 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDense Pruning of Pointwise Convolutions in the Frequency Domain
Sep 16, 2021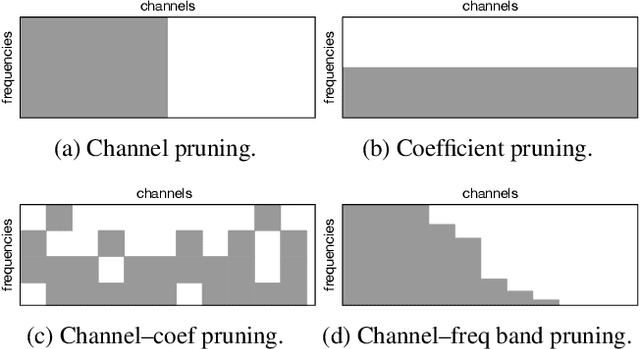

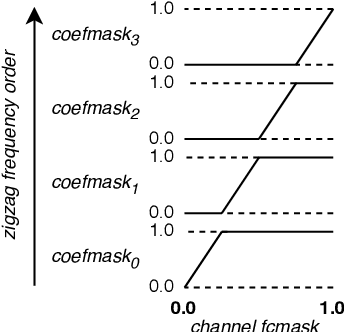

Depthwise separable convolutions and frequency-domain convolutions are two recent ideas for building efficient convolutional neural networks. They are seemingly incompatible: the vast majority of operations in depthwise separable CNNs are in pointwise convolutional layers, but pointwise layers use 1x1 kernels, which do not benefit from frequency transformation. This paper unifies these two ideas by transforming the activations, not the kernels. Our key insights are that 1) pointwise convolutions commute with frequency transformation and thus can be computed in the frequency domain without modification, 2) each channel within a given layer has a different level of sensitivity to frequency domain pruning, and 3) each channel's sensitivity to frequency pruning is approximately monotonic with respect to frequency. We leverage this knowledge by proposing a new technique which wraps each pointwise layer in a discrete cosine transform (DCT) which is truncated to selectively prune coefficients above a given threshold as per the needs of each channel. To learn which frequencies should be pruned from which channels, we introduce a novel learned parameter which specifies each channel's pruning threshold. We add a new regularization term which incentivizes the model to decrease the number of retained frequencies while still maintaining task accuracy. Unlike weight pruning techniques which rely on sparse operators, our contiguous frequency band pruning results in fully dense computation. We apply our technique to MobileNetV2 and in the process reduce computation time by 22% and incur <1% accuracy degradation.
EVA$^2$: Exploiting Temporal Redundancy in Live Computer Vision
Apr 17, 2018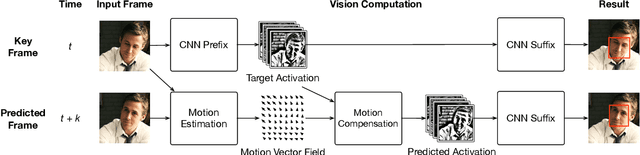

Hardware support for deep convolutional neural networks (CNNs) is critical to advanced computer vision in mobile and embedded devices. Current designs, however, accelerate generic CNNs; they do not exploit the unique characteristics of real-time vision. We propose to use the temporal redundancy in natural video to avoid unnecessary computation on most frames. A new algorithm, activation motion compensation, detects changes in the visual input and incrementally updates a previously-computed output. The technique takes inspiration from video compression and applies well-known motion estimation techniques to adapt to visual changes. We use an adaptive key frame rate to control the trade-off between efficiency and vision quality as the input changes. We implement the technique in hardware as an extension to existing state-of-the-art CNN accelerator designs. The new unit reduces the average energy per frame by 54.2%, 61.7%, and 87.6% for three CNNs with less than 1% loss in vision accuracy.
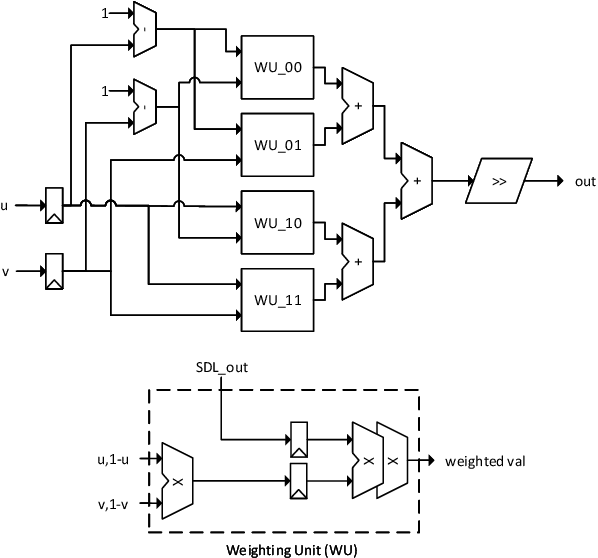
Reconfiguring the Imaging Pipeline for Computer Vision
Aug 01, 2017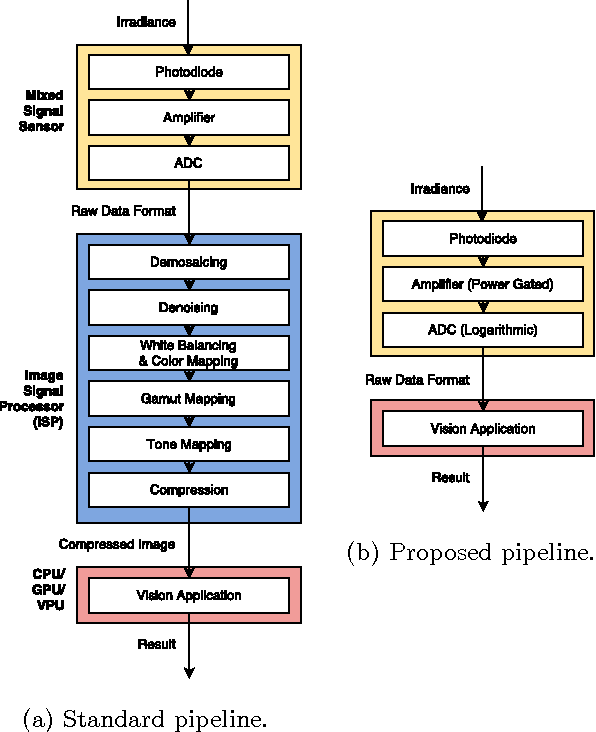
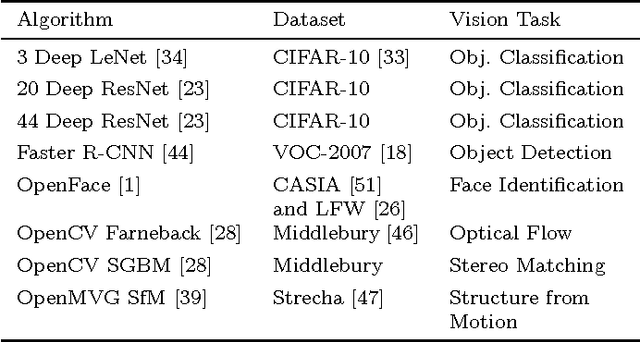
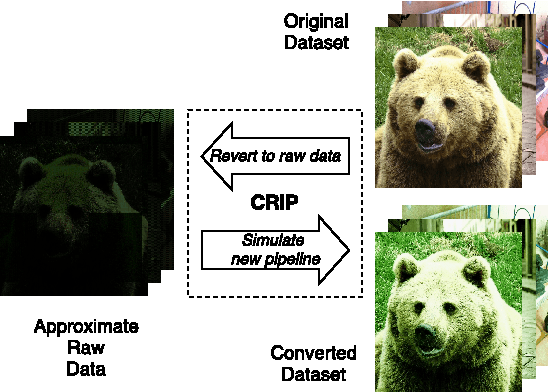

Advancements in deep learning have ignited an explosion of research on efficient hardware for embedded computer vision. Hardware vision acceleration, however, does not address the cost of capturing and processing the image data that feeds these algorithms. We examine the role of the image signal processing (ISP) pipeline in computer vision to identify opportunities to reduce computation and save energy. The key insight is that imaging pipelines should be designed to be configurable: to switch between a traditional photography mode and a low-power vision mode that produces lower-quality image data suitable only for computer vision. We use eight computer vision algorithms and a reversible pipeline simulation tool to study the imaging system's impact on vision performance. For both CNN-based and classical vision algorithms, we observe that only two ISP stages, demosaicing and gamma compression, are critical for task performance. We propose a new image sensor design that can compensate for skipping these stages. The sensor design features an adjustable resolution and tunable analog-to-digital converters (ADCs). Our proposed imaging system's vision mode disables the ISP entirely and configures the sensor to produce subsampled, lower-precision image data. This vision mode can save ~75% of the average energy of a baseline photography mode while having only a small impact on vision task accuracy.