 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSee it to Place it: Evolving Macro Placements with Vision-Language Models
Mar 30, 2026We propose using Vision-Language Models (VLMs) for macro placement in chip floorplanning, a complex optimization task that has recently shown promising advancements through machine learning methods. Because human designers rely heavily on spatial reasoning to arrange components on the chip canvas, we hypothesize that VLMs with strong visual reasoning abilities can effectively complement existing learning-based approaches. We introduce VeoPlace (Visual Evolutionary Optimization Placement), a novel framework that uses a VLM, without any fine-tuning, to guide the actions of a base placer by constraining them to subregions of the chip canvas. The VLM proposals are iteratively optimized through an evolutionary search strategy with respect to resulting placement quality. On open-source benchmarks, VeoPlace outperforms the best prior learning-based approach on 9 of 10 benchmarks with peak wirelength reductions exceeding 32%. We further demonstrate that VeoPlace generalizes to analytical placers, improving DREAMPlace performance on all 8 evaluated benchmarks with gains up to 4.3%. Our approach opens new possibilities for electronic design automation tools that leverage foundation models to solve complex physical design problems.
Delving into Macro Placement with Reinforcement Learning
Sep 06, 2021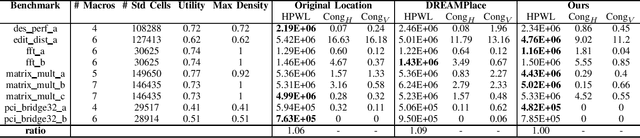
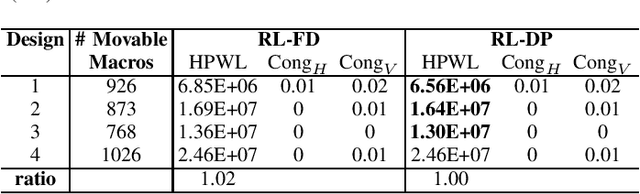
In physical design, human designers typically place macros via trial and error, which is a Markov decision process. Reinforcement learning (RL) methods have demonstrated superhuman performance on the macro placement. In this paper, we propose an extension to this prior work (Mirhoseini et al., 2020). We first describe the details of the policy and value network architecture. We replace the force-directed method with DREAMPlace for placing standard cells in the RL environment. We also compare our improved method with other academic placers on public benchmarks.
A Full-stack Accelerator Search Technique for Vision Applications
May 26, 2021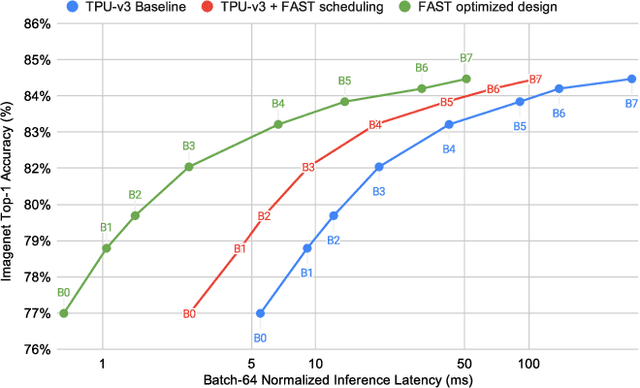
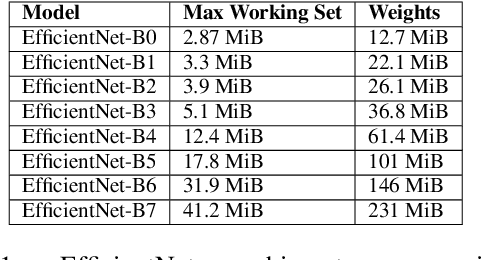

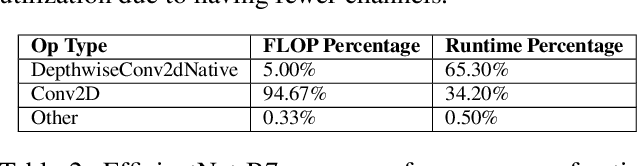
The rapidly-changing ML model landscape presents a unique opportunity for building hardware accelerators optimized for specific datacenter-scale workloads. We propose Full-stack Accelerator Search Technique (FAST), a hardware accelerator search framework that defines a broad optimization environment covering key design decisions within the hardware-software stack, including hardware datapath, software scheduling, and compiler passes such as operation fusion and tensor padding. Although FAST can be used on any number and type of deep learning workload, in this paper we focus on optimizing for a single or small set of vision models, resulting in significantly faster and more power-efficient designs relative to a general purpose ML accelerator. When evaluated on EfficientNet, ResNet50v2, and OCR inference performance relative to a TPU-v3, designs generated by FAST optimized for single workloads can improve Perf/TDP (peak power) by over 6x in the best case and 4x on average. On a limited workload subset, FAST improves Perf/TDP 2.85x on average, with a reduction to 2.35x for a single design optimized over the set of workloads. In addition, we demonstrate a potential 1.8x speedup opportunity for TPU-v3 with improved scheduling.
Chip Placement with Deep Reinforcement Learning
Apr 22, 2020

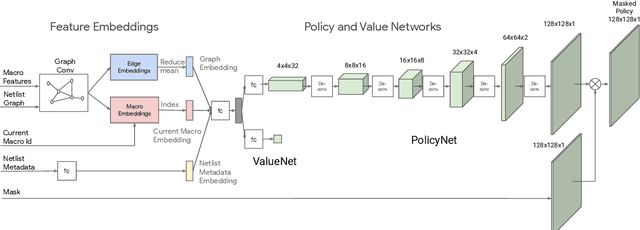
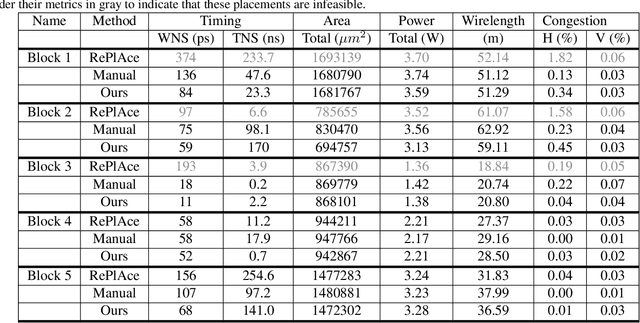
In this work, we present a learning-based approach to chip placement, one of the most complex and time-consuming stages of the chip design process. Unlike prior methods, our approach has the ability to learn from past experience and improve over time. In particular, as we train over a greater number of chip blocks, our method becomes better at rapidly generating optimized placements for previously unseen chip blocks. To achieve these results, we pose placement as a Reinforcement Learning (RL) problem and train an agent to place the nodes of a chip netlist onto a chip canvas. To enable our RL policy to generalize to unseen blocks, we ground representation learning in the supervised task of predicting placement quality. By designing a neural architecture that can accurately predict reward across a wide variety of netlists and their placements, we are able to generate rich feature embeddings of the input netlists. We then use this architecture as the encoder of our policy and value networks to enable transfer learning. Our objective is to minimize PPA (power, performance, and area), and we show that, in under 6 hours, our method can generate placements that are superhuman or comparable on modern accelerator netlists, whereas existing baselines require human experts in the loop and take several weeks.