 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProCUA-SFT Technical Report
Jun 15, 2026Training computer-use agents (CUAs) -- models that interact with graphical desktops through screenshots and keyboard/mouse actions -- requires large-scale, diverse trajectory data collected in full desktop environments. The largest public resource, AgentNet (22.5K human trajectories), leads to negative transfer when used for supervised fine-tuning (SFT): continuing training UI-TARS 7B on AgentNet causes OSWorld success rate to fall from 26.3% to 8-10%. We present ProCUA-SFT, a dataset of 3.1M step-level SFT samples distilled from 93K synthetic trajectories across 2,484 application combinations. The dataset is produced by a fully automated pipeline that (i) synthesizes grounded tasks on live desktops seeded with real-world content -- 912 spreadsheets from SpreadsheetBench, approximately 10K permissively-licensed presentations from Zenodo10K, and multi-application OSWorld configs -- and (ii) verifies each task's feasibility through binary precondition checking before rollout. A single VLM (Kimi-K2.5) serves as goal generator, precondition judge, and trajectory executor, eliminating planner-actor capability gaps. Each trajectory is expanded into step-prefix samples that exactly reproduce the context layout seen at inference time. Fine-tuning UI-TARS 7B on ProCUA-SFT for one epoch yields 45.0% on OSWorld -- an 18.7 percentage-point improvement over the base model and over 35% above AgentNet-trained counterparts. A subset of ProCUA was incorporated into the training data for the Nemotron 3 Nano Omni model, contributing to its computer-use capabilities.
RE-VLM: Event-Augmented Vision-Language Model for Scene Understanding
May 21, 2026Conventional vision-language models (VLMs) struggle to interpret scenes captured under adverse conditions (e.g., low light, high dynamic range, or fast motion) because standard RGB images degrade in such environments. Event cameras provide a complementary modality: they asynchronously record per-pixel brightness changes with high temporal resolution and wide dynamic range, preserving motion cues where frames fail. We propose RE-VLM, the first dual-stream vision-language model that jointly leverages RGB images and event streams for robust scene understanding across both normal and challenging conditions. RE-VLM employs parallel RGB and event encoders together with a progressive training strategy that aligns heterogeneous visual features with language. To address the scarcity of RGB-Event-Text supervision, we further propose a graph-driven pipeline that converts synchronized RGB-Event streams into verifiable scene graphs, from which we synthesize captions and question-answer (QA) pairs. To develop and evaluate RE-VLM, we construct two datasets: PEOD-Chat, targeting illumination-challenged scenes, and RGBE-Chat, covering diverse scenarios. On captioning and VQA benchmarks, RE-VLM consistently outperforms state-of-the-art RGB-only and event-only models with comparable parameter counts, with particularly large gains under challenging conditions. These results demonstrate the effectiveness of event-augmented VLMs in achieving robust vision-language understanding across a wide range of real-world environments.
Nemotron 3 Nano Omni: Efficient and Open Multimodal Intelligence
Apr 27, 2026We introduce Nemotron 3 Nano Omni, the latest model in the Nemotron multimodal series and the first to natively support audio inputs alongside text, images, and video. Nemotron 3 Nano Omni delivers consistent accuracy improvements over its predecessor, Nemotron Nano V2 VL, across all modalities, enabled by advances in architecture, training data and recipes. In particular, Nemotron 3 delivers leading results in real-world document understanding, long audio-video comprehension, and agentic computer use. Built on the highly efficient Nemotron 3 Nano 30B-A3B backbone, Nemotron 3 Nano Omni further incorporates innovative multimodal token-reduction techniques to deliver substantially lower inference latency and higher throughput than other models of similar size. We are releasing model checkpoints in BF16, FP8, and FP4 formats, along with portions of the training data and codebase to facilitate further research and development.
ProRL Agent: Rollout-as-a-Service for RL Training of Multi-Turn LLM Agents
Mar 19, 2026Multi-turn LLM agents are increasingly important for solving complex, interactive tasks, and reinforcement learning (RL) is a key ingredient for improving their long-horizon behavior. However, RL training requires generating large numbers of sandboxed rollout trajectories, and existing infrastructures often couple rollout orchestration with the training loop, making systems hard to migrate and maintain. Under the rollout-as-a-service philosophy, we present ProRL Agent , a scalable infrastructure that serves the full agentic rollout lifecycle through an API service. ProRL Agent also provides standardized and extensible sandbox environments that support diverse agentic tasks in rootless HPC settings. We validate ProRL Agent through RL training on software engineering, math, STEM, and coding tasks. ProRL Agent is open-sourced and integrated as part of NVIDIA NeMo Gym.
MolCrystalFlow: Molecular Crystal Structure Prediction via Flow Matching
Feb 17, 2026Molecular crystal structure prediction represents a grand challenge in computational chemistry due to large sizes of constituent molecules and complex intra- and intermolecular interactions. While generative modeling has revolutionized structure discovery for molecules, inorganic solids, and metal-organic frameworks, extending such approaches to fully periodic molecular crystals is still elusive. Here, we present MolCrystalFlow, a flow-based generative model for molecular crystal structure prediction. The framework disentangles intramolecular complexity from intermolecular packing by embedding molecules as rigid bodies and jointly learning the lattice matrix, molecular orientations, and centroid positions. Centroids and orientations are represented on their native Riemannian manifolds, allowing geodesic flow construction and graph neural network operations that respects geometric symmetries. We benchmark our model against state-of-the-art generative models for large-size periodic crystals and rule-based structure generation methods on two open-source molecular crystal datasets. We demonstrate an integration of MolCrystalFlow model with universal machine learning potential to accelerate molecular crystal structure prediction, paving the way for data-driven generative discovery of molecular crystals.
Golden Goose: A Simple Trick to Synthesize Unlimited RLVR Tasks from Unverifiable Internet Text
Jan 30, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has become a cornerstone for unlocking complex reasoning in Large Language Models (LLMs). Yet, scaling up RL is bottlenecked by limited existing verifiable data, where improvements increasingly saturate over prolonged training. To overcome this, we propose Golden Goose, a simple trick to synthesize unlimited RLVR tasks from unverifiable internet text by constructing a multiple-choice question-answering version of the fill-in-the-middle task. Given a source text, we prompt an LLM to identify and mask key reasoning steps, then generate a set of diverse, plausible distractors. This enables us to leverage reasoning-rich unverifiable corpora typically excluded from prior RLVR data construction (e.g., science textbooks) to synthesize GooseReason-0.7M, a large-scale RLVR dataset with over 0.7 million tasks spanning mathematics, programming, and general scientific domains. Empirically, GooseReason effectively revives models saturated on existing RLVR data, yielding robust, sustained gains under continuous RL and achieving new state-of-the-art results for 1.5B and 4B-Instruct models across 15 diverse benchmarks. Finally, we deploy Golden Goose in a real-world setting, synthesizing RLVR tasks from raw FineWeb scrapes for the cybersecurity domain, where no prior RLVR data exists. Training Qwen3-4B-Instruct on the resulting data GooseReason-Cyber sets a new state-of-the-art in cybersecurity, surpassing a 7B domain-specialized model with extensive domain-specific pre-training and post-training. This highlights the potential of automatically scaling up RLVR data by exploiting abundant, reasoning-rich, unverifiable internet text.
MolGuidance: Advanced Guidance Strategies for Conditional Molecular Generation with Flow Matching
Dec 13, 2025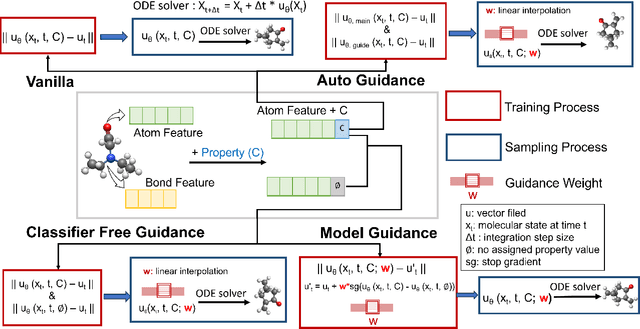

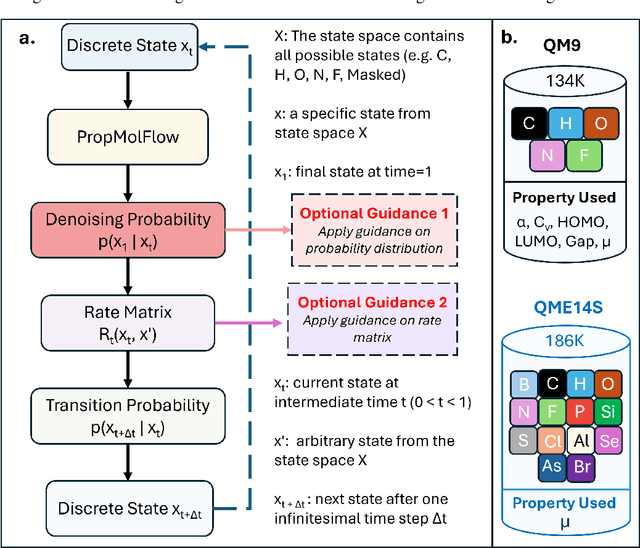
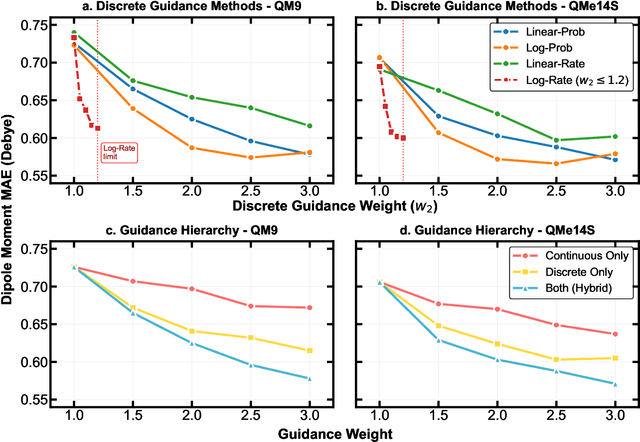
Key objectives in conditional molecular generation include ensuring chemical validity, aligning generated molecules with target properties, promoting structural diversity, and enabling efficient sampling for discovery. Recent advances in computer vision introduced a range of new guidance strategies for generative models, many of which can be adapted to support these goals. In this work, we integrate state-of-the-art guidance methods -- including classifier-free guidance, autoguidance, and model guidance -- in a leading molecule generation framework built on an SE(3)-equivariant flow matching process. We propose a hybrid guidance strategy that separately guides continuous and discrete molecular modalities -- operating on velocity fields and predicted logits, respectively -- while jointly optimizing their guidance scales via Bayesian optimization. Our implementation, benchmarked on the QM9 and QMe14S datasets, achieves new state-of-the-art performance in property alignment for de novo molecular generation. The generated molecules also exhibit high structural validity. Furthermore, we systematically compare the strengths and limitations of various guidance methods, offering insights into their broader applicability.
PEOD: A Pixel-Aligned Event-RGB Benchmark for Object Detection under Challenging Conditions
Nov 11, 2025Robust object detection for challenging scenarios increasingly relies on event cameras, yet existing Event-RGB datasets remain constrained by sparse coverage of extreme conditions and low spatial resolution (<= 640 x 480), which prevents comprehensive evaluation of detectors under challenging scenarios. To address these limitations, we propose PEOD, the first large-scale, pixel-aligned and high-resolution (1280 x 720) Event-RGB dataset for object detection under challenge conditions. PEOD contains 130+ spatiotemporal-aligned sequences and 340k manual bounding boxes, with 57% of data captured under low-light, overexposure, and high-speed motion. Furthermore, we benchmark 14 methods across three input configurations (Event-based, RGB-based, and Event-RGB fusion) on PEOD. On the full test set and normal subset, fusion-based models achieve the excellent performance. However, in illumination challenge subset, the top event-based model outperforms all fusion models, while fusion models still outperform their RGB-based counterparts, indicating limits of existing fusion methods when the frame modality is severely degraded. PEOD establishes a realistic, high-quality benchmark for multimodal perception and facilitates future research.
Reinforcement Learning Optimization for Large-Scale Learning: An Efficient and User-Friendly Scaling Library
Jun 06, 2025We introduce ROLL, an efficient, scalable, and user-friendly library designed for Reinforcement Learning Optimization for Large-scale Learning. ROLL caters to three primary user groups: tech pioneers aiming for cost-effective, fault-tolerant large-scale training, developers requiring flexible control over training workflows, and researchers seeking agile experimentation. ROLL is built upon several key modules to serve these user groups effectively. First, a single-controller architecture combined with an abstraction of the parallel worker simplifies the development of the training pipeline. Second, the parallel strategy and data transfer modules enable efficient and scalable training. Third, the rollout scheduler offers fine-grained management of each sample's lifecycle during the rollout stage. Fourth, the environment worker and reward worker support rapid and flexible experimentation with agentic RL algorithms and reward designs. Finally, AutoDeviceMapping allows users to assign resources to different models flexibly across various stages.
ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models
May 30, 2025Recent advances in reasoning-centric language models have highlighted reinforcement learning (RL) as a promising method for aligning models with verifiable rewards. However, it remains contentious whether RL truly expands a model's reasoning capabilities or merely amplifies high-reward outputs already latent in the base model's distribution, and whether continually scaling up RL compute reliably leads to improved reasoning performance. In this work, we challenge prevailing assumptions by demonstrating that prolonged RL (ProRL) training can uncover novel reasoning strategies that are inaccessible to base models, even under extensive sampling. We introduce ProRL, a novel training methodology that incorporates KL divergence control, reference policy resetting, and a diverse suite of tasks. Our empirical analysis reveals that RL-trained models consistently outperform base models across a wide range of pass@k evaluations, including scenarios where base models fail entirely regardless of the number of attempts. We further show that reasoning boundary improvements correlates strongly with task competence of base model and training duration, suggesting that RL can explore and populate new regions of solution space over time. These findings offer new insights into the conditions under which RL meaningfully expands reasoning boundaries in language models and establish a foundation for future work on long-horizon RL for reasoning. We release model weights to support further research: https://huggingface.co/nvidia/Nemotron-Research-Reasoning-Qwen-1.5B