 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDOCTOR: Dynamic On-Chip Remediation Against Temporally-Drifting Thermal Variations Toward Self-Corrected Photonic Tensor Accelerators
Mar 05, 2024Photonic computing has emerged as a promising solution for accelerating computation-intensive artificial intelligence (AI) workloads, offering unparalleled speed and energy efficiency, especially in resource-limited, latency-sensitive edge computing environments. However, the deployment of analog photonic tensor accelerators encounters reliability challenges due to hardware noises and environmental variations. While off-chip noise-aware training and on-chip training have been proposed to enhance the variation tolerance of optical neural accelerators with moderate, static noises, we observe a notable performance degradation over time due to temporally drifting variations, which requires a real-time, in-situ calibration mechanism. To tackle this challenging reliability issues, for the first time, we propose a lightweight dynamic on-chip remediation framework, dubbed DOCTOR, providing adaptive, in-situ accuracy recovery against temporally drifting noises. The DOCTOR framework intelligently monitors the chip status using adaptive probing and performs fast in-situ training-free calibration to restore accuracy when necessary. Recognizing nonuniform spatial variation distributions across devices and tensor cores, we also propose a variation-aware architectural remapping strategy to avoid executing critical tasks on noisy devices. Extensive experiments show that our proposed framework can guarantee sustained performance under drifting variations with 34% higher accuracy and 2-3 orders-of-magnitude lower overhead compared to state-of-the-art on-chip training methods.
ChipNeMo: Domain-Adapted LLMs for Chip Design
Nov 13, 2023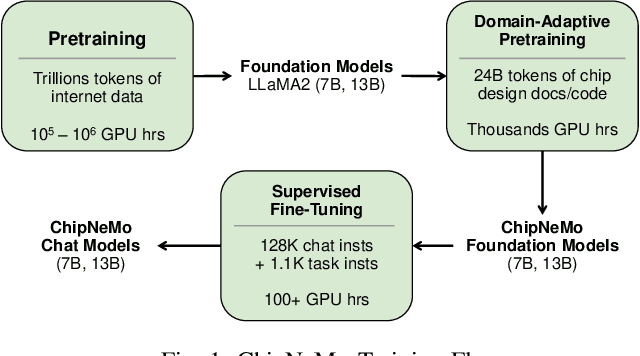
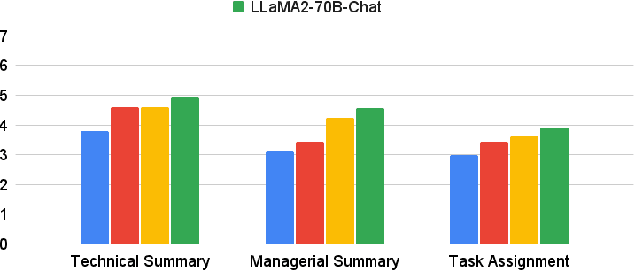
ChipNeMo aims to explore the applications of large language models (LLMs) for industrial chip design. Instead of directly deploying off-the-shelf commercial or open-source LLMs, we instead adopt the following domain adaptation techniques: custom tokenizers, domain-adaptive continued pretraining, supervised fine-tuning (SFT) with domain-specific instructions, and domain-adapted retrieval models. We evaluate these methods on three selected LLM applications for chip design: an engineering assistant chatbot, EDA script generation, and bug summarization and analysis. Our results show that these domain adaptation techniques enable significant LLM performance improvements over general-purpose base models across the three evaluated applications, enabling up to 5x model size reduction with similar or better performance on a range of design tasks. Our findings also indicate that there's still room for improvement between our current results and ideal outcomes. We believe that further investigation of domain-adapted LLM approaches will help close this gap in the future.
Analysis of Optical Loss and Crosstalk Noise in MZI-based Coherent Photonic Neural Networks
Aug 07, 2023



With the continuous increase in the size and complexity of machine learning models, the need for specialized hardware to efficiently run such models is rapidly growing. To address such a need, silicon-photonic-based neural network (SP-NN) accelerators have recently emerged as a promising alternative to electronic accelerators due to their lower latency and higher energy efficiency. Not only can SP-NNs alleviate the fan-in and fan-out problem with linear algebra processors, their operational bandwidth can match that of the photodetection rate (typically 100 GHz), which is at least over an order of magnitude faster than electronic counterparts that are restricted to a clock rate of a few GHz. Unfortunately, the underlying silicon photonic devices in SP-NNs suffer from inherent optical losses and crosstalk noise originating from fabrication imperfections and undesired optical couplings, the impact of which accumulates as the network scales up. Consequently, the inferencing accuracy in an SP-NN can be affected by such inefficiencies -- e.g., can drop to below 10% -- the impact of which is yet to be fully studied. In this paper, we comprehensively model the optical loss and crosstalk noise using a bottom-up approach, from the device to the system level, in coherent SP-NNs built using Mach-Zehnder interferometer (MZI) devices. The proposed models can be applied to any SP-NN architecture with different configurations to analyze the effect of loss and crosstalk. Such an analysis is important where there are inferencing accuracy and scalability requirements to meet when designing an SP-NN. Using the proposed analytical framework, we show a high power penalty and a catastrophic inferencing accuracy drop of up to 84% for SP-NNs of different scales with three known MZI mesh configurations (i.e., Reck, Clements, and Diamond) due to accumulated optical loss and crosstalk noise.
Characterizing Coherent Integrated Photonic Neural Networks under Imperfections
Jul 22, 2022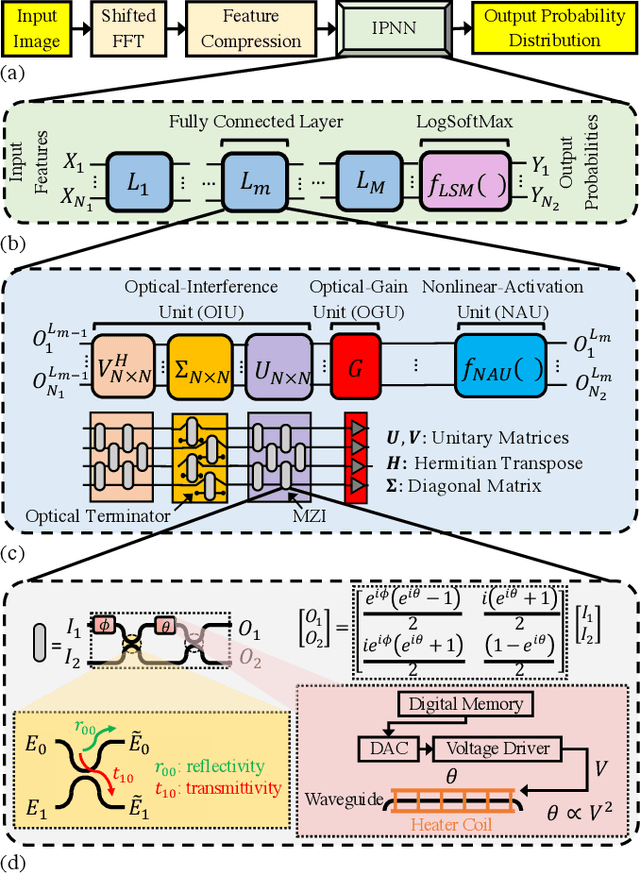
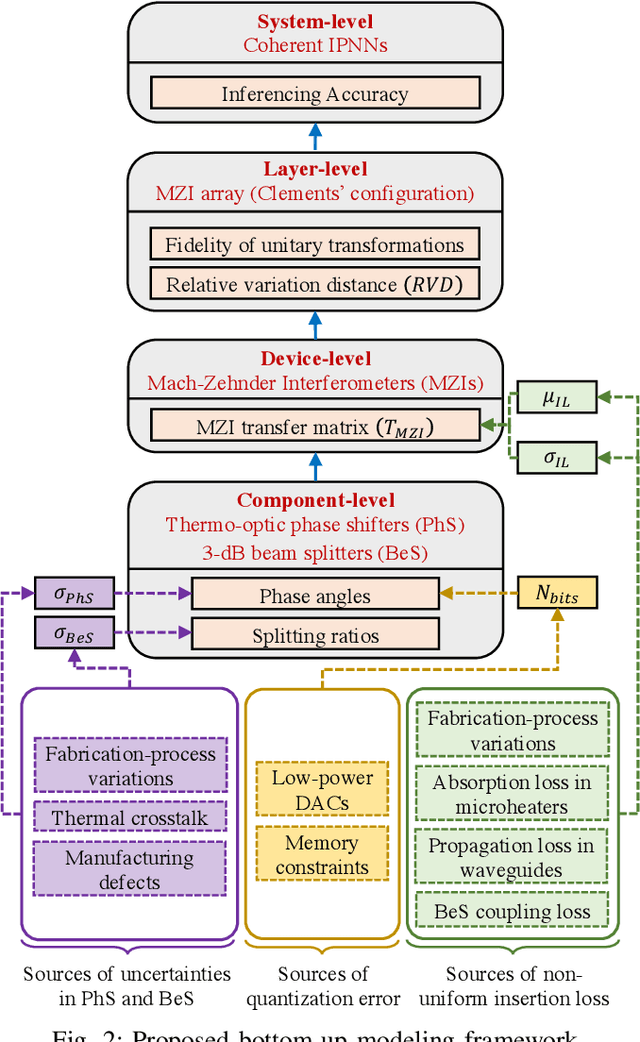
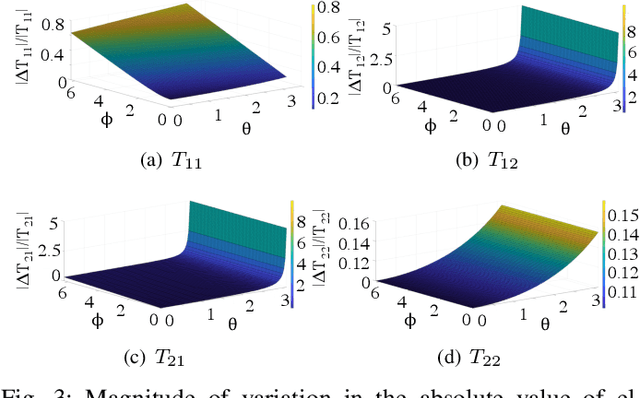
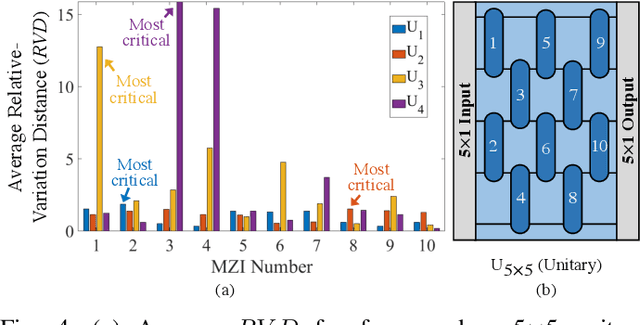
Integrated photonic neural networks (IPNNs) are emerging as promising successors to conventional electronic AI accelerators as they offer substantial improvements in computing speed and energy efficiency. In particular, coherent IPNNs use arrays of Mach-Zehnder interferometers (MZIs) for unitary transformations to perform energy-efficient matrix-vector multiplication. However, the underlying MZI devices in IPNNs are susceptible to uncertainties stemming from optical lithographic variations and thermal crosstalk and can experience imprecisions due to non-uniform MZI insertion loss and quantization errors due to low-precision encoding in the tuned phase angles. In this paper, we, for the first time, systematically characterize the impact of such uncertainties and imprecisions (together referred to as imperfections) in IPNNs using a bottom-up approach. We show that their impact on IPNN accuracy can vary widely based on the tuned parameters (e.g., phase angles) of the affected components, their physical location, and the nature and distribution of the imperfections. To improve reliability measures, we identify critical IPNN building blocks that, under imperfections, can lead to catastrophic degradation in the classification accuracy. We show that under multiple simultaneous imperfections, the IPNN inferencing accuracy can degrade by up to 46%, even when the imperfection parameters are restricted within a small range. Our results also indicate that the inferencing accuracy is sensitive to imperfections affecting the MZIs in the linear layers next to the input layer of the IPNN.
Characterization and Optimization of Integrated Silicon-Photonic Neural Networks under Fabrication-Process Variations
Apr 19, 2022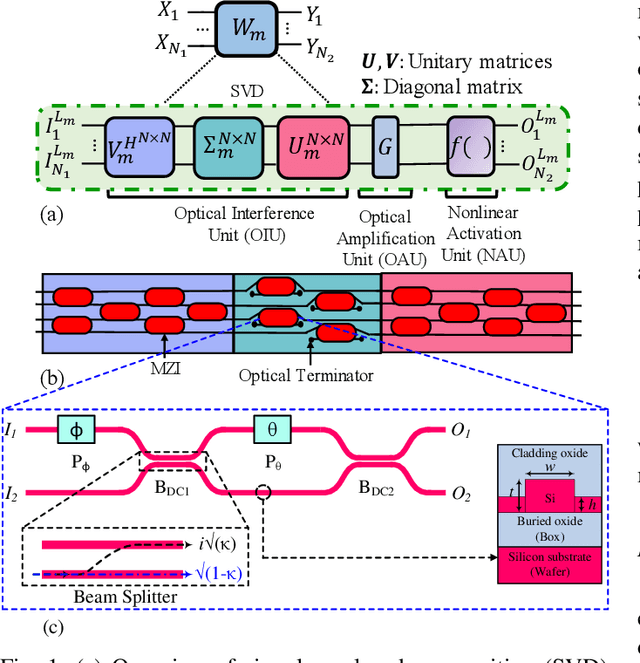

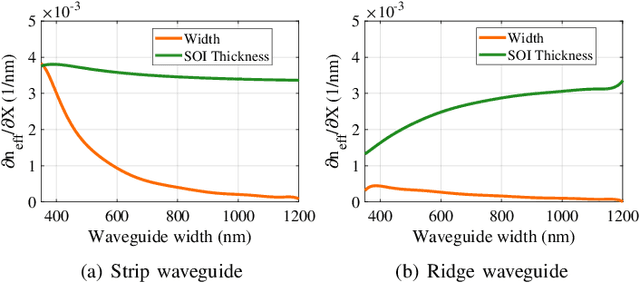

Silicon-photonic neural networks (SPNNs) have emerged as promising successors to electronic artificial intelligence (AI) accelerators by offering orders of magnitude lower latency and higher energy efficiency. Nevertheless, the underlying silicon photonic devices in SPNNs are sensitive to inevitable fabrication-process variations (FPVs) stemming from optical lithography imperfections. Consequently, the inferencing accuracy in an SPNN can be highly impacted by FPVs -- e.g., can drop to below 10% -- the impact of which is yet to be fully studied. In this paper, we, for the first time, model and explore the impact of FPVs in the waveguide width and silicon-on-insulator (SOI) thickness in coherent SPNNs that use Mach-Zehnder Interferometers (MZIs). Leveraging such models, we propose a novel variation-aware, design-time optimization solution to improve MZI tolerance to different FPVs in SPNNs. Simulation results for two example SPNNs of different scales under realistic and correlated FPVs indicate that the optimized MZIs can improve the inferencing accuracy by up to 93.95% for the MNIST handwritten digit dataset -- considered as an example in this paper -- which corresponds to a <0.5% accuracy loss compared to the variation-free case. The proposed one-time optimization method imposes low area overhead, and hence is applicable even to resource-constrained designs
LoCI: An Analysis of the Impact of Optical Loss and Crosstalk Noise in Integrated Silicon-Photonic Neural Networks
Apr 08, 2022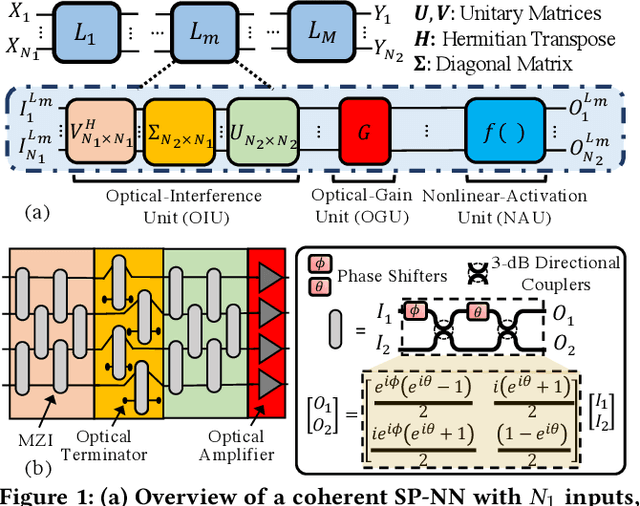
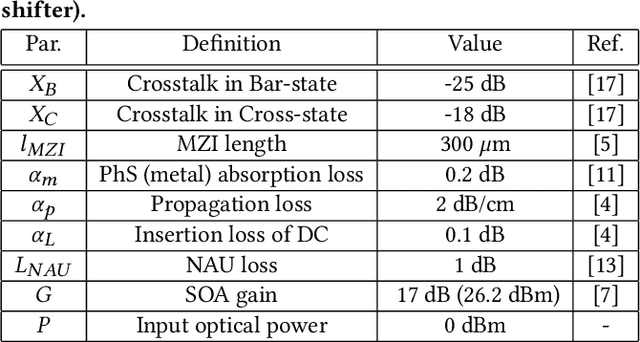
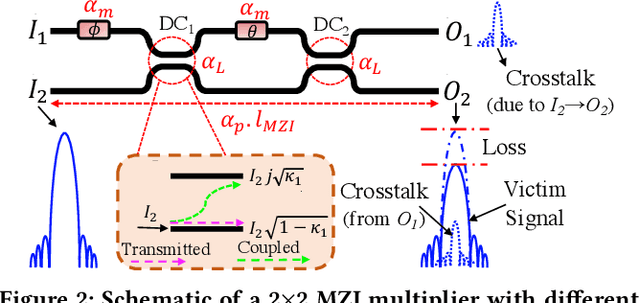
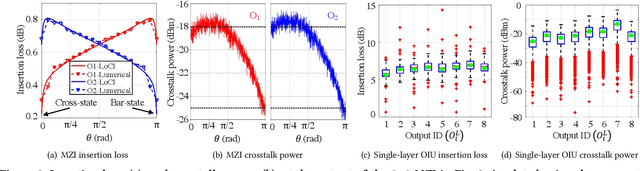
Compared to electronic accelerators, integrated silicon-photonic neural networks (SP-NNs) promise higher speed and energy efficiency for emerging artificial-intelligence applications. However, a hitherto overlooked problem in SP-NNs is that the underlying silicon photonic devices suffer from intrinsic optical loss and crosstalk noise, the impact of which accumulates as the network scales up. Leveraging precise device-level models, this paper presents the first comprehensive and systematic optical loss and crosstalk modeling framework for SP-NNs. For an SP-NN case study with two hidden layers and 1380 tunable parameters, we show a catastrophic 84% drop in inferencing accuracy due to optical loss and crosstalk noise.
Pruning Coherent Integrated Photonic Neural Networks Using the Lottery Ticket Hypothesis
Dec 14, 2021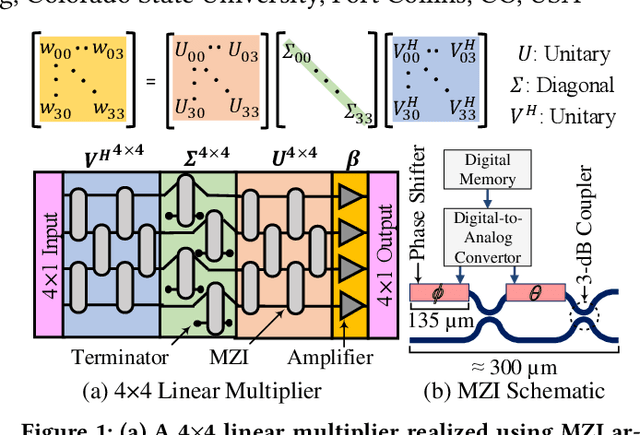
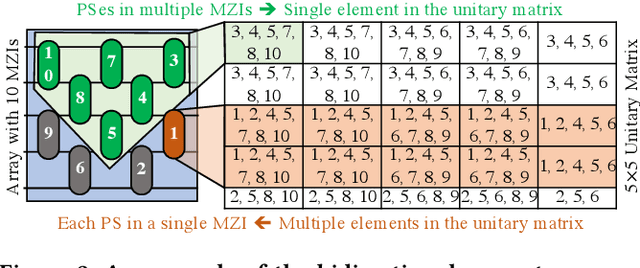
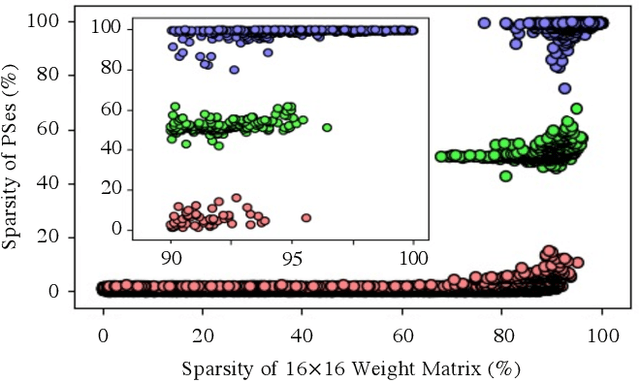
Singular-value-decomposition-based coherent integrated photonic neural networks (SC-IPNNs) have a large footprint, suffer from high static power consumption for training and inference, and cannot be pruned using conventional DNN pruning techniques. We leverage the lottery ticket hypothesis to propose the first hardware-aware pruning method for SC-IPNNs that alleviates these challenges by minimizing the number of weight parameters. We prune a multi-layer perceptron-based SC-IPNN and show that up to 89% of the phase angles, which correspond to weight parameters in SC-IPNNs, can be pruned with a negligible accuracy loss (smaller than 5%) while reducing the static power consumption by up to 86%.
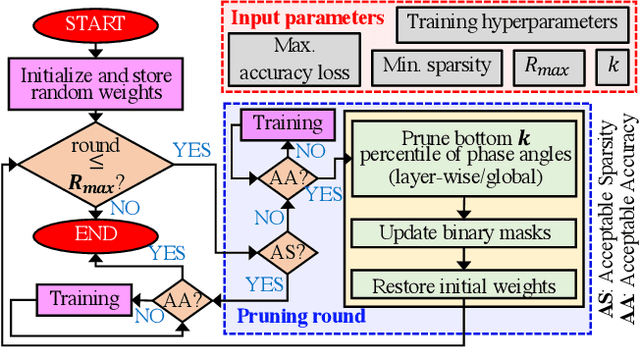
CHAMP: Coherent Hardware-Aware Magnitude Pruning of Integrated Photonic Neural Networks
Dec 11, 2021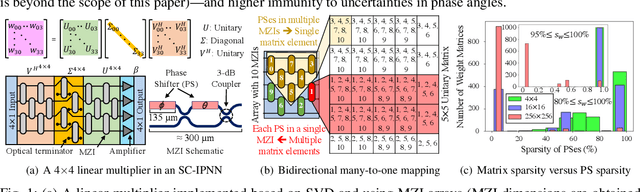
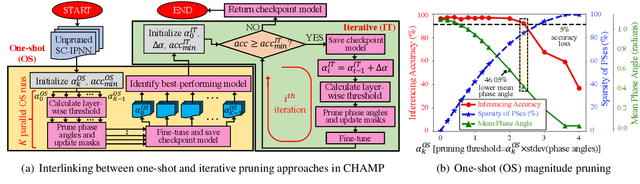
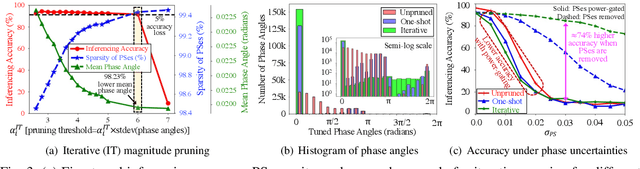
We propose a novel hardware-aware magnitude pruning technique for coherent photonic neural networks. The proposed technique can prune 99.45% of network parameters and reduce the static power consumption by 98.23% with a negligible accuracy loss.
Modeling Silicon-Photonic Neural Networks under Uncertainties
Dec 19, 2020

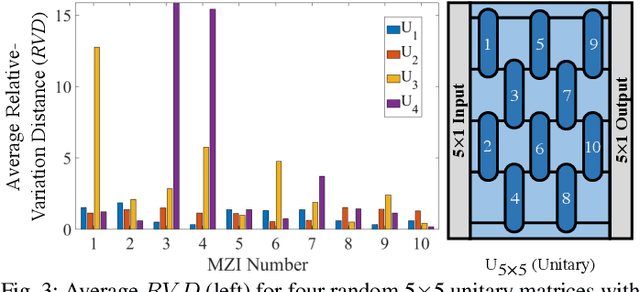
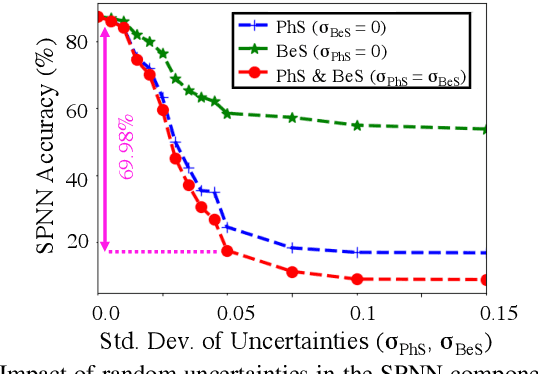
Silicon-photonic neural networks (SPNNs) offer substantial improvements in computing speed and energy efficiency compared to their digital electronic counterparts. However, the energy efficiency and accuracy of SPNNs are highly impacted by uncertainties that arise from fabrication-process and thermal variations. In this paper, we present the first comprehensive and hierarchical study on the impact of random uncertainties on the classification accuracy of a Mach-Zehnder Interferometer (MZI)-based SPNN. We show that such impact can vary based on both the location and characteristics (e.g., tuned phase angles) of a non-ideal silicon-photonic device. Simulation results show that in an SPNN with two hidden layers and 1374 tunable-thermal-phase shifters, random uncertainties even in mature fabrication processes can lead to a catastrophic 70% accuracy loss.