 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLPO: Towards Accurate GUI Agent Interaction via Location Preference Optimization
Jun 11, 2025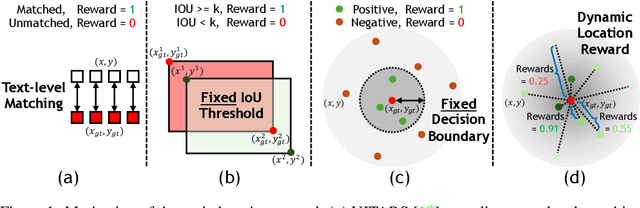
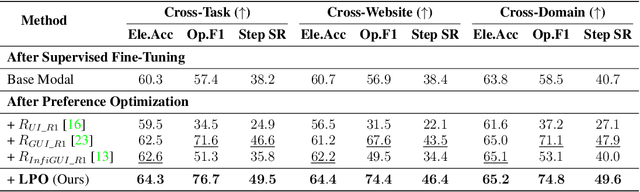
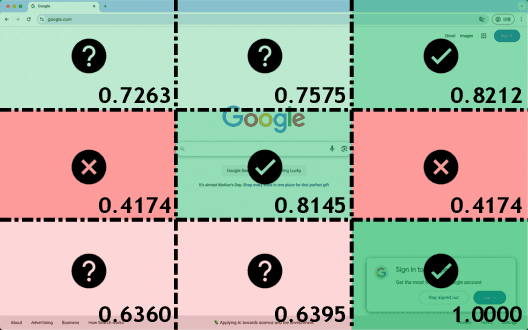
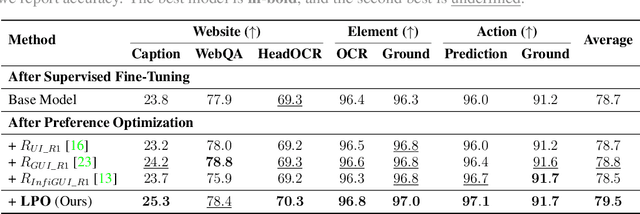
The advent of autonomous agents is transforming interactions with Graphical User Interfaces (GUIs) by employing natural language as a powerful intermediary. Despite the predominance of Supervised Fine-Tuning (SFT) methods in current GUI agents for achieving spatial localization, these methods face substantial challenges due to their limited capacity to accurately perceive positional data. Existing strategies, such as reinforcement learning, often fail to assess positional accuracy effectively, thereby restricting their utility. In response, we introduce Location Preference Optimization (LPO), a novel approach that leverages locational data to optimize interaction preferences. LPO uses information entropy to predict interaction positions by focusing on zones rich in information. Besides, it further introduces a dynamic location reward function based on physical distance, reflecting the varying importance of interaction positions. Supported by Group Relative Preference Optimization (GRPO), LPO facilitates an extensive exploration of GUI environments and significantly enhances interaction precision. Comprehensive experiments demonstrate LPO's superior performance, achieving SOTA results across both offline benchmarks and real-world online evaluations. Our code will be made publicly available soon, at https://github.com/AIDC-AI/LPO.
Advancing Tool-Augmented Large Language Models: Integrating Insights from Errors in Inference Trees
Jun 11, 2024Tool-augmented large language models (LLMs) leverage tools, often in the form of APIs, to enhance their reasoning capabilities on complex tasks, thus taking on the role of intelligent agents interacting with the real world. The recently introduced ToolLLaMA model by Qin et al. [2024] utilizes the depth-first search-based decision tree (DFSDT) method for reasoning with $16000+$ real-world APIs, which effectively improves the planning and inferencing performance of tool-augmented LLMs compared to traditional chain reasoning approaches. However, their approach only employs successful paths from decision trees (also called inference trees) for supervised fine-tuning (SFT) during training, which does not fully exploit the advantages of the tree of thought. In this study, we propose an inference trajectory optimization framework based on the preference data extracted from decision trees to address this limitation. We first introduce a novel method for constructing preference data from the tree of thought, capitalizing on the failed explorations previously overlooked in the trees. Specifically, we generate an effective step-wise preference dataset, named ToolPreference, for tool use based on the ToolBench dataset. In the subsequent training phase, we first fine-tune the LLM with tool-usage expert trajectories and then use these step-wise preference pairs for direct preference optimization (DPO) to update the policy of the LLM, resulting in our ToolPrefer-LLaMA (TP-LLaMA) model. Our experiments demonstrate that by obtaining insights from errors in inference trees, TP-LLaMA significantly outperforms the baselines across almost all test scenarios by a large margin and exhibits better generalization capabilities with unseen APIs. At the same time, TP-LLaMA has also demonstrated superior reasoning efficiency compared to the baselines, making it more suitable for complex tool-usage reasoning tasks.
TAI++: Text as Image for Multi-Label Image Classification by Co-Learning Transferable Prompt
May 11, 2024The recent introduction of prompt tuning based on pre-trained vision-language models has dramatically improved the performance of multi-label image classification. However, some existing strategies that have been explored still have drawbacks, i.e., either exploiting massive labeled visual data at a high cost or using text data only for text prompt tuning and thus failing to learn the diversity of visual knowledge. Hence, the application scenarios of these methods are limited. In this paper, we propose a pseudo-visual prompt~(PVP) module for implicit visual prompt tuning to address this problem. Specifically, we first learn the pseudo-visual prompt for each category, mining diverse visual knowledge by the well-aligned space of pre-trained vision-language models. Then, a co-learning strategy with a dual-adapter module is designed to transfer visual knowledge from pseudo-visual prompt to text prompt, enhancing their visual representation abilities. Experimental results on VOC2007, MS-COCO, and NUSWIDE datasets demonstrate that our method can surpass state-of-the-art~(SOTA) methods across various settings for multi-label image classification tasks. The code is available at https://github.com/njustkmg/PVP.