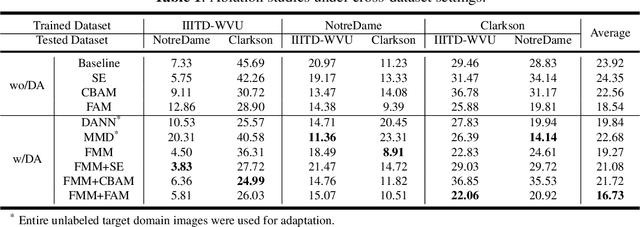
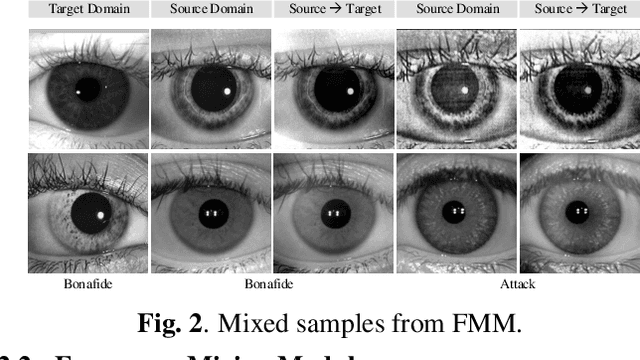
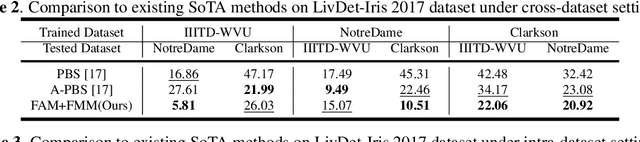
Iris presentation attack detection (PAD) has achieved remarkable success to ensure the reliability and security of iris recognition systems. Most existing methods exploit discriminative features in the spatial domain and report outstanding performance under intra-dataset settings. However, the degradation of performance is inevitable under cross-dataset settings, suffering from domain shift. In consideration of real-world applications, a small number of bonafide samples are easily accessible. We thus define a new domain adaptation setting called Few-shot One-class Domain Adaptation (FODA), where adaptation only relies on a limited number of target bonafide samples. To address this problem, we propose a novel FODA framework based on the expressive power of frequency information. Specifically, our method integrates frequency-related information through two proposed modules. Frequency-based Attention Module (FAM) aggregates frequency information into spatial attention and explicitly emphasizes high-frequency fine-grained features. Frequency Mixing Module (FMM) mixes certain frequency components to generate large-scale target-style samples for adaptation with limited target bonafide samples. Extensive experiments on LivDet-Iris 2017 dataset demonstrate the proposed method achieves state-of-the-art or competitive performance under both cross-dataset and intra-dataset settings.
The Medical Scribe: Corpus Development and Model Performance Analyses
Mar 12, 2020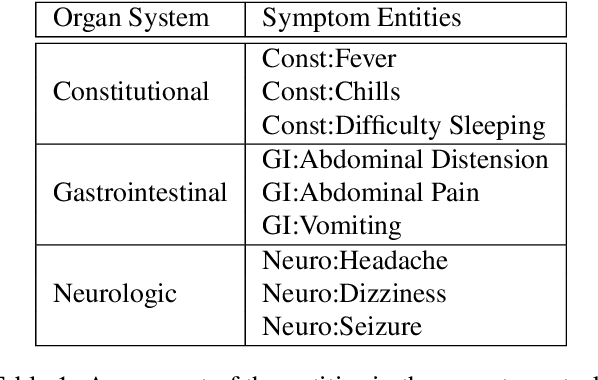

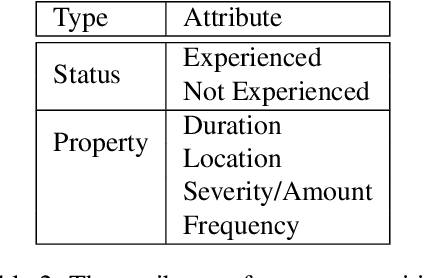
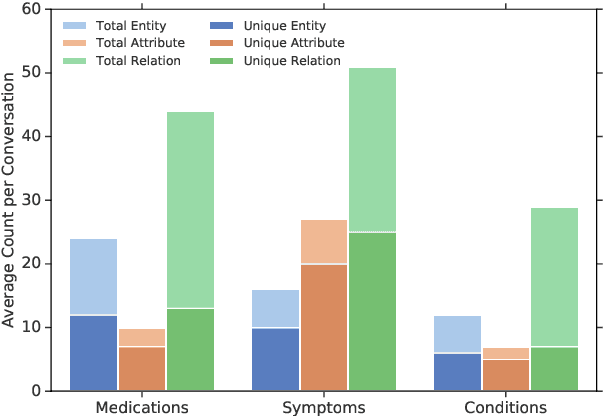
There is a growing interest in creating tools to assist in clinical note generation using the audio of provider-patient encounters. Motivated by this goal and with the help of providers and medical scribes, we developed an annotation scheme to extract relevant clinical concepts. We used this annotation scheme to label a corpus of about 6k clinical encounters. This was used to train a state-of-the-art tagging model. We report ontologies, labeling results, model performances, and detailed analyses of the results. Our results show that the entities related to medications can be extracted with a relatively high accuracy of 0.90 F-score, followed by symptoms at 0.72 F-score, and conditions at 0.57 F-score. In our task, we not only identify where the symptoms are mentioned but also map them to canonical forms as they appear in the clinical notes. Of the different types of errors, in about 19-38% of the cases, we find that the model output was correct, and about 17-32% of the errors do not impact the clinical note. Taken together, the models developed in this work are more useful than the F-scores reflect, making it a promising approach for practical applications.
* Extended version of the paper accepted at LREC 2020
Extracting Symptoms and their Status from Clinical Conversations
Jun 05, 2019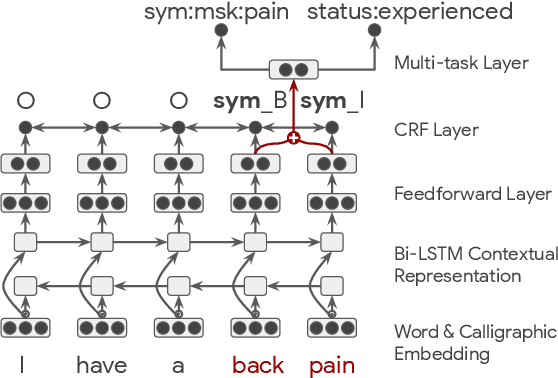
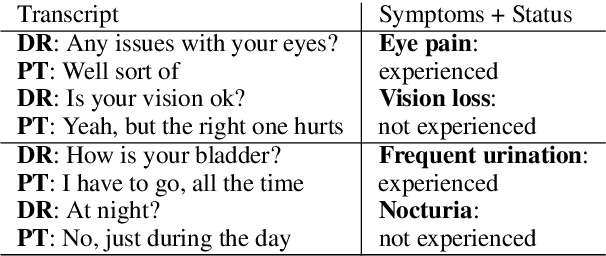
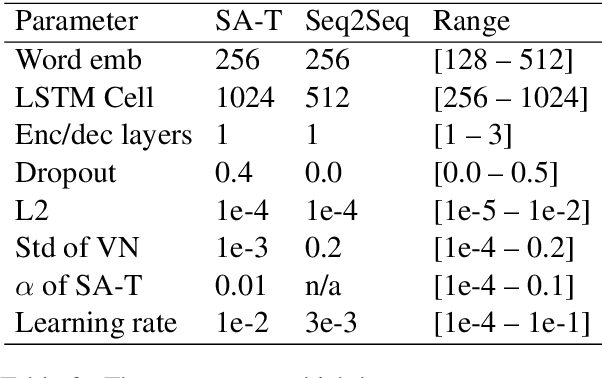
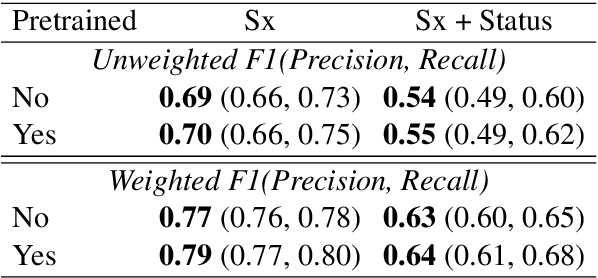
This paper describes novel models tailored for a new application, that of extracting the symptoms mentioned in clinical conversations along with their status. Lack of any publicly available corpus in this privacy-sensitive domain led us to develop our own corpus, consisting of about 3K conversations annotated by professional medical scribes. We propose two novel deep learning approaches to infer the symptom names and their status: (1) a new hierarchical span-attribute tagging (\SAT) model, trained using curriculum learning, and (2) a variant of sequence-to-sequence model which decodes the symptoms and their status from a few speaker turns within a sliding window over the conversation. This task stems from a realistic application of assisting medical providers in capturing symptoms mentioned by patients from their clinical conversations. To reflect this application, we define multiple metrics. From inter-rater agreement, we find that the task is inherently difficult. We conduct comprehensive evaluations on several contrasting conditions and observe that the performance of the models range from an F-score of 0.5 to 0.8 depending on the condition. Our analysis not only reveals the inherent challenges of the task, but also provides useful directions to improve the models.