 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOPIMA: Optical Processing-In-Memory for Convolutional Neural Network Acceleration
Jul 11, 2024



Recent advances in machine learning (ML) have spotlighted the pressing need for computing architectures that bridge the gap between memory bandwidth and processing power. The advent of deep neural networks has pushed traditional Von Neumann architectures to their limits due to the high latency and energy consumption costs associated with data movement between the processor and memory for these workloads. One of the solutions to overcome this bottleneck is to perform computation within the main memory through processing-in-memory (PIM), thereby limiting data movement and the costs associated with it. However, DRAM-based PIM struggles to achieve high throughput and energy efficiency due to internal data movement bottlenecks and the need for frequent refresh operations. In this work, we introduce OPIMA, a PIM-based ML accelerator, architected within an optical main memory. OPIMA has been designed to leverage the inherent massive parallelism within main memory while performing high-speed, low-energy optical computation to accelerate ML models based on convolutional neural networks. We present a comprehensive analysis of OPIMA to guide design choices and operational mechanisms. Additionally, we evaluate the performance and energy consumption of OPIMA, comparing it with conventional electronic computing systems and emerging photonic PIM architectures. The experimental results show that OPIMA can achieve 2.98x higher throughput and 137x better energy efficiency than the best-known prior work.
Lightator: An Optical Near-Sensor Accelerator with Compressive Acquisition Enabling Versatile Image Processing
Mar 08, 2024



This paper proposes a high-performance and energy-efficient optical near-sensor accelerator for vision applications, called Lightator. Harnessing the promising efficiency offered by photonic devices, Lightator features innovative compressive acquisition of input frames and fine-grained convolution operations for low-power and versatile image processing at the edge for the first time. This will substantially diminish the energy consumption and latency of conversion, transmission, and processing within the established cloud-centric architecture as well as recently designed edge accelerators. Our device-to-architecture simulation results show that with favorable accuracy, Lightator achieves 84.4 Kilo FPS/W and reduces power consumption by a factor of ~24x and 73x on average compared with existing photonic accelerators and GPU baseline.
Silicon Photonic 2.5D Interposer Networks for Overcoming Communication Bottlenecks in Scale-out Machine Learning Hardware Accelerators
Mar 07, 2024Modern machine learning (ML) applications are becoming increasingly complex and monolithic (single chip) accelerator architectures cannot keep up with their energy efficiency and throughput demands. Even though modern digital electronic accelerators are gradually adopting 2.5D architectures with multiple smaller chiplets to improve scalability, they face fundamental limitations due to a reliance on slow metallic interconnects. This paper outlines how optical communication and computation can be leveraged in 2.5D platforms to realize energy-efficient and high throughput 2.5D ML accelerator architectures.
Accelerating Neural Networks for Large Language Models and Graph Processing with Silicon Photonics
Jan 12, 2024



In the rapidly evolving landscape of artificial intelligence, large language models (LLMs) and graph processing have emerged as transformative technologies for natural language processing (NLP), computer vision, and graph-structured data applications. However, the complex structures of these models pose challenges for acceleration on conventional electronic platforms. In this paper, we describe novel hardware accelerators based on silicon photonics to accelerate transformer neural networks that are used in LLMs and graph neural networks for graph data processing. Our analysis demonstrates that both hardware accelerators achieve at least 10.2x throughput improvement and 3.8x better energy efficiency over multiple state-of-the-art electronic hardware accelerators designed for LLMs and graph processing.
OISA: Architecting an Optical In-Sensor Accelerator for Efficient Visual Computing
Nov 30, 2023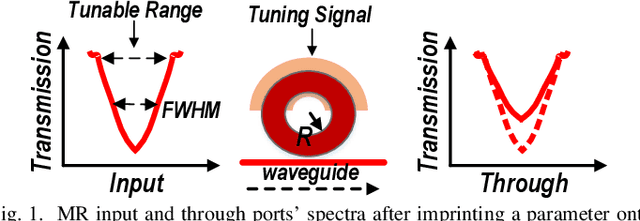
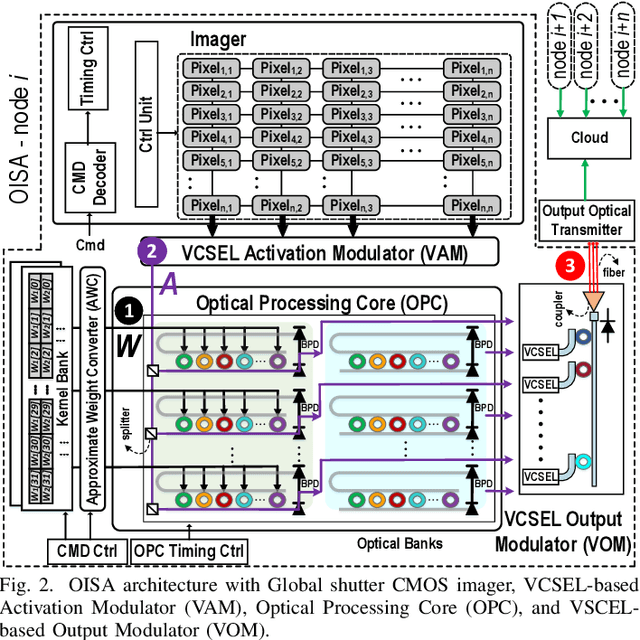
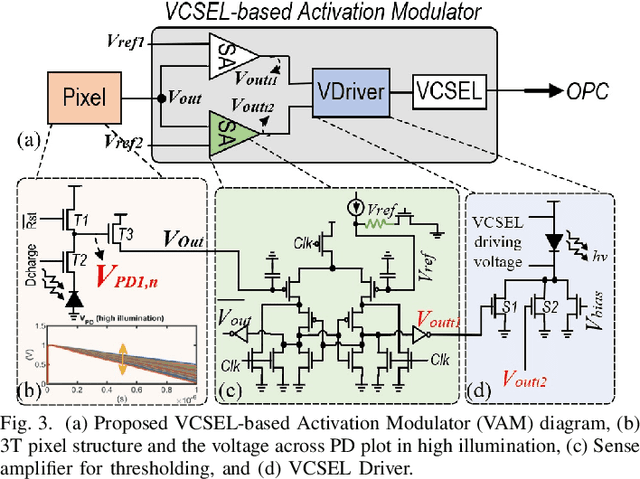
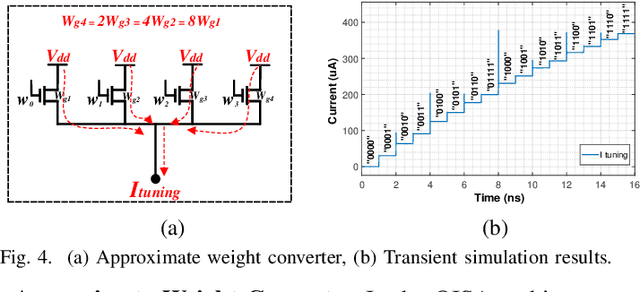
Targeting vision applications at the edge, in this work, we systematically explore and propose a high-performance and energy-efficient Optical In-Sensor Accelerator architecture called OISA for the first time. Taking advantage of the promising efficiency of photonic devices, the OISA intrinsically implements a coarse-grained convolution operation on the input frames in an innovative minimum-conversion fashion in low-bit-width neural networks. Such a design remarkably reduces the power consumption of data conversion, transmission, and processing in the conventional cloud-centric architecture as well as recently-presented edge accelerators. Our device-to-architecture simulation results on various image data-sets demonstrate acceptable accuracy while OISA achieves 6.68 TOp/s/W efficiency. OISA reduces power consumption by a factor of 7.9 and 18.4 on average compared with existing electronic in-/near-sensor and ASIC accelerators.
Analysis of Optical Loss and Crosstalk Noise in MZI-based Coherent Photonic Neural Networks
Aug 07, 2023



With the continuous increase in the size and complexity of machine learning models, the need for specialized hardware to efficiently run such models is rapidly growing. To address such a need, silicon-photonic-based neural network (SP-NN) accelerators have recently emerged as a promising alternative to electronic accelerators due to their lower latency and higher energy efficiency. Not only can SP-NNs alleviate the fan-in and fan-out problem with linear algebra processors, their operational bandwidth can match that of the photodetection rate (typically 100 GHz), which is at least over an order of magnitude faster than electronic counterparts that are restricted to a clock rate of a few GHz. Unfortunately, the underlying silicon photonic devices in SP-NNs suffer from inherent optical losses and crosstalk noise originating from fabrication imperfections and undesired optical couplings, the impact of which accumulates as the network scales up. Consequently, the inferencing accuracy in an SP-NN can be affected by such inefficiencies -- e.g., can drop to below 10% -- the impact of which is yet to be fully studied. In this paper, we comprehensively model the optical loss and crosstalk noise using a bottom-up approach, from the device to the system level, in coherent SP-NNs built using Mach-Zehnder interferometer (MZI) devices. The proposed models can be applied to any SP-NN architecture with different configurations to analyze the effect of loss and crosstalk. Such an analysis is important where there are inferencing accuracy and scalability requirements to meet when designing an SP-NN. Using the proposed analytical framework, we show a high power penalty and a catastrophic inferencing accuracy drop of up to 84% for SP-NNs of different scales with three known MZI mesh configurations (i.e., Reck, Clements, and Diamond) due to accumulated optical loss and crosstalk noise.
GHOST: A Graph Neural Network Accelerator using Silicon Photonics
Jul 04, 2023



Graph neural networks (GNNs) have emerged as a powerful approach for modelling and learning from graph-structured data. Multiple fields have since benefitted enormously from the capabilities of GNNs, such as recommendation systems, social network analysis, drug discovery, and robotics. However, accelerating and efficiently processing GNNs require a unique approach that goes beyond conventional artificial neural network accelerators, due to the substantial computational and memory requirements of GNNs. The slowdown of scaling in CMOS platforms also motivates a search for alternative implementation substrates. In this paper, we present GHOST, the first silicon-photonic hardware accelerator for GNNs. GHOST efficiently alleviates the costs associated with both vertex-centric and edge-centric operations. It implements separately the three main stages involved in running GNNs in the optical domain, allowing it to be used for the inference of various widely used GNN models and architectures, such as graph convolution networks and graph attention networks. Our simulation studies indicate that GHOST exhibits at least 10.2x better throughput and 3.8x better energy efficiency when compared to GPU, TPU, CPU and multiple state-of-the-art GNN hardware accelerators.
Cross-Layer Design for AI Acceleration with Non-Coherent Optical Computing
Mar 22, 2023



Emerging AI applications such as ChatGPT, graph convolutional networks, and other deep neural networks require massive computational resources for training and inference. Contemporary computing platforms such as CPUs, GPUs, and TPUs are struggling to keep up with the demands of these AI applications. Non-coherent optical computing represents a promising approach for light-speed acceleration of AI workloads. In this paper, we show how cross-layer design can overcome challenges in non-coherent optical computing platforms. We describe approaches for optical device engineering, tuning circuit enhancements, and architectural innovations to adapt optical computing to a variety of AI workloads. We also discuss techniques for hardware/software co-design that can intelligently map and adapt AI software to improve its performance on non-coherent optical computing platforms.
TRON: Transformer Neural Network Acceleration with Non-Coherent Silicon Photonics
Mar 22, 2023Transformer neural networks are rapidly being integrated into state-of-the-art solutions for natural language processing (NLP) and computer vision. However, the complex structure of these models creates challenges for accelerating their execution on conventional electronic platforms. We propose the first silicon photonic hardware neural network accelerator called TRON for transformer-based models such as BERT, and Vision Transformers. Our analysis demonstrates that TRON exhibits at least 14x better throughput and 8x better energy efficiency, in comparison to state-of-the-art transformer accelerators.
Machine Learning Accelerators in 2.5D Chiplet Platforms with Silicon Photonics
Jan 28, 2023Domain-specific machine learning (ML) accelerators such as Google's TPU and Apple's Neural Engine now dominate CPUs and GPUs for energy-efficient ML processing. However, the evolution of electronic accelerators is facing fundamental limits due to the limited computation density of monolithic processing chips and the reliance on slow metallic interconnects. In this paper, we present a vision of how optical computation and communication can be integrated into 2.5D chiplet platforms to drive an entirely new class of sustainable and scalable ML hardware accelerators. We describe how cross-layer design and fabrication of optical devices, circuits, and architectures, and hardware/software codesign can help design efficient photonics-based 2.5D chiplet platforms to accelerate emerging ML workloads.