 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuroShield: A Neuro-Symbolic Framework for Adversarial Robustness
Jan 19, 2026Adversarial vulnerability and lack of interpretability are critical limitations of deep neural networks, especially in safety-sensitive settings such as autonomous driving. We introduce \DesignII, a neuro-symbolic framework that integrates symbolic rule supervision into neural networks to enhance both adversarial robustness and explainability. Domain knowledge is encoded as logical constraints over appearance attributes such as shape and color, and enforced through semantic and symbolic logic losses applied during training. Using the GTSRB dataset, we evaluate robustness against FGSM and PGD attacks at a standard $\ell_\infty$ perturbation budget of $\varepsilon = 8/255$. Relative to clean training, standard adversarial training provides modest improvements in robustness ($\sim$10 percentage points). Conversely, our FGSM-Neuro-Symbolic and PGD-Neuro-Symbolic models achieve substantially larger gains, improving adversarial accuracy by 18.1\% and 17.35\% over their corresponding adversarial-training baselines, representing roughly a three-fold larger robustness gain than standard adversarial training provides when both are measured relative to the same clean-training baseline, without reducing clean-sample accuracy. Compared to transformer-based defenses such as LNL-MoEx, which require heavy architectures and extensive data augmentation, our PGD-Neuro-Symbolic variant attains comparable or superior robustness using a ResNet18 backbone trained for 10 epochs. These results show that symbolic reasoning offers an effective path to robust and interpretable AI.
HiRISE: High-Resolution Image Scaling for Edge ML via In-Sensor Compression and Selective ROI
Jul 23, 2024



With the rise of tiny IoT devices powered by machine learning (ML), many researchers have directed their focus toward compressing models to fit on tiny edge devices. Recent works have achieved remarkable success in compressing ML models for object detection and image classification on microcontrollers with small memory, e.g., 512kB SRAM. However, there remain many challenges prohibiting the deployment of ML systems that require high-resolution images. Due to fundamental limits in memory capacity for tiny IoT devices, it may be physically impossible to store large images without external hardware. To this end, we propose a high-resolution image scaling system for edge ML, called HiRISE, which is equipped with selective region-of-interest (ROI) capability leveraging analog in-sensor image scaling. Our methodology not only significantly reduces the peak memory requirements, but also achieves up to 17.7x reduction in data transfer and energy consumption.
Lightator: An Optical Near-Sensor Accelerator with Compressive Acquisition Enabling Versatile Image Processing
Mar 08, 2024



This paper proposes a high-performance and energy-efficient optical near-sensor accelerator for vision applications, called Lightator. Harnessing the promising efficiency offered by photonic devices, Lightator features innovative compressive acquisition of input frames and fine-grained convolution operations for low-power and versatile image processing at the edge for the first time. This will substantially diminish the energy consumption and latency of conversion, transmission, and processing within the established cloud-centric architecture as well as recently designed edge accelerators. Our device-to-architecture simulation results show that with favorable accuracy, Lightator achieves 84.4 Kilo FPS/W and reduces power consumption by a factor of ~24x and 73x on average compared with existing photonic accelerators and GPU baseline.
OISA: Architecting an Optical In-Sensor Accelerator for Efficient Visual Computing
Nov 30, 2023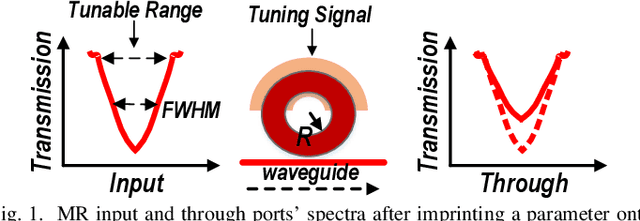
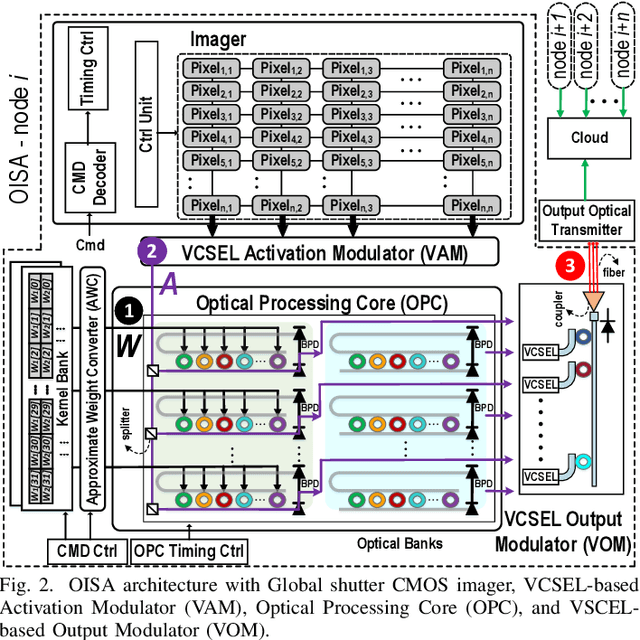
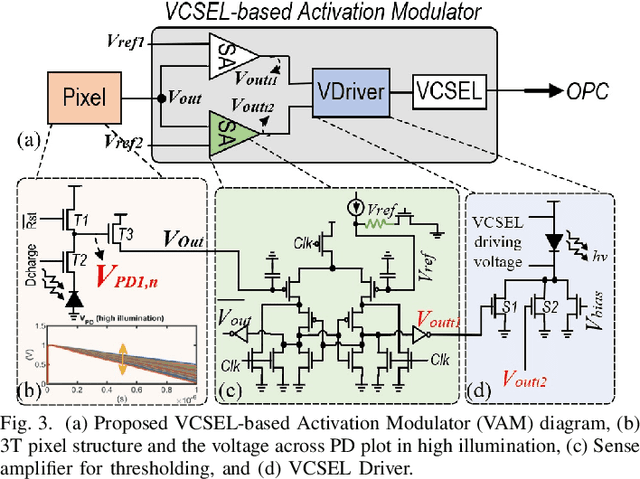
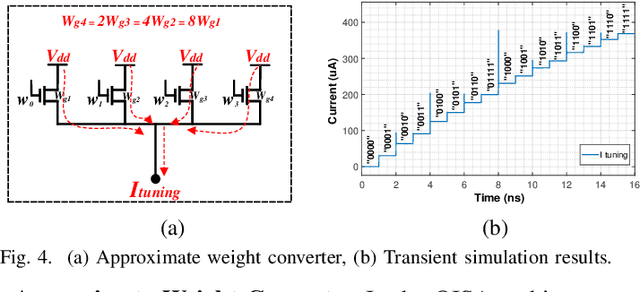
Targeting vision applications at the edge, in this work, we systematically explore and propose a high-performance and energy-efficient Optical In-Sensor Accelerator architecture called OISA for the first time. Taking advantage of the promising efficiency of photonic devices, the OISA intrinsically implements a coarse-grained convolution operation on the input frames in an innovative minimum-conversion fashion in low-bit-width neural networks. Such a design remarkably reduces the power consumption of data conversion, transmission, and processing in the conventional cloud-centric architecture as well as recently-presented edge accelerators. Our device-to-architecture simulation results on various image data-sets demonstrate acceptable accuracy while OISA achieves 6.68 TOp/s/W efficiency. OISA reduces power consumption by a factor of 7.9 and 18.4 on average compared with existing electronic in-/near-sensor and ASIC accelerators.
NeSe: Near-Sensor Event-Driven Scheme for Low Power Energy Harvesting Sensors
Feb 07, 2023



Digital technologies have made it possible to deploy visual sensor nodes capable of detecting motion events in the coverage area cost-effectively. However, background subtraction, as a widely used approach, remains an intractable task due to its inability to achieve competitive accuracy and reduced computation cost simultaneously. In this paper, an effective background subtraction approach, namely NeSe, for tiny energy-harvested sensors is proposed leveraging non-volatile memory (NVM). Using the developed software/hardware method, the accuracy and efficiency of event detection can be adjusted at runtime by changing the precision depending on the application's needs. Due to the near-sensor implementation of background subtraction and NVM usage, the proposed design reduces the data movement overhead while ensuring intermittent resiliency. The background is stored for a specific time interval within NVMs and compared with the next frame. If the power is cut, the background remains unchanged and is updated after the interval passes. Once the moving object is detected, the device switches to the high-powered sensor mode to capture the image.
Entropy-Based Modeling for Estimating Soft Errors Impact on Binarized Neural Network Inference
Apr 21, 2020
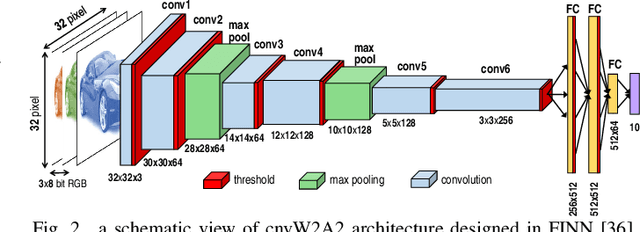
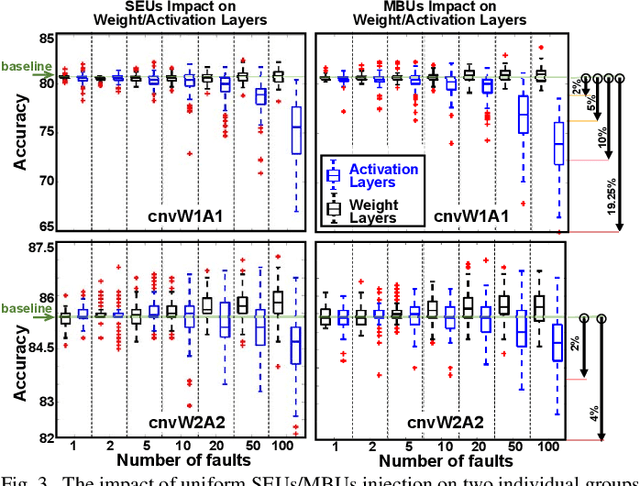
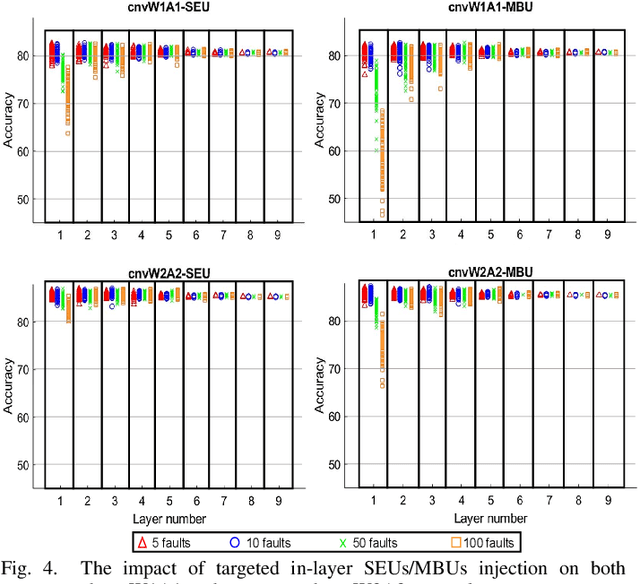
Over past years, the easy accessibility to the large scale datasets has significantly shifted the paradigm for developing highly accurate prediction models that are driven from Neural Network (NN). These models can be potentially impacted by the radiation-induced transient faults that might lead to the gradual downgrade of the long-running expected NN inference accelerator. The crucial observation from our rigorous vulnerability assessment on the NN inference accelerator demonstrates that the weights and activation functions are unevenly susceptible to both single-event upset (SEU) and multi-bit upset (MBU), especially in the first five layers of our selected convolution neural network. In this paper, we present the relatively-accurate statistical models to delineate the impact of both undertaken SEU and MBU across layers and per each layer of the selected NN. These models can be used for evaluating the error-resiliency magnitude of NN topology before adopting them in the safety-critical applications.
Processing-In-Memory Acceleration of Convolutional Neural Networks for Energy-Efficiency, and Power-Intermittency Resilience
Apr 16, 2019
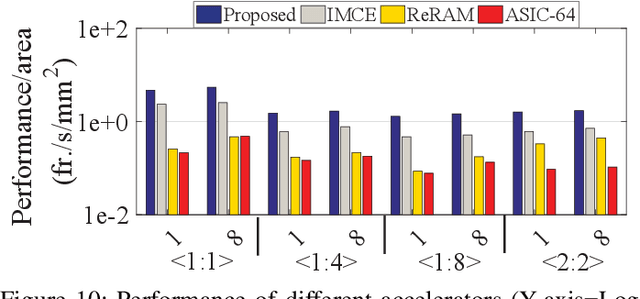
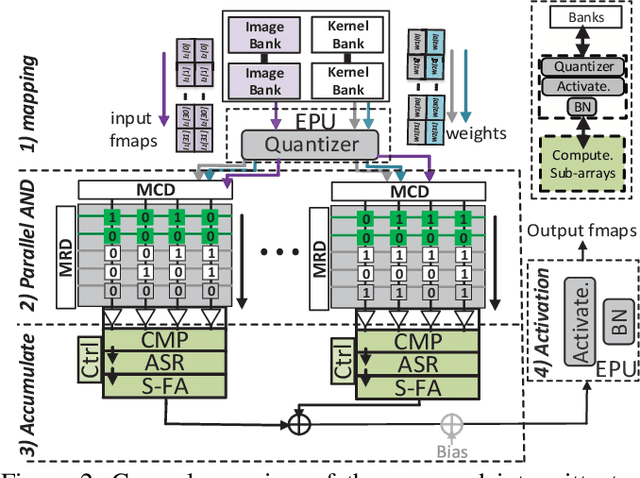
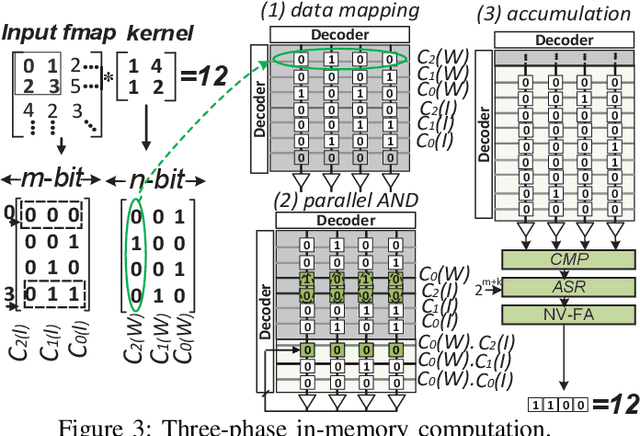
Herein, a bit-wise Convolutional Neural Network (CNN) in-memory accelerator is implemented using Spin-Orbit Torque Magnetic Random Access Memory (SOT-MRAM) computational sub-arrays. It utilizes a novel AND-Accumulation method capable of significantly-reduced energy consumption within convolutional layers and performs various low bit-width CNN inference operations entirely within MRAM. Power-intermittence resiliency is also enhanced by retaining the partial state information needed to maintain computational forward-progress, which is advantageous for battery-less IoT nodes. Simulation results indicate $\sim$5.4$\times$ higher energy-efficiency and 9$\times$ speedup over ReRAM-based acceleration, or roughly $\sim$9.7$\times$ higher energy-efficiency and 13.5$\times$ speedup over recent CMOS-only approaches, while maintaining inference accuracy comparable to baseline designs.