 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnnotation-Free Open-Vocabulary Segmentation for Remote-Sensing Images
Aug 25, 2025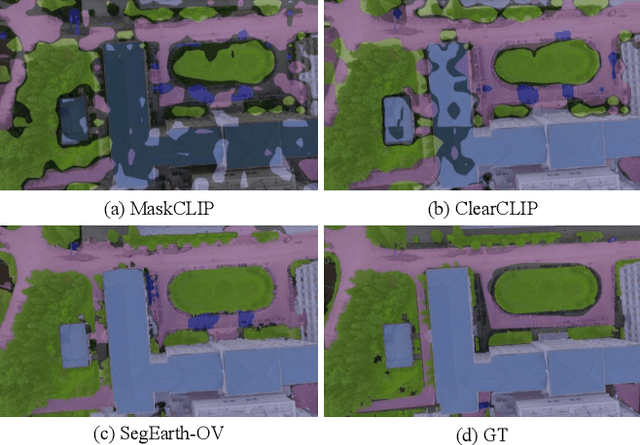
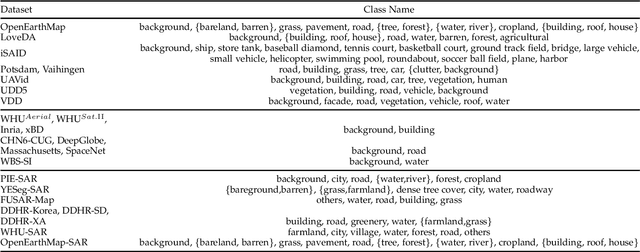
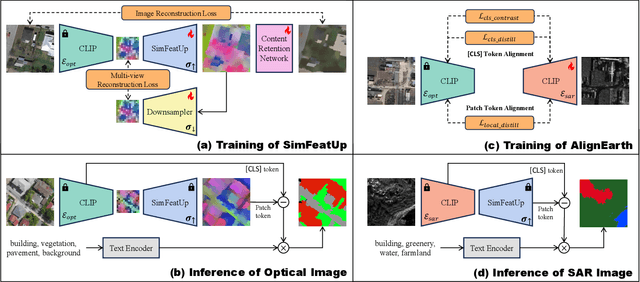
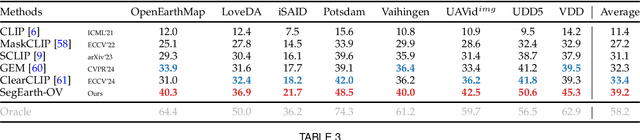
Semantic segmentation of remote sensing (RS) images is pivotal for comprehensive Earth observation, but the demand for interpreting new object categories, coupled with the high expense of manual annotation, poses significant challenges. Although open-vocabulary semantic segmentation (OVSS) offers a promising solution, existing frameworks designed for natural images are insufficient for the unique complexities of RS data. They struggle with vast scale variations and fine-grained details, and their adaptation often relies on extensive, costly annotations. To address this critical gap, this paper introduces SegEarth-OV, the first framework for annotation-free open-vocabulary segmentation of RS images. Specifically, we propose SimFeatUp, a universal upsampler that robustly restores high-resolution spatial details from coarse features, correcting distorted target shapes without any task-specific post-training. We also present a simple yet effective Global Bias Alleviation operation to subtract the inherent global context from patch features, significantly enhancing local semantic fidelity. These components empower SegEarth-OV to effectively harness the rich semantics of pre-trained VLMs, making OVSS possible in optical RS contexts. Furthermore, to extend the framework's universality to other challenging RS modalities like SAR images, where large-scale VLMs are unavailable and expensive to create, we introduce AlignEarth, which is a distillation-based strategy and can efficiently transfer semantic knowledge from an optical VLM encoder to an SAR encoder, bypassing the need to build SAR foundation models from scratch and enabling universal OVSS across diverse sensor types. Extensive experiments on both optical and SAR datasets validate that SegEarth-OV can achieve dramatic improvements over the SOTA methods, establishing a robust foundation for annotation-free and open-world Earth observation.
Hierarchical Multi-Label Contrastive Learning for Protein-Protein Interaction Prediction Across Organisms
Jul 03, 2025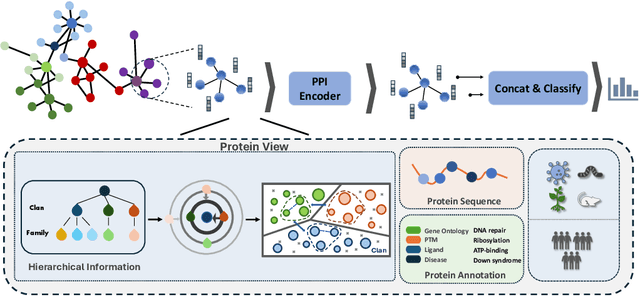
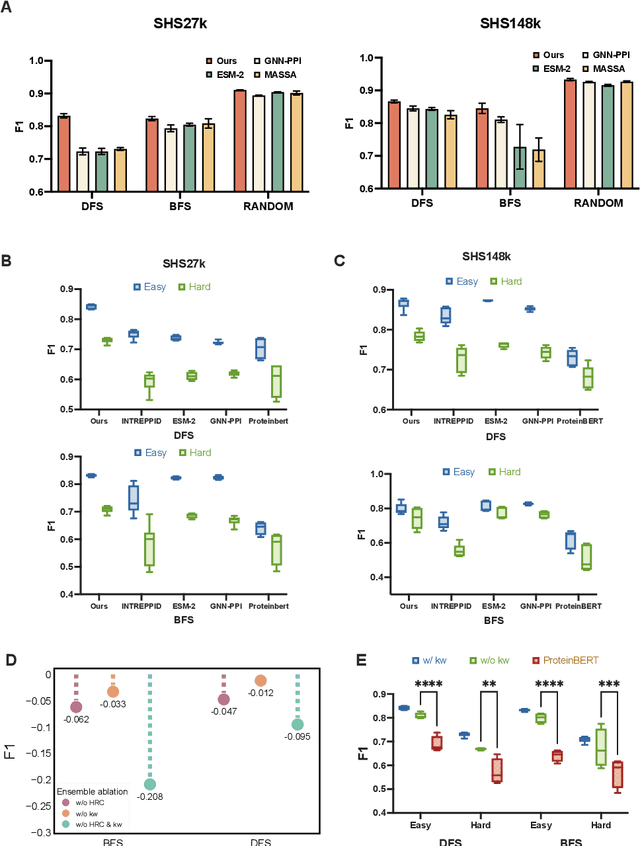
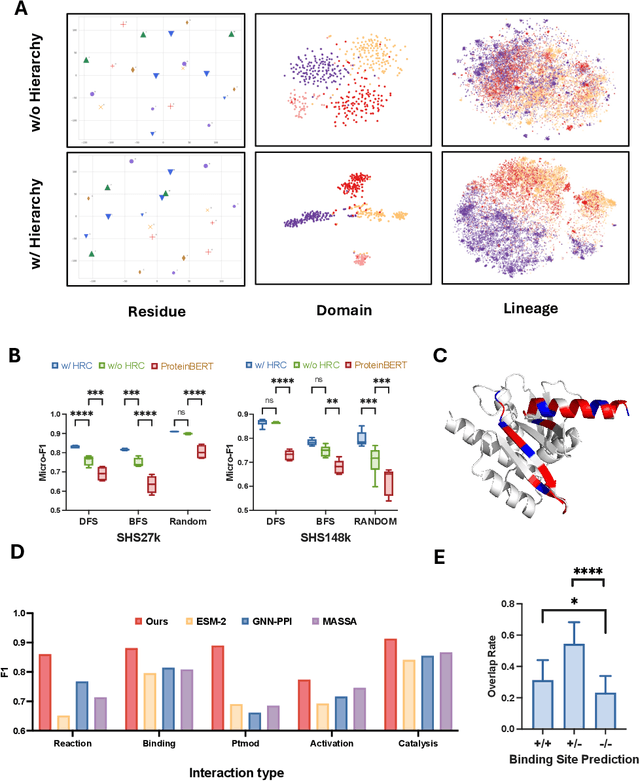
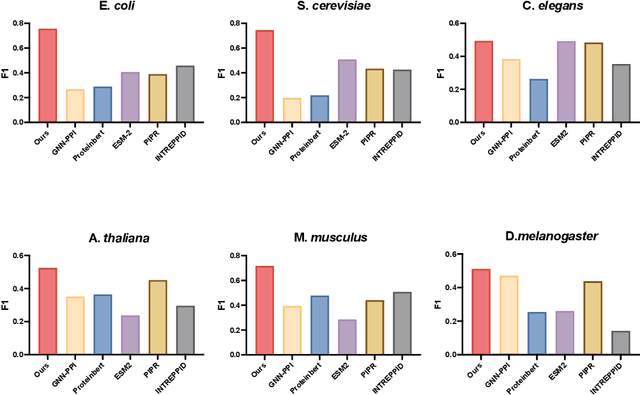
Recent advances in AI for science have highlighted the power of contrastive learning in bridging heterogeneous biological data modalities. Building on this paradigm, we propose HIPPO (HIerarchical Protein-Protein interaction prediction across Organisms), a hierarchical contrastive framework for protein-protein interaction(PPI) prediction, where protein sequences and their hierarchical attributes are aligned through multi-tiered biological representation matching. The proposed approach incorporates hierarchical contrastive loss functions that emulate the structured relationship among functional classes of proteins. The framework adaptively incorporates domain and family knowledge through a data-driven penalty mechanism, enforcing consistency between the learned embedding space and the intrinsic hierarchy of protein functions. Experiments on benchmark datasets demonstrate that HIPPO achieves state-of-the-art performance, outperforming existing methods and showing robustness in low-data regimes. Notably, the model demonstrates strong zero-shot transferability to other species without retraining, enabling reliable PPI prediction and functional inference even in less characterized or rare organisms where experimental data are limited. Further analysis reveals that hierarchical feature fusion is critical for capturing conserved interaction determinants, such as binding motifs and functional annotations. This work advances cross-species PPI prediction and provides a unified framework for interaction prediction in scenarios with sparse or imbalanced multi-species data.
AnnoDPO: Protein Functional Annotation Learning with Direct Preference Optimization
Jun 08, 2025Deciphering protein function remains a fundamental challenge in protein representation learning. The task presents significant difficulties for protein language models (PLMs) due to the sheer volume of functional annotation categories and the highly imbalanced distribution of annotated instances across biological ontologies. Inspired by the remarkable success of reinforcement learning from human feedback (RLHF) in large language model (LLM) alignment, we propose AnnoDPO, a novel multi-modal framework for protein function prediction that leverages Direct Preference Optimization (DPO) to enhance annotation learning. Our methodology addresses the dual challenges of annotation scarcity and category imbalance through preference-aligned training objectives, establishing a new paradigm for biological knowledge integration in protein representation learning.
Multi-Floor Zero-Shot Object Navigation Policy
Sep 17, 2024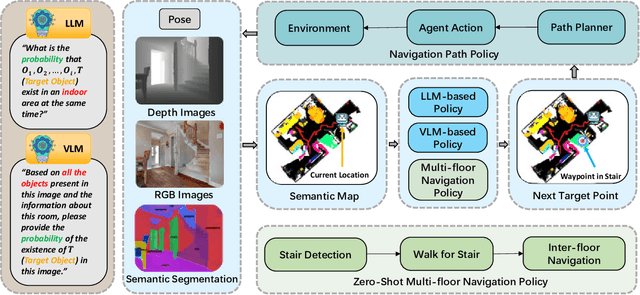
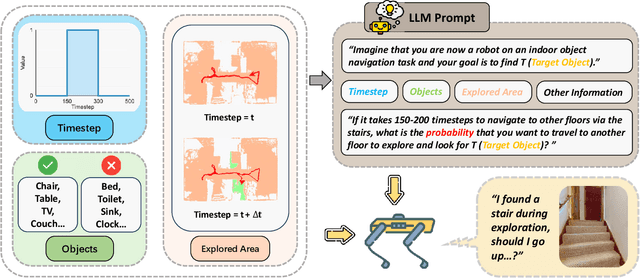


Object navigation in multi-floor environments presents a formidable challenge in robotics, requiring sophisticated spatial reasoning and adaptive exploration strategies. Traditional approaches have primarily focused on single-floor scenarios, overlooking the complexities introduced by multi-floor structures. To address these challenges, we first propose a Multi-floor Navigation Policy (MFNP) and implement it in Zero-Shot object navigation tasks. Our framework comprises three key components: (i) Multi-floor Navigation Policy, which enables an agent to explore across multiple floors; (ii) Multi-modal Large Language Models (MLLMs) for reasoning in the navigation process; and (iii) Inter-Floor Navigation, ensuring efficient floor transitions. We evaluate MFNP on the Habitat-Matterport 3D (HM3D) and Matterport 3D (MP3D) datasets, both include multi-floor scenes. Our experiment results demonstrate that MFNP significantly outperforms all the existing methods in Zero-Shot object navigation, achieving higher success rates and improved exploration efficiency. Ablation studies further highlight the effectiveness of each component in addressing the unique challenges of multi-floor navigation. Meanwhile, we conducted real-world experiments to evaluate the feasibility of our policy. Upon deployment of MFNP, the Unitree quadruped robot demonstrated successful multi-floor navigation and found the target object in a completely unseen environment. By introducing MFNP, we offer a new paradigm for tackling complex, multi-floor environments in object navigation tasks, opening avenues for future research in visual-based navigation in realistic, multi-floor settings.
TriHelper: Zero-Shot Object Navigation with Dynamic Assistance
Mar 22, 2024



Navigating toward specific objects in unknown environments without additional training, known as Zero-Shot object navigation, poses a significant challenge in the field of robotics, which demands high levels of auxiliary information and strategic planning. Traditional works have focused on holistic solutions, overlooking the specific challenges agents encounter during navigation such as collision, low exploration efficiency, and misidentification of targets. To address these challenges, our work proposes TriHelper, a novel framework designed to assist agents dynamically through three primary navigation challenges: collision, exploration, and detection. Specifically, our framework consists of three innovative components: (i) Collision Helper, (ii) Exploration Helper, and (iii) Detection Helper. These components work collaboratively to solve these challenges throughout the navigation process. Experiments on the Habitat-Matterport 3D (HM3D) and Gibson datasets demonstrate that TriHelper significantly outperforms all existing baseline methods in Zero-Shot object navigation, showcasing superior success rates and exploration efficiency. Our ablation studies further underscore the effectiveness of each helper in addressing their respective challenges, notably enhancing the agent's navigation capabilities. By proposing TriHelper, we offer a fresh perspective on advancing the object navigation task, paving the way for future research in the domain of Embodied AI and visual-based navigation.
M3ICRO: Machine Learning-Enabled Compact Photonic Tensor Core based on PRogrammable Multi-Operand Multimode Interference
May 31, 2023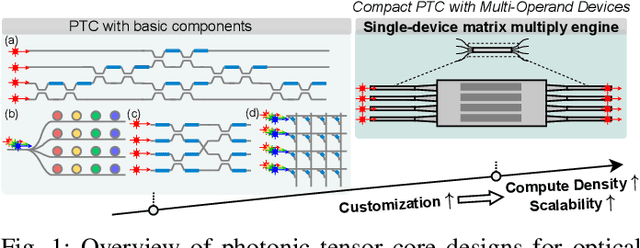
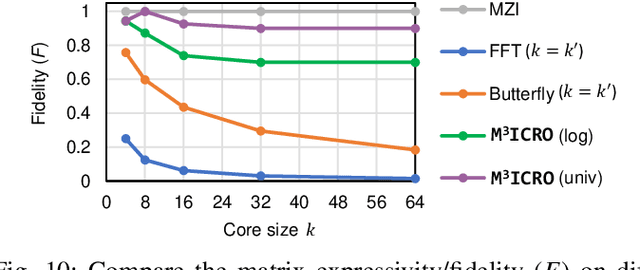
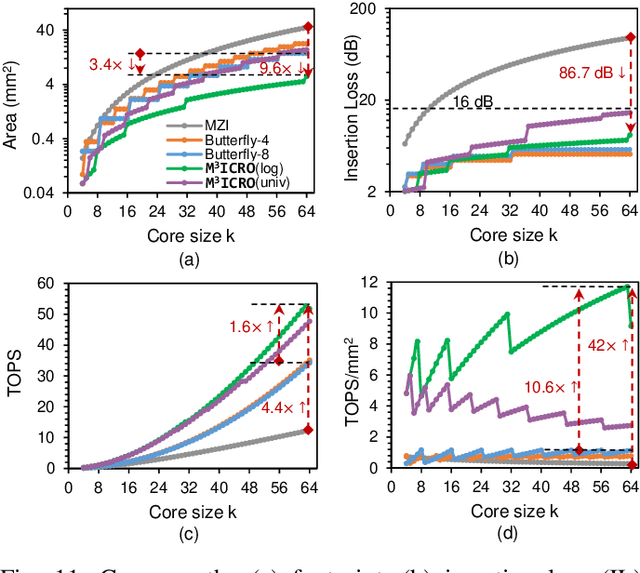
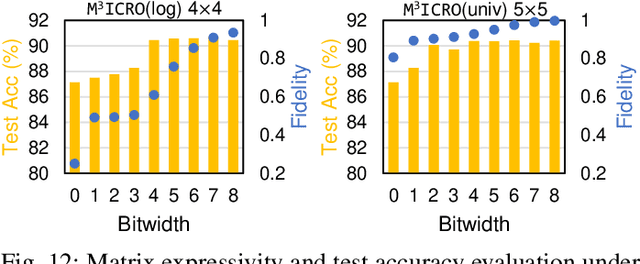
Photonic computing shows promise for transformative advancements in machine learning (ML) acceleration, offering ultra-fast speed, massive parallelism, and high energy efficiency. However, current photonic tensor core (PTC) designs based on standard optical components hinder scalability and compute density due to their large spatial footprint. To address this, we propose an ultra-compact PTC using customized programmable multi-operand multimode interference (MOMMI) devices, named M3ICRO. The programmable MOMMI leverages the intrinsic light propagation principle, providing a single-device programmable matrix unit beyond the conventional computing paradigm of one multiply-accumulate (MAC) operation per device. To overcome the optimization difficulty of customized devices that often requires time-consuming simulation, we apply ML for optics to predict the device behavior and enable a differentiable optimization flow. We thoroughly investigate the reconfigurability and matrix expressivity of our customized PTC, and introduce a novel block unfolding method to fully exploit the computing capabilities of a complex-valued PTC for near-universal real-valued linear transformations. Extensive evaluations demonstrate that M3ICRO achieves a 3.4-9.6x smaller footprint, 1.6-4.4x higher speed, 10.6-42x higher compute density, 3.7-12x higher system throughput, and superior noise robustness compared to state-of-the-art coherent PTC designs, while maintaining close-to-digital task accuracy across various ML benchmarks. Our code is open-sourced at https://github.com/JeremieMelo/M3ICRO-MOMMI.
Pre-RMSNorm and Pre-CRMSNorm Transformers: Equivalent and Efficient Pre-LN Transformers
May 24, 2023



Transformers have achieved great success in machine learning applications. Normalization techniques, such as Layer Normalization (LayerNorm, LN) and Root Mean Square Normalization (RMSNorm), play a critical role in accelerating and stabilizing the training of Transformers. While LayerNorm recenters and rescales input vectors, RMSNorm only rescales the vectors by their RMS value. Despite being more computationally efficient, RMSNorm may compromise the representation ability of Transformers. There is currently no consensus regarding the preferred normalization technique, as some models employ LayerNorm while others utilize RMSNorm, especially in recent large language models. It is challenging to convert Transformers with one normalization to the other type. While there is an ongoing disagreement between the two normalization types, we propose a solution to unify two mainstream Transformer architectures, Pre-LN and Pre-RMSNorm Transformers. By removing the inherent redundant mean information in the main branch of Pre-LN Transformers, we can reduce LayerNorm to RMSNorm, achieving higher efficiency. We further propose the Compressed RMSNorm (CRMSNorm) and Pre-CRMSNorm Transformer based on a lossless compression of the zero-mean vectors. We formally establish the equivalence of Pre-LN, Pre-RMSNorm, and Pre-CRMSNorm Transformer variants in both training and inference. It implies that Pre-LN Transformers can be substituted with Pre-(C)RMSNorm counterparts at almost no cost, offering the same arithmetic functionality along with free efficiency improvement. Experiments demonstrate that we can reduce the training and inference time of Pre-LN Transformers by up to 10%.
PC-SNN: Supervised Learning with Local Hebbian Synaptic Plasticity based on Predictive Coding in Spiking Neural Networks
Nov 24, 2022Deemed as the third generation of neural networks, the event-driven Spiking Neural Networks(SNNs) combined with bio-plausible local learning rules make it promising to build low-power, neuromorphic hardware for SNNs. However, because of the non-linearity and discrete property of spiking neural networks, the training of SNN remains difficult and is still under discussion. Originating from gradient descent, backprop has achieved stunning success in multi-layer SNNs. Nevertheless, it is assumed to lack biological plausibility, while consuming relatively high computational resources. In this paper, we propose a novel learning algorithm inspired by predictive coding theory and show that it can perform supervised learning fully autonomously and successfully as the backprop, utilizing only local Hebbian plasticity. Furthermore, this method achieves a favorable performance compared to the state-of-the-art multi-layer SNNs: test accuracy of 99.25% for the Caltech Face/Motorbike dataset, 84.25% for the ETH-80 dataset, 98.1% for the MNIST dataset and 98.5% for the neuromorphic dataset: N-MNIST. Furthermore, our work provides a new perspective on how supervised learning algorithms are directly implemented in spiking neural circuitry, which may give some new insights into neuromorphological calculation in neuroscience.
Delving into Effective Gradient Matching for Dataset Condensation
Jul 30, 2022

As deep learning models and datasets rapidly scale up, network training is extremely time-consuming and resource-costly. Instead of training on the entire dataset, learning with a small synthetic dataset becomes an efficient solution. Extensive research has been explored in the direction of dataset condensation, among which gradient matching achieves state-of-the-art performance. The gradient matching method directly targets the training dynamics by matching the gradient when training on the original and synthetic datasets. However, there are limited deep investigations into the principle and effectiveness of this method. In this work, we delve into the gradient matching method from a comprehensive perspective and answer the critical questions of what, how, and where to match. We propose to match the multi-level gradients to involve both intra-class and inter-class gradient information. We demonstrate that the distance function should focus on the angle, considering the magnitude simultaneously to delay the overfitting. An overfitting-aware adaptive learning step strategy is also proposed to trim unnecessary optimization steps for algorithmic efficiency improvement. Ablation and comparison experiments demonstrate that our proposed methodology shows superior accuracy, efficiency, and generalization compared to prior work.
ELight: Enabling Efficient Photonic In-Memory Neurocomputing with Life Enhancement
Dec 15, 2021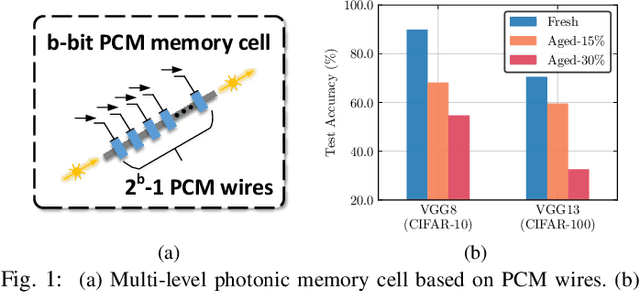
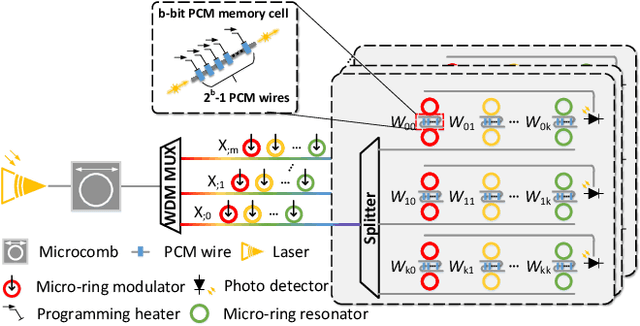
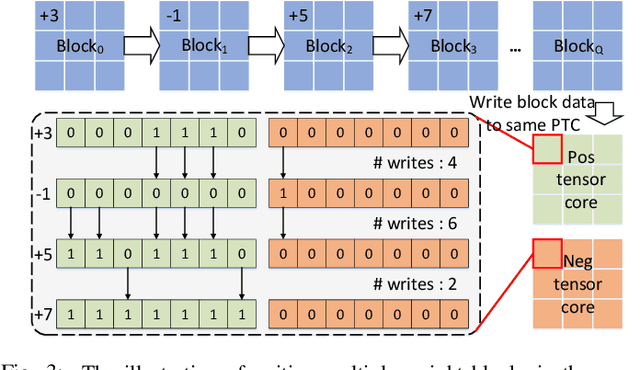
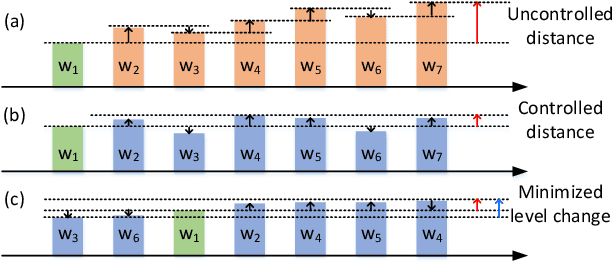
With the recent advances in optical phase change material (PCM), photonic in-memory neurocomputing has demonstrated its superiority in optical neural network (ONN) designs with near-zero static power consumption, time-of-light latency, and compact footprint. However, photonic tensor cores require massive hardware reuse to implement large matrix multiplication due to the limited single-core scale. The resultant large number of PCM writes leads to serious dynamic power and overwhelms the fragile PCM with limited write endurance. In this work, we propose a synergistic optimization framework, ELight, to minimize the overall write efforts for efficient and reliable optical in-memory neurocomputing. We first propose write-aware training to encourage the similarity among weight blocks, and combine it with a post-training optimization method to reduce programming efforts by eliminating redundant writes. Experiments show that ELight can achieve over 20X reduction in the total number of writes and dynamic power with comparable accuracy. With our ELight, photonic in-memory neurocomputing will step forward towards viable applications in machine learning with preserved accuracy, order-of-magnitude longer lifetime, and lower programming energy.