 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHALO: Hardware-aware quantization with low critical-path-delay weights for LLM acceleration
Feb 27, 2025



Quantization is critical for realizing efficient inference of LLMs. Traditional quantization methods are hardware-agnostic, limited to bit-width constraints, and lacking circuit-level insights, such as timing and energy characteristics of Multiply-Accumulate (MAC) units. We introduce HALO, a versatile framework that adapts to various hardware through a Hardware-Aware Post-Training Quantization (PTQ) approach. By leveraging MAC unit properties, HALO minimizes critical-path delays and enables dynamic frequency scaling. Deployed on LLM accelerators like TPUs and GPUs, HALO achieves on average 270% performance gains and 51% energy savings, all with minimal accuracy drop.
Attamba: Attending To Multi-Token States
Nov 26, 2024



When predicting the next token in a sequence, vanilla transformers compute attention over all previous tokens, resulting in quadratic scaling of compute with sequence length. State-space models compress the entire sequence of tokens into a fixed-dimensional representation to improve efficiency, while other architectures achieve sub-quadratic complexity via low-rank projections or sparse attention patterns over the sequence. In this paper, we introduce Attamba, a novel architecture that uses state-space models to compress chunks of tokens and applies attention on these compressed key-value representations. We find that replacing key and value projections in a transformer with SSMs can improve model quality and enable flexible token chunking, resulting in 24% improved perplexity with transformer of similar KV-Cache and attention footprint, and ~4 times smaller KV-Cache and Attention FLOPs for 5% perplexity trade-off. Attamba can perform attention on chunked-sequences of variable length, enabling a smooth transition between quadratic and linear scaling, offering adaptable efficiency gains.
ShadowLLM: Predictor-based Contextual Sparsity for Large Language Models
Jun 24, 2024



The high power consumption and latency-sensitive deployments of large language models (LLMs) have motivated techniques like quantization and sparsity. Contextual sparsity, where the sparsity pattern is input-dependent, is crucial in LLMs because the permanent removal of attention heads or neurons from LLMs can significantly degrade accuracy. Prior work has attempted to model contextual sparsity using neural networks trained to predict activation magnitudes, which can be used to dynamically prune structures with low predicted activation magnitude. In this paper, we look beyond magnitude-based pruning criteria to assess attention head and neuron importance in LLMs. We developed a novel predictor called ShadowLLM, which can shadow the LLM behavior and enforce better sparsity patterns, resulting in over 15% improvement in end-to-end accuracy without increasing latency compared to previous methods. ShadowLLM achieves up to a 20\% speed-up over the state-of-the-art DejaVu framework. These enhancements are validated on models with up to 30 billion parameters. Our code is available at \href{https://github.com/abdelfattah-lab/shadow_llm/}{ShadowLLM}.
A Full-stack Accelerator Search Technique for Vision Applications
May 26, 2021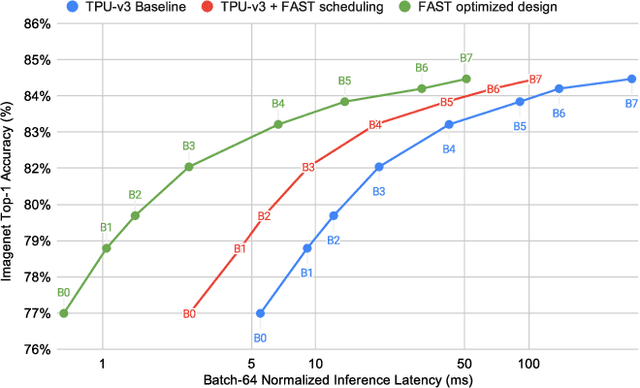
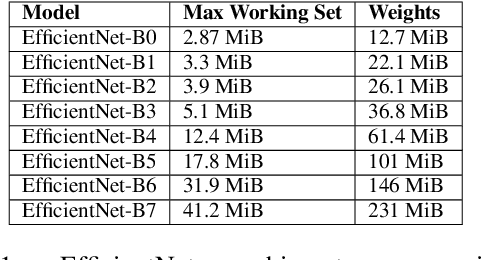

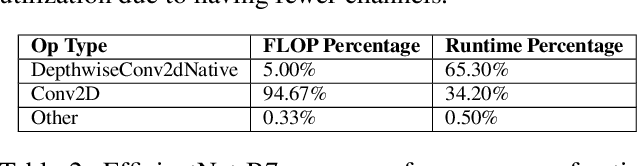
The rapidly-changing ML model landscape presents a unique opportunity for building hardware accelerators optimized for specific datacenter-scale workloads. We propose Full-stack Accelerator Search Technique (FAST), a hardware accelerator search framework that defines a broad optimization environment covering key design decisions within the hardware-software stack, including hardware datapath, software scheduling, and compiler passes such as operation fusion and tensor padding. Although FAST can be used on any number and type of deep learning workload, in this paper we focus on optimizing for a single or small set of vision models, resulting in significantly faster and more power-efficient designs relative to a general purpose ML accelerator. When evaluated on EfficientNet, ResNet50v2, and OCR inference performance relative to a TPU-v3, designs generated by FAST optimized for single workloads can improve Perf/TDP (peak power) by over 6x in the best case and 4x on average. On a limited workload subset, FAST improves Perf/TDP 2.85x on average, with a reduction to 2.35x for a single design optimized over the set of workloads. In addition, we demonstrate a potential 1.8x speedup opportunity for TPU-v3 with improved scheduling.