 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGauS: Differentiable Scheduling Optimization via Gaussian Reparameterization
Feb 23, 2026Efficient operator scheduling is a fundamental challenge in software compilation and hardware synthesis. While recent differentiable approaches have sought to replace traditional ones like exact solvers or heuristics with gradient-based search, they typically rely on categorical distributions that fail to capture the ordinal nature of time and suffer from a parameter space that scales poorly. In this paper, we propose a novel differentiable framework, GauS, that models operator scheduling as a stochastic relaxation using Gaussian distributions, which fully utilize modern parallel computing devices like GPUs. By representing schedules as continuous Gaussian variables, we successfully capture the ordinal nature of time and reduce the optimization space by orders of magnitude. Our method is highly flexible to represent various objectives and constraints, which provides the first differentiable formulation for the complex pipelined scheduling problem. We evaluate our method on a range of benchmarks, demonstrating that Gaus achieves Pareto-optimal results.
From Pragmas to Partners: A Symbiotic Evolution of Agentic High-Level Synthesis
Feb 03, 2026The rise of large language models has sparked interest in AI-driven hardware design, raising the question: does high-level synthesis (HLS) still matter in the agentic era? We argue that HLS remains essential. While we expect mature agentic hardware systems to leverage both HLS and RTL, this paper focuses on HLS and its role in enabling agentic optimization. HLS offers faster iteration cycles, portability, and design permutability that make it a natural layer for agentic optimization. This position paper makes three contributions. First, we explain why HLS serves as a practical abstraction layer and a golden reference for agentic hardware design. Second, we identify key limitations of current HLS tools, namely inadequate performance feedback, rigid interfaces, and limited debuggability that agents are uniquely positioned to address. Third, we propose a taxonomy for the symbiotic evolution of agentic HLS, clarifying how responsibility shifts from human designers to AI agents as systems advance from copilots to autonomous design partners.
Magellan: Autonomous Discovery of Novel Compiler Optimization Heuristics with AlphaEvolve
Jan 28, 2026Modern compilers rely on hand-crafted heuristics to guide optimization passes. These human-designed rules often struggle to adapt to the complexity of modern software and hardware and lead to high maintenance burden. To address this challenge, we present Magellan, an agentic framework that evolves the compiler pass itself by synthesizing executable C++ decision logic. Magellan couples an LLM coding agent with evolutionary search and autotuning in a closed loop of generation, evaluation on user-provided macro-benchmarks, and refinement, producing compact heuristics that integrate directly into existing compilers. Across several production optimization tasks, Magellan discovers policies that match or surpass expert baselines. In LLVM function inlining, Magellan synthesizes new heuristics that outperform decades of manual engineering for both binary-size reduction and end-to-end performance. In register allocation, it learns a concise priority rule for live-range processing that matches intricate human-designed policies on a large-scale workload. We also report preliminary results on XLA problems, demonstrating portability beyond LLVM with reduced engineering effort.
HeuriGym: An Agentic Benchmark for LLM-Crafted Heuristics in Combinatorial Optimization
Jun 09, 2025While Large Language Models (LLMs) have demonstrated significant advancements in reasoning and agent-based problem-solving, current evaluation methodologies fail to adequately assess their capabilities: existing benchmarks either rely on closed-ended questions prone to saturation and memorization, or subjective comparisons that lack consistency and rigor. In this work, we introduce HeuriGym, an agentic framework designed for evaluating heuristic algorithms generated by LLMs for combinatorial optimization problems, characterized by clearly defined objectives and expansive solution spaces. HeuriGym empowers LLMs to propose heuristics, receive evaluative feedback via code execution, and iteratively refine their solutions. We evaluate nine state-of-the-art models on nine problems across domains such as computer systems, logistics, and biology, exposing persistent limitations in tool use, planning, and adaptive reasoning. To quantify performance, we propose the Quality-Yield Index (QYI), a metric that captures both solution pass rate and quality. Even top models like GPT-o4-mini-high and Gemini-2.5-Pro attain QYI scores of only 0.6, well below the expert baseline of 1. Our open-source benchmark aims to guide the development of LLMs toward more effective and realistic problem-solving in scientific and engineering domains.
Accelerating Diffusion Language Model Inference via Efficient KV Caching and Guided Diffusion
May 27, 2025



Diffusion language models offer parallel token generation and inherent bidirectionality, promising more efficient and powerful sequence modeling compared to autoregressive approaches. However, state-of-the-art diffusion models (e.g., Dream 7B, LLaDA 8B) suffer from slow inference. While they match the quality of similarly sized Autoregressive (AR) Models (e.g., Qwen2.5 7B, Llama3 8B), their iterative denoising requires multiple full-sequence forward passes, resulting in high computational costs and latency, particularly for long input prompts and long-context scenarios. Furthermore, parallel token generation introduces token incoherence problems, and current sampling heuristics suffer from significant quality drops with decreasing denoising steps. We address these limitations with two training-free techniques. First, we propose FreeCache, a Key-Value (KV) approximation caching technique that reuses stable KV projections across denoising steps, effectively reducing the computational cost of DLM inference. Second, we introduce Guided Diffusion, a training-free method that uses a lightweight pretrained autoregressive model to supervise token unmasking, dramatically reducing the total number of denoising iterations without sacrificing quality. We conduct extensive evaluations on open-source reasoning benchmarks, and our combined methods deliver up to a 34x end-to-end speedup without compromising accuracy. For the first time, diffusion language models achieve a comparable and even faster latency as the widely adopted autoregressive models. Our work successfully paved the way for scaling up the diffusion language model to a broader scope of applications across different domains.
Semantic Compression of 3D Objects for Open and Collaborative Virtual Worlds
May 22, 2025

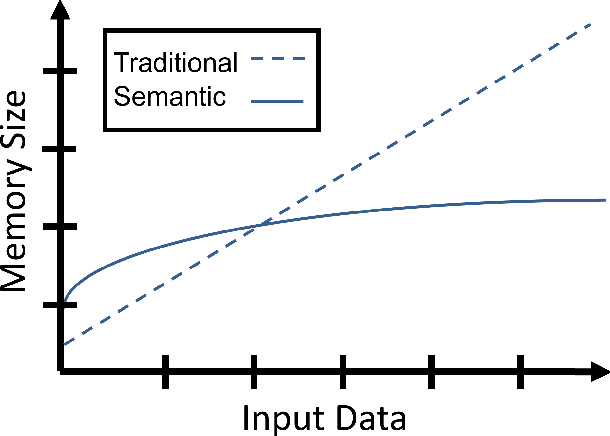

Traditional methods for 3D object compression operate only on structural information within the object vertices, polygons, and textures. These methods are effective at compression rates up to 10x for standard object sizes but quickly deteriorate at higher compression rates with texture artifacts, low-polygon counts, and mesh gaps. In contrast, semantic compression ignores structural information and operates directly on the core concepts to push to extreme levels of compression. In addition, it uses natural language as its storage format, which makes it natively human-readable and a natural fit for emerging applications built around large-scale, collaborative projects within augmented and virtual reality. It deprioritizes structural information like location, size, and orientation and predicts the missing information with state-of-the-art deep generative models. In this work, we construct a pipeline for 3D semantic compression from public generative models and explore the quality-compression frontier for 3D object compression. We apply this pipeline to achieve rates as high as 105x for 3D objects taken from the Objaverse dataset and show that semantic compression can outperform traditional methods in the important quality-preserving region around 100x compression.
Graph Learning at Scale: Characterizing and Optimizing Pre-Propagation GNNs
Apr 17, 2025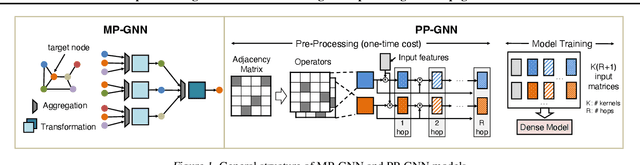

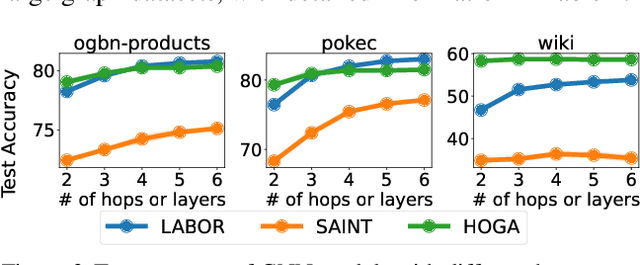

Graph neural networks (GNNs) are widely used for learning node embeddings in graphs, typically adopting a message-passing scheme. This approach, however, leads to the neighbor explosion problem, with exponentially growing computational and memory demands as layers increase. Graph sampling has become the predominant method for scaling GNNs to large graphs, mitigating but not fully solving the issue. Pre-propagation GNNs (PP-GNNs) represent a new class of models that decouple feature propagation from training through pre-processing, addressing neighbor explosion in theory. Yet, their practical advantages and system-level optimizations remain underexplored. This paper provides a comprehensive characterization of PP-GNNs, comparing them with graph-sampling-based methods in training efficiency, scalability, and accuracy. While PP-GNNs achieve comparable accuracy, we identify data loading as the key bottleneck for training efficiency and input expansion as a major scalability challenge. To address these issues, we propose optimized data loading schemes and tailored training methods that improve PP-GNN training throughput by an average of 15$\times$ over the PP-GNN baselines, with speedup of up to 2 orders of magnitude compared to sampling-based GNNs on large graph benchmarks. Our implementation is publicly available at https://github.com/cornell-zhang/preprop-gnn.
ShadowLLM: Predictor-based Contextual Sparsity for Large Language Models
Jun 24, 2024



The high power consumption and latency-sensitive deployments of large language models (LLMs) have motivated techniques like quantization and sparsity. Contextual sparsity, where the sparsity pattern is input-dependent, is crucial in LLMs because the permanent removal of attention heads or neurons from LLMs can significantly degrade accuracy. Prior work has attempted to model contextual sparsity using neural networks trained to predict activation magnitudes, which can be used to dynamically prune structures with low predicted activation magnitude. In this paper, we look beyond magnitude-based pruning criteria to assess attention head and neuron importance in LLMs. We developed a novel predictor called ShadowLLM, which can shadow the LLM behavior and enforce better sparsity patterns, resulting in over 15% improvement in end-to-end accuracy without increasing latency compared to previous methods. ShadowLLM achieves up to a 20\% speed-up over the state-of-the-art DejaVu framework. These enhancements are validated on models with up to 30 billion parameters. Our code is available at \href{https://github.com/abdelfattah-lab/shadow_llm/}{ShadowLLM}.
Differentiable Combinatorial Scheduling at Scale
Jun 06, 2024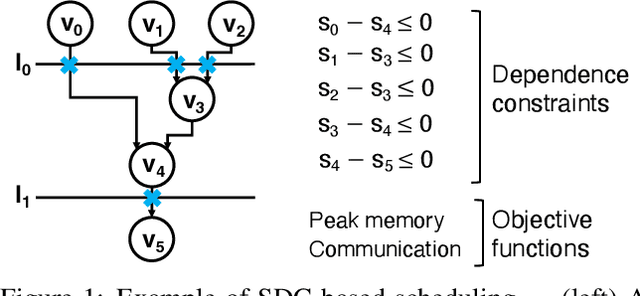
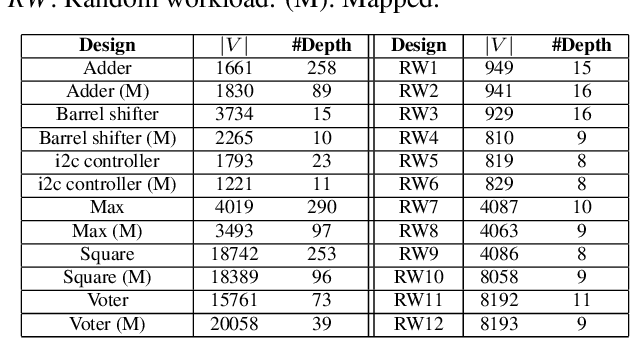
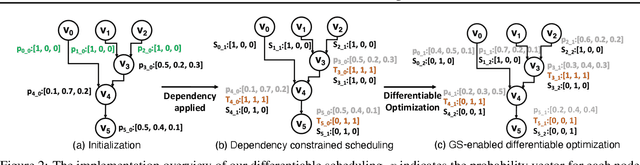
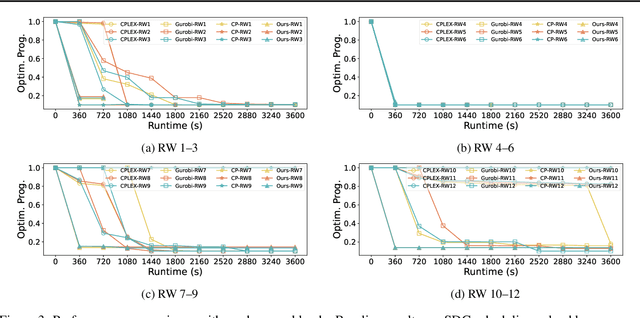
This paper addresses the complex issue of resource-constrained scheduling, an NP-hard problem that spans critical areas including chip design and high-performance computing. Traditional scheduling methods often stumble over scalability and applicability challenges. We propose a novel approach using a differentiable combinatorial scheduling framework, utilizing Gumbel-Softmax differentiable sampling technique. This new technical allows for a fully differentiable formulation of linear programming (LP) based scheduling, extending its application to a broader range of LP formulations. To encode inequality constraints for scheduling tasks, we introduce \textit{constrained Gumbel Trick}, which adeptly encodes arbitrary inequality constraints. Consequently, our method facilitates an efficient and scalable scheduling via gradient descent without the need for training data. Comparative evaluations on both synthetic and real-world benchmarks highlight our capability to significantly improve the optimization efficiency of scheduling, surpassing state-of-the-art solutions offered by commercial and open-source solvers such as CPLEX, Gurobi, and CP-SAT in the majority of the designs.
Learning from Students: Applying t-Distributions to Explore Accurate and Efficient Formats for LLMs
May 06, 2024



Large language models (LLMs) have recently achieved state-of-the-art performance across various tasks, yet due to their large computational requirements, they struggle with strict latency and power demands. Deep neural network (DNN) quantization has traditionally addressed these limitations by converting models to low-precision integer formats. Yet recently alternative formats, such as Normal Float (NF4), have been shown to consistently increase model accuracy, albeit at the cost of increased chip area. In this work, we first conduct a large-scale analysis of LLM weights and activations across 30 networks to conclude most distributions follow a Student's t-distribution. We then derive a new theoretically optimal format, Student Float (SF4), with respect to this distribution, that improves over NF4 across modern LLMs, for example increasing the average accuracy on LLaMA2-7B by 0.76% across tasks. Using this format as a high-accuracy reference, we then propose augmenting E2M1 with two variants of supernormal support for higher model accuracy. Finally, we explore the quality and performance frontier across 11 datatypes, including non-traditional formats like Additive-Powers-of-Two (APoT), by evaluating their model accuracy and hardware complexity. We discover a Pareto curve composed of INT4, E2M1, and E2M1 with supernormal support, which offers a continuous tradeoff between model accuracy and chip area. For example, E2M1 with supernormal support increases the accuracy of Phi-2 by up to 2.19% with 1.22% area overhead, enabling more LLM-based applications to be run at four bits.