 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Full-stack Accelerator Search Technique for Vision Applications
Paper and Code
May 26, 2021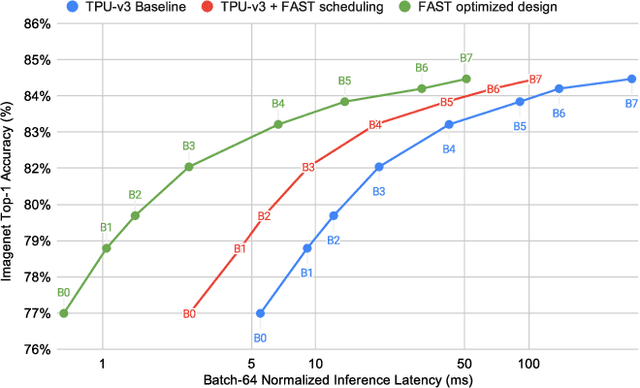
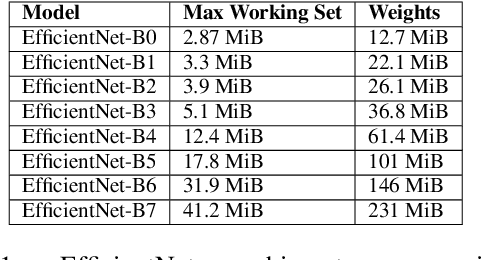

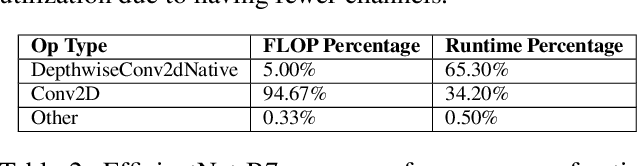
The rapidly-changing ML model landscape presents a unique opportunity for building hardware accelerators optimized for specific datacenter-scale workloads. We propose Full-stack Accelerator Search Technique (FAST), a hardware accelerator search framework that defines a broad optimization environment covering key design decisions within the hardware-software stack, including hardware datapath, software scheduling, and compiler passes such as operation fusion and tensor padding. Although FAST can be used on any number and type of deep learning workload, in this paper we focus on optimizing for a single or small set of vision models, resulting in significantly faster and more power-efficient designs relative to a general purpose ML accelerator. When evaluated on EfficientNet, ResNet50v2, and OCR inference performance relative to a TPU-v3, designs generated by FAST optimized for single workloads can improve Perf/TDP (peak power) by over 6x in the best case and 4x on average. On a limited workload subset, FAST improves Perf/TDP 2.85x on average, with a reduction to 2.35x for a single design optimized over the set of workloads. In addition, we demonstrate a potential 1.8x speedup opportunity for TPU-v3 with improved scheduling.