 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiRISE: High-Resolution Image Scaling for Edge ML via In-Sensor Compression and Selective ROI
Jul 23, 2024



With the rise of tiny IoT devices powered by machine learning (ML), many researchers have directed their focus toward compressing models to fit on tiny edge devices. Recent works have achieved remarkable success in compressing ML models for object detection and image classification on microcontrollers with small memory, e.g., 512kB SRAM. However, there remain many challenges prohibiting the deployment of ML systems that require high-resolution images. Due to fundamental limits in memory capacity for tiny IoT devices, it may be physically impossible to store large images without external hardware. To this end, we propose a high-resolution image scaling system for edge ML, called HiRISE, which is equipped with selective region-of-interest (ROI) capability leveraging analog in-sensor image scaling. Our methodology not only significantly reduces the peak memory requirements, but also achieves up to 17.7x reduction in data transfer and energy consumption.
Lightator: An Optical Near-Sensor Accelerator with Compressive Acquisition Enabling Versatile Image Processing
Mar 08, 2024



This paper proposes a high-performance and energy-efficient optical near-sensor accelerator for vision applications, called Lightator. Harnessing the promising efficiency offered by photonic devices, Lightator features innovative compressive acquisition of input frames and fine-grained convolution operations for low-power and versatile image processing at the edge for the first time. This will substantially diminish the energy consumption and latency of conversion, transmission, and processing within the established cloud-centric architecture as well as recently designed edge accelerators. Our device-to-architecture simulation results show that with favorable accuracy, Lightator achieves 84.4 Kilo FPS/W and reduces power consumption by a factor of ~24x and 73x on average compared with existing photonic accelerators and GPU baseline.
Heterogeneous Integration of In-Memory Analog Computing Architectures with Tensor Processing Units
Apr 18, 2023



Tensor processing units (TPUs), specialized hardware accelerators for machine learning tasks, have shown significant performance improvements when executing convolutional layers in convolutional neural networks (CNNs). However, they struggle to maintain the same efficiency in fully connected (FC) layers, leading to suboptimal hardware utilization. In-memory analog computing (IMAC) architectures, on the other hand, have demonstrated notable speedup in executing FC layers. This paper introduces a novel, heterogeneous, mixed-signal, and mixed-precision architecture that integrates an IMAC unit with an edge TPU to enhance mobile CNN performance. To leverage the strengths of TPUs for convolutional layers and IMAC circuits for dense layers, we propose a unified learning algorithm that incorporates mixed-precision training techniques to mitigate potential accuracy drops when deploying models on the TPU-IMAC architecture. The simulations demonstrate that the TPU-IMAC configuration achieves up to $2.59\times$ performance improvements, and $88\%$ memory reductions compared to conventional TPU architectures for various CNN models while maintaining comparable accuracy. The TPU-IMAC architecture shows potential for various applications where energy efficiency and high performance are essential, such as edge computing and real-time processing in mobile devices. The unified training algorithm and the integration of IMAC and TPU architectures contribute to the potential impact of this research on the broader machine learning landscape.
An In-Memory Analog Computing Co-Processor for Energy-Efficient CNN Inference on Mobile Devices
May 24, 2021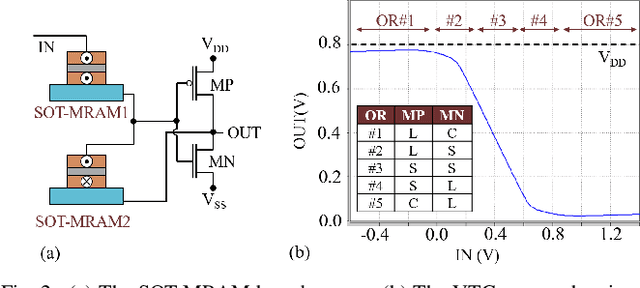
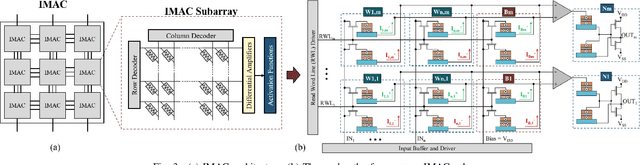
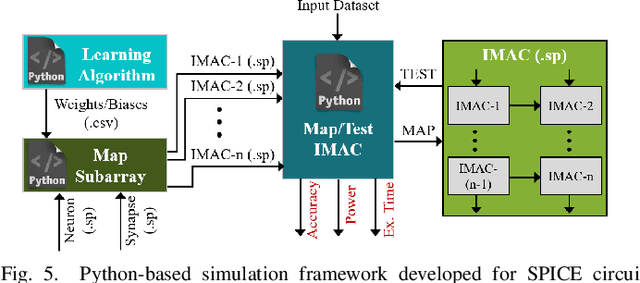
In this paper, we develop an in-memory analog computing (IMAC) architecture realizing both synaptic behavior and activation functions within non-volatile memory arrays. Spin-orbit torque magnetoresistive random-access memory (SOT-MRAM) devices are leveraged to realize sigmoidal neurons as well as binarized synapses. First, it is shown the proposed IMAC architecture can be utilized to realize a multilayer perceptron (MLP) classifier achieving orders of magnitude performance improvement compared to previous mixed-signal and digital implementations. Next, a heterogeneous mixed-signal and mixed-precision CPU-IMAC architecture is proposed for convolutional neural networks (CNNs) inference on mobile processors, in which IMAC is designed as a co-processor to realize fully-connected (FC) layers whereas convolution layers are executed in CPU. Architecture-level analytical models are developed to evaluate the performance and energy consumption of the CPU-IMAC architecture. Simulation results exhibit 6.5% and 10% energy savings for CPU-IMAC based realizations of LeNet and VGG CNN models, for MNIST and CIFAR-10 pattern recognition tasks, respectively.
TSV Extrusion Morphology Classification Using Deep Convolutional Neural Networks
Sep 22, 2020



In this paper, we utilize deep convolutional neural networks (CNNs) to classify the morphology of through-silicon via (TSV) extrusion in three dimensional (3D) integrated circuits (ICs). TSV extrusion is a crucial reliability concern which can deform and crack interconnect layers in 3D ICs and cause device failures. Herein, the white light interferometry (WLI) technique is used to obtain the surface profile of the extruded TSVs. We have developed a program that uses raw data obtained from WLI to create a TSV extrusion morphology dataset, including TSV images with 54x54 pixels that are labeled and categorized into three morphology classes. Four CNN architectures with different network complexities are implemented and trained for TSV extrusion morphology classification application. Data augmentation and dropout approaches are utilized to realize a balance between overfitting and underfitting in the CNN models. Results obtained show that the CNN model with optimized complexity, dropout, and data augmentation can achieve a classification accuracy comparable to that of a human expert.
SOT-MRAM based Sigmoidal Neuron for Neuromorphic Architectures
Jun 01, 2020


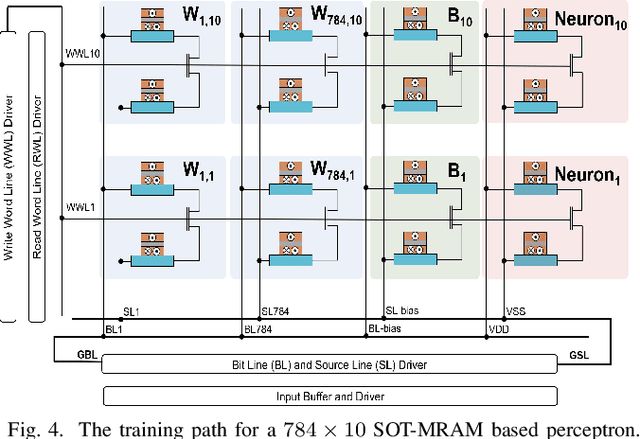
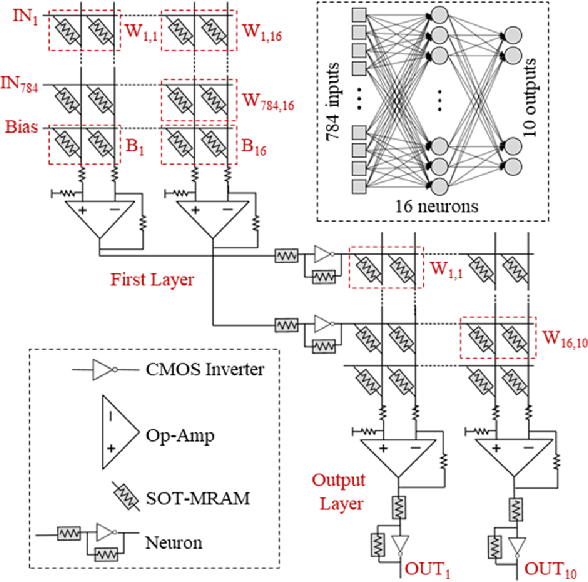
In this paper, the intrinsic physical characteristics of spin-orbit torque (SOT) magnetoresistive random-access memory (MRAM) devices are leveraged to realize sigmoidal neurons in neuromorphic architectures. Performance comparisons with the previous power- and area-efficient sigmoidal neuron circuits exhibit 74x and 12x reduction in power-area-product values for the proposed SOT-MRAM based neuron. To verify the functionally of the proposed neuron within larger scale designs, we have implemented a circuit realization of a 784x16x10 SOT-MRAM based multiplayer perceptron (MLP) for MNIST pattern recognition application using SPICE circuit simulation tool. The results obtained exhibit that the proposed SOT-MRAM based MLP can achieve accuracies comparable to an ideal binarized MLP architecture implemented on GPU, while realizing orders of magnitude increase in processing speed.