 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMolSight: A Graph-Aware Vision-Language Model for Unified Chemical Image Understanding
Jul 02, 2026Using molecular large language models (LLMs) as a unified framework for understanding molecular structures and functions is emerging as a new trend in tasks such as molecular design and drug discovery. However, these models struggle to fully capture the visual representation of molecular structures, limiting their potential. While existing molecular vision-language models (VLMs) show promise, they still face challenges in structural alignment and lack the necessary topological modeling for accurate molecular understanding. To address this, we propose MolSight, a graph-aware vision-language model framework designed to enhance the understanding of molecular images by VLMs. MolSight integrates a Molecular Topology Module to inject chemical-bond adjacency information into vision tokens, and a Molecular Grounding Module to align visual features with chemical symbolic semantics. Our experiments demonstrate that MolSight significantly outperforms existing VLMs, molecular LLMs, and specialized tools across multiple chemical visual understanding tasks, achieving a new level of molecular image reasoning.
Building Autonomous GUI Navigation via Agentic-Q Estimation and Step-Wise Policy Optimization
Feb 14, 2026Recent advances in Multimodal Large Language Models (MLLMs) have substantially driven the progress of autonomous agents for Graphical User Interface (GUI). Nevertheless, in real-world applications, GUI agents are often faced with non-stationary environments, leading to high computational costs for data curation and policy optimization. In this report, we introduce a novel MLLM-centered framework for GUI agents, which consists of two components: agentic-Q estimation and step-wise policy optimization. The former one aims to optimize a Q-model that can generate step-wise values to evaluate the contribution of a given action to task completion. The latter one takes step-wise samples from the state-action trajectory as inputs, and optimizes the policy via reinforcement learning with our agentic-Q model. It should be noticed that (i) all state-action trajectories are produced by the policy itself, so that the data collection costs are manageable; (ii) the policy update is decoupled from the environment, ensuring stable and efficient optimization. Empirical evaluations show that our framework endows Ovis2.5-9B with powerful GUI interaction capabilities, achieving remarkable performances on GUI navigation and grounding benchmarks and even surpassing contenders with larger scales.
LPO: Towards Accurate GUI Agent Interaction via Location Preference Optimization
Jun 11, 2025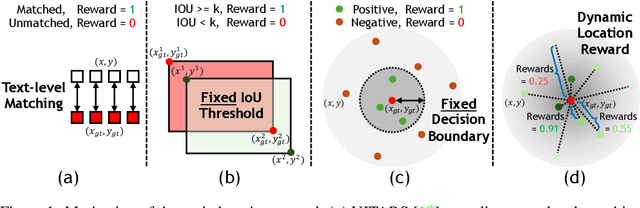
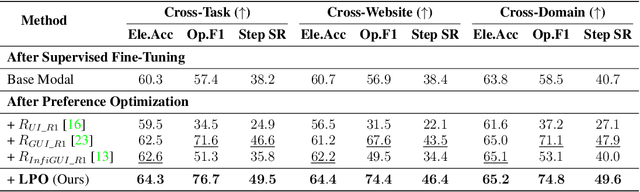
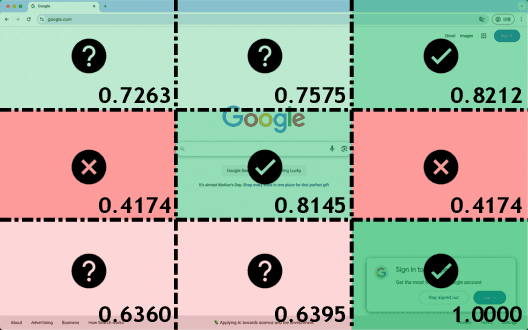
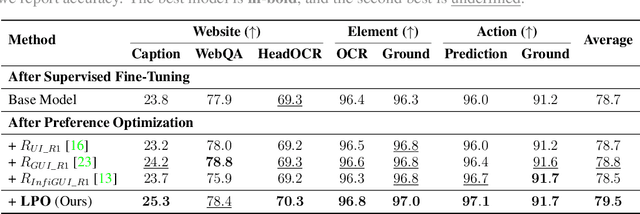
The advent of autonomous agents is transforming interactions with Graphical User Interfaces (GUIs) by employing natural language as a powerful intermediary. Despite the predominance of Supervised Fine-Tuning (SFT) methods in current GUI agents for achieving spatial localization, these methods face substantial challenges due to their limited capacity to accurately perceive positional data. Existing strategies, such as reinforcement learning, often fail to assess positional accuracy effectively, thereby restricting their utility. In response, we introduce Location Preference Optimization (LPO), a novel approach that leverages locational data to optimize interaction preferences. LPO uses information entropy to predict interaction positions by focusing on zones rich in information. Besides, it further introduces a dynamic location reward function based on physical distance, reflecting the varying importance of interaction positions. Supported by Group Relative Preference Optimization (GRPO), LPO facilitates an extensive exploration of GUI environments and significantly enhances interaction precision. Comprehensive experiments demonstrate LPO's superior performance, achieving SOTA results across both offline benchmarks and real-world online evaluations. Our code will be made publicly available soon, at https://github.com/AIDC-AI/LPO.
Unifying KV Cache Compression for Large Language Models with LeanKV
Dec 04, 2024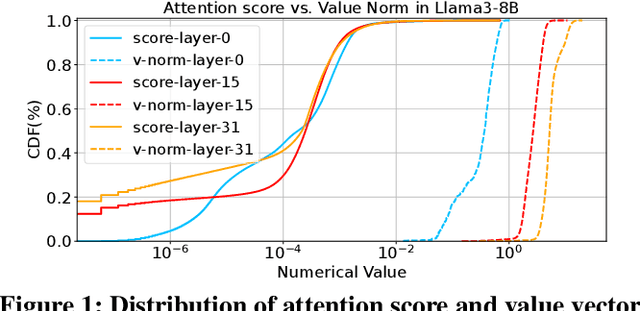
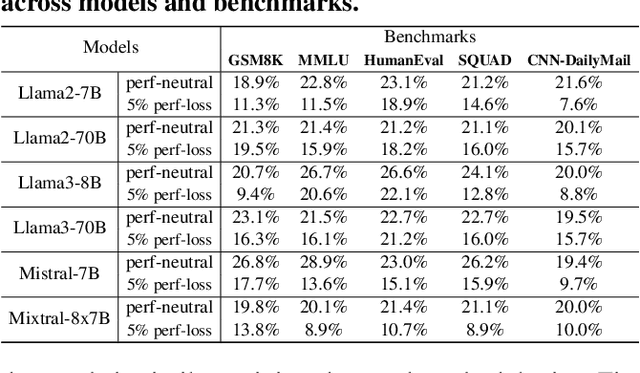
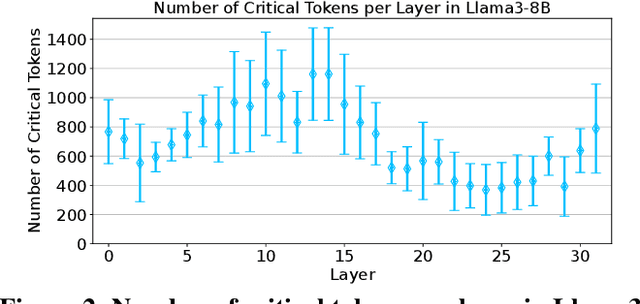
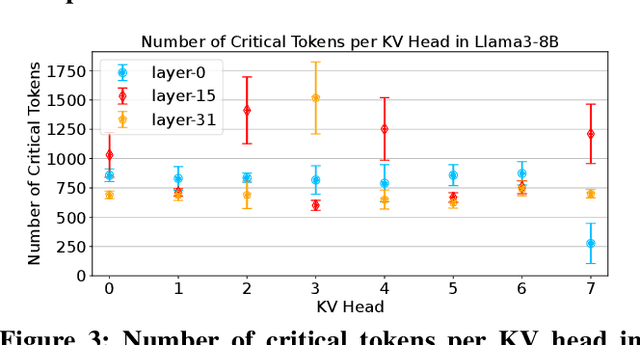
Large language models (LLMs) demonstrate exceptional performance but incur high serving costs due to substantial memory demands, with the key-value (KV) cache being a primary bottleneck. Existing KV cache compression methods, including quantization and pruning, struggle with limitations such as uniform treatment of keys and values and static memory allocation across attention heads. To address these challenges, we introduce LeanKV, a unified KV cache compression framework that enhances LLM serving efficiency without compromising accuracy through three innovations: (1) Hetero-KV quantization, which stores keys at a higher precision than values to reflect their greater impact on attention computations; (2) per-head dynamic sparsity, which allocates memory based on token importance per head and per request; and (3) unified KV compression, integrating mixed-precision quantization and selective pruning to enable a smooth tradeoff between model accuracy and memory efficiency. To efficiently support these techniques, LeanKV introduces systems optimizations including unified paging and on-GPU parallel memory management. Implemented on vLLM, LeanKV compresses the KV cache by $3.0\times$ to $5.0\times$ without accuracy loss and up to $11.0\times$ with under 5% accuracy loss, enhancing throughput by $1.9\times$ to $2.5\times$, and up to $6.9\times$.
Scalable and Accurate Graph Reasoning with LLM-based Multi-Agents
Oct 07, 2024



Recent research has explored the use of Large Language Models (LLMs) for tackling complex graph reasoning tasks. However, due to the intricacies of graph structures and the inherent limitations of LLMs in handling long text, current approaches often fail to deliver satisfactory accuracy, even on small-scale graphs and simple tasks. To address these challenges, we introduce GraphAgent-Reasoner, a fine-tuning-free framework that utilizes a multi-agent collaboration strategy for explicit and precise graph reasoning. Inspired by distributed graph computation theory, our framework decomposes graph problems into smaller, node-centric tasks that are distributed among multiple agents. The agents collaborate to solve the overall problem, significantly reducing the amount of information and complexity handled by a single LLM, thus enhancing the accuracy of graph reasoning. By simply increasing the number of agents, GraphAgent-Reasoner can efficiently scale to accommodate larger graphs with over 1,000 nodes. Evaluated on the GraphInstruct dataset, our framework demonstrates near-perfect accuracy on polynomial-time graph reasoning tasks, significantly outperforming the best available models, both closed-source and fine-tuned open-source variants. Our framework also demonstrates the capability to handle real-world graph reasoning applications such as webpage importance analysis.
RAG-Optimized Tibetan Tourism LLMs: Enhancing Accuracy and Personalization
Aug 21, 2024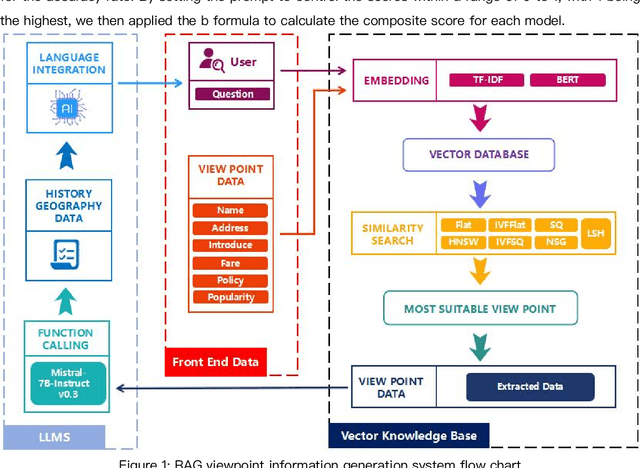
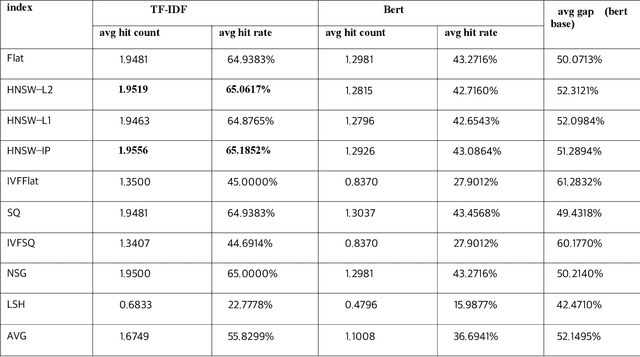
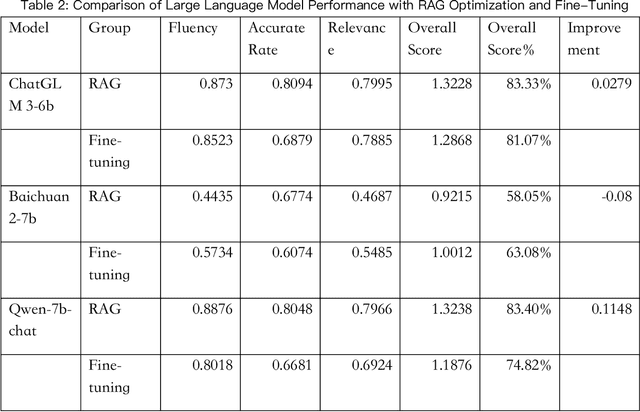
With the development of the modern social economy, tourism has become an important way to meet people's spiritual needs, bringing development opportunities to the tourism industry. However, existing large language models (LLMs) face challenges in personalized recommendation capabilities and the generation of content that can sometimes produce hallucinations. This study proposes an optimization scheme for Tibet tourism LLMs based on retrieval-augmented generation (RAG) technology. By constructing a database of tourist viewpoints and processing the data using vectorization techniques, we have significantly improved retrieval accuracy. The application of RAG technology effectively addresses the hallucination problem in content generation. The optimized model shows significant improvements in fluency, accuracy, and relevance of content generation. This research demonstrates the potential of RAG technology in the standardization of cultural tourism information and data analysis, providing theoretical and technical support for the development of intelligent cultural tourism service systems.
Retrieval-Augmented Mixture of LoRA Experts for Uploadable Machine Learning
Jun 24, 2024



Low-Rank Adaptation (LoRA) offers an efficient way to fine-tune large language models (LLMs). Its modular and plug-and-play nature allows the integration of various domain-specific LoRAs, enhancing LLM capabilities. Open-source platforms like Huggingface and Modelscope have introduced a new computational paradigm, Uploadable Machine Learning (UML). In UML, contributors use decentralized data to train specialized adapters, which are then uploaded to a central platform to improve LLMs. This platform uses these domain-specific adapters to handle mixed-task requests requiring personalized service. Previous research on LoRA composition either focuses on specific tasks or fixes the LoRA selection during training. However, in UML, the pool of LoRAs is dynamically updated with new uploads, requiring a generalizable selection mechanism for unseen LoRAs. Additionally, the mixed-task nature of downstream requests necessitates personalized services. To address these challenges, we propose Retrieval-Augmented Mixture of LoRA Experts (RAMoLE), a framework that adaptively retrieves and composes multiple LoRAs based on input prompts. RAMoLE has three main components: LoraRetriever for identifying and retrieving relevant LoRAs, an on-the-fly MoLE mechanism for coordinating the retrieved LoRAs, and efficient batch inference for handling heterogeneous requests. Experimental results show that RAMoLE consistently outperforms baselines, highlighting its effectiveness and scalability.
Intruding with Words: Towards Understanding Graph Injection Attacks at the Text Level
May 26, 2024Graph Neural Networks (GNNs) excel across various applications but remain vulnerable to adversarial attacks, particularly Graph Injection Attacks (GIAs), which inject malicious nodes into the original graph and pose realistic threats. Text-attributed graphs (TAGs), where nodes are associated with textual features, are crucial due to their prevalence in real-world applications and are commonly used to evaluate these vulnerabilities. However, existing research only focuses on embedding-level GIAs, which inject node embeddings rather than actual textual content, limiting their applicability and simplifying detection. In this paper, we pioneer the exploration of GIAs at the text level, presenting three novel attack designs that inject textual content into the graph. Through theoretical and empirical analysis, we demonstrate that text interpretability, a factor previously overlooked at the embedding level, plays a crucial role in attack strength. Among the designs we investigate, the Word-frequency-based Text-level GIA (WTGIA) is particularly notable for its balance between performance and interpretability. Despite the success of WTGIA, we discover that defenders can easily enhance their defenses with customized text embedding methods or large language model (LLM)--based predictors. These insights underscore the necessity for further research into the potential and practical significance of text-level GIAs.
An Asynchronous Updating Reinforcement Learning Framework for Task-oriented Dialog System
May 04, 2023


Reinforcement learning has been applied to train the dialog systems in many works. Previous approaches divide the dialog system into multiple modules including DST (dialog state tracking) and DP (dialog policy), and train these modules simultaneously. However, different modules influence each other during training. The errors from DST might misguide the dialog policy, and the system action brings extra difficulties for the DST module. To alleviate this problem, we propose Asynchronous Updating Reinforcement Learning framework (AURL) that updates the DST module and the DP module asynchronously under a cooperative setting. Furthermore, curriculum learning is implemented to address the problem of unbalanced data distribution during reinforcement learning sampling, and multiple user models are introduced to increase the dialog diversity. Results on the public SSD-PHONE dataset show that our method achieves a compelling result with a 31.37% improvement on the dialog success rate. The code is publicly available via https://github.com/shunjiu/AURL.
Benchmarking GNN-Based Recommender Systems on Intel Optane Persistent Memory
Jul 25, 2022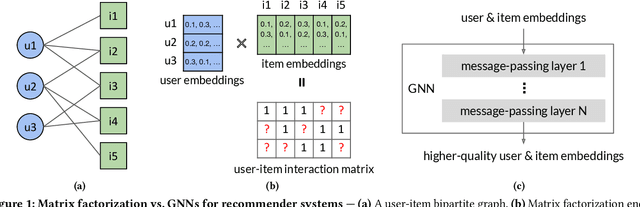
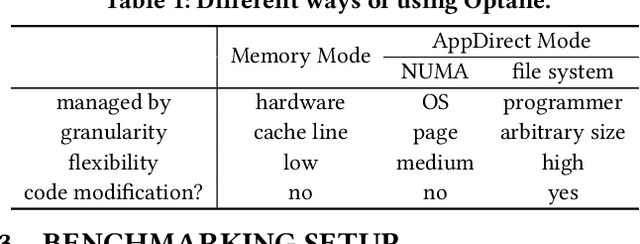
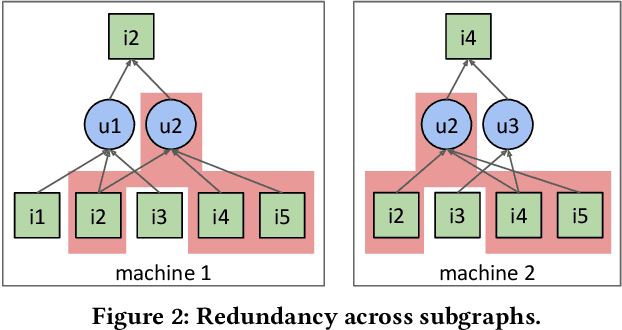
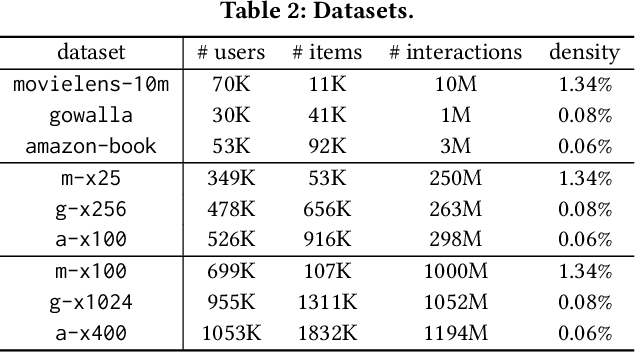
Graph neural networks (GNNs), which have emerged as an effective method for handling machine learning tasks on graphs, bring a new approach to building recommender systems, where the task of recommendation can be formulated as the link prediction problem on user-item bipartite graphs. Training GNN-based recommender systems (GNNRecSys) on large graphs incurs a large memory footprint, easily exceeding the DRAM capacity on a typical server. Existing solutions resort to distributed subgraph training, which is inefficient due to the high cost of dynamically constructing subgraphs and significant redundancy across subgraphs. The emerging Intel Optane persistent memory allows a single machine to have up to 6 TB of memory at an affordable cost, thus making single-machine GNNRecSys training feasible, which eliminates the inefficiencies in distributed training. One major concern of using Optane for GNNRecSys is Optane's relatively low bandwidth compared with DRAMs. This limitation can be particularly detrimental to achieving high performance for GNNRecSys workloads since their dominant compute kernels are sparse and memory access intensive. To understand whether Optane is a good fit for GNNRecSys training, we perform an in-depth characterization of GNNRecSys workloads and a comprehensive benchmarking study. Our benchmarking results show that when properly configured, Optane-based single-machine GNNRecSys training outperforms distributed training by a large margin, especially when handling deep GNN models. We analyze where the speedup comes from, provide guidance on how to configure Optane for GNNRecSys workloads, and discuss opportunities for further optimizations.