 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlex-TPU: A Flexible TPU with Runtime Reconfigurable Dataflow Architecture
Jul 11, 2024



Tensor processing units (TPUs) are one of the most well-known machine learning (ML) accelerators utilized at large scale in data centers as well as in tiny ML applications. TPUs offer several improvements and advantages over conventional ML accelerators, like graphical processing units (GPUs), being designed specifically to perform the multiply-accumulate (MAC) operations required in the matrix-matrix and matrix-vector multiplies extensively present throughout the execution of deep neural networks (DNNs). Such improvements include maximizing data reuse and minimizing data transfer by leveraging the temporal dataflow paradigms provided by the systolic array architecture. While this design provides a significant performance benefit, the current implementations are restricted to a single dataflow consisting of either input, output, or weight stationary architectures. This can limit the achievable performance of DNN inference and reduce the utilization of compute units. Therefore, the work herein consists of developing a reconfigurable dataflow TPU, called the Flex-TPU, which can dynamically change the dataflow per layer during run-time. Our experiments thoroughly test the viability of the Flex-TPU comparing it to conventional TPU designs across multiple well-known ML workloads. The results show that our Flex-TPU design achieves a significant performance increase of up to 2.75x compared to conventional TPU, with only minor area and power overheads.
MRAM-based Analog Sigmoid Function for In-memory Computing
Apr 21, 2022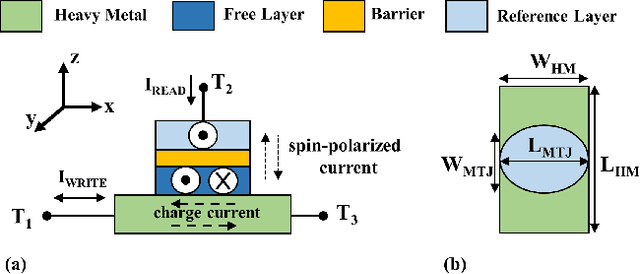
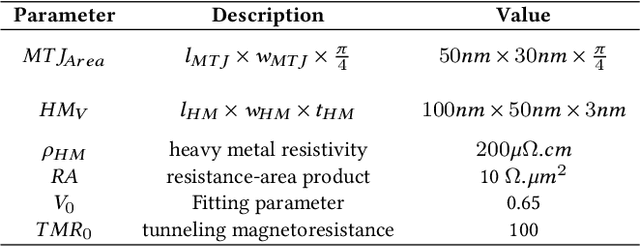
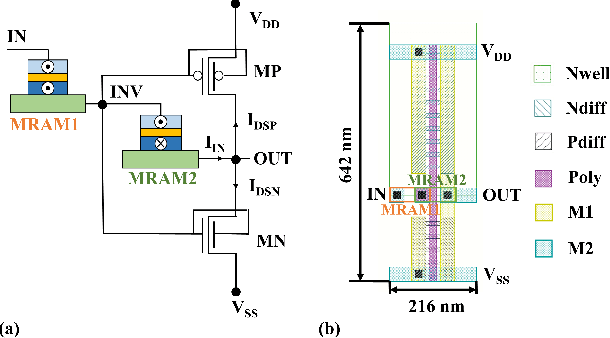

We propose an analog implementation of the transcendental activation function leveraging two spin-orbit torque magnetoresistive random-access memory (SOT-MRAM) devices and a CMOS inverter. The proposed analog neuron circuit consumes 1.8-27x less power, and occupies 2.5-4931x smaller area, compared to the state-of-the-art analog and digital implementations. Moreover, the developed neuron can be readily integrated with memristive crossbars without requiring any intermediate signal conversion units. The architecture-level analyses show that a fully-analog in-memory computing (IMC) circuit that use our SOT-MRAM neuron along with an SOT-MRAM based crossbar can achieve more than 1.1x, 12x, and 13.3x reduction in power, latency, and energy, respectively, compared to a mixed-signal implementation with analog memristive crossbars and digital neurons. Finally, through cross-layer analyses, we provide a guide on how varying the device-level parameters in our neuron can affect the accuracy of multilayer perceptron (MLP) for MNIST classification.
Interconnect Parasitics and Partitioning in Fully-Analog In-Memory Computing Architectures
Jan 29, 2022Fully-analog in-memory computing (IMC) architectures that implement both matrix-vector multiplication and non-linear vector operations within the same memory array have shown promising performance benefits over conventional IMC systems due to the removal of energy-hungry signal conversion units. However, maintaining the computation in the analog domain for the entire deep neural network (DNN) comes with potential sensitivity to interconnect parasitics. Thus, in this paper, we investigate the effect of wire parasitic resistance and capacitance on the accuracy of DNN models deployed on fully-analog IMC architectures. Moreover, we propose a partitioning mechanism to alleviate the impact of the parasitic while keeping the computation in the analog domain through dividing large arrays into multiple partitions. The SPICE circuit simulation results for a 400 X 120 X 84 X 10 DNN model deployed on a fully-analog IMC circuit show that a 94.84% accuracy could be achieved for MNIST classification application with 16, 8, and 8 horizontal partitions, as well as 8, 8, and 1 vertical partitions for first, second, and third layers of the DNN, respectively, which is comparable to the ~97% accuracy realized by digital implementation on CPU. It is shown that accuracy benefits are achieved at the cost of higher power consumption due to the extra circuitry required for handling partitioning.
An In-Memory Analog Computing Co-Processor for Energy-Efficient CNN Inference on Mobile Devices
May 24, 2021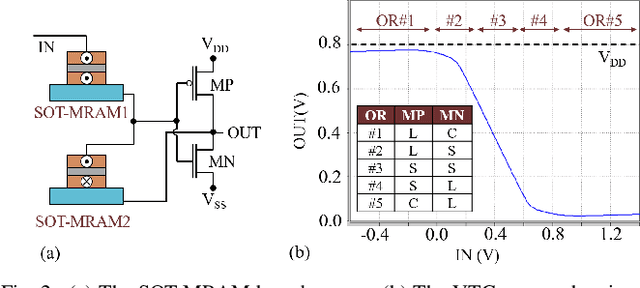
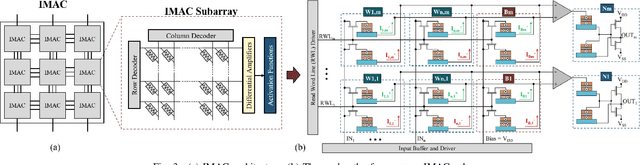
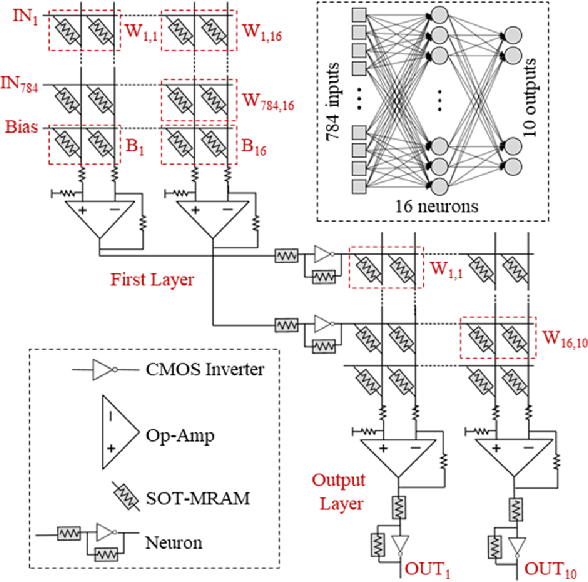
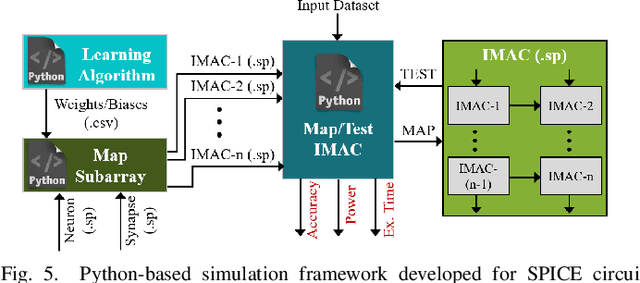
In this paper, we develop an in-memory analog computing (IMAC) architecture realizing both synaptic behavior and activation functions within non-volatile memory arrays. Spin-orbit torque magnetoresistive random-access memory (SOT-MRAM) devices are leveraged to realize sigmoidal neurons as well as binarized synapses. First, it is shown the proposed IMAC architecture can be utilized to realize a multilayer perceptron (MLP) classifier achieving orders of magnitude performance improvement compared to previous mixed-signal and digital implementations. Next, a heterogeneous mixed-signal and mixed-precision CPU-IMAC architecture is proposed for convolutional neural networks (CNNs) inference on mobile processors, in which IMAC is designed as a co-processor to realize fully-connected (FC) layers whereas convolution layers are executed in CPU. Architecture-level analytical models are developed to evaluate the performance and energy consumption of the CPU-IMAC architecture. Simulation results exhibit 6.5% and 10% energy savings for CPU-IMAC based realizations of LeNet and VGG CNN models, for MNIST and CIFAR-10 pattern recognition tasks, respectively.