 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePIM-LLM: A High-Throughput Hybrid PIM Architecture for 1-bit LLMs
Mar 31, 2025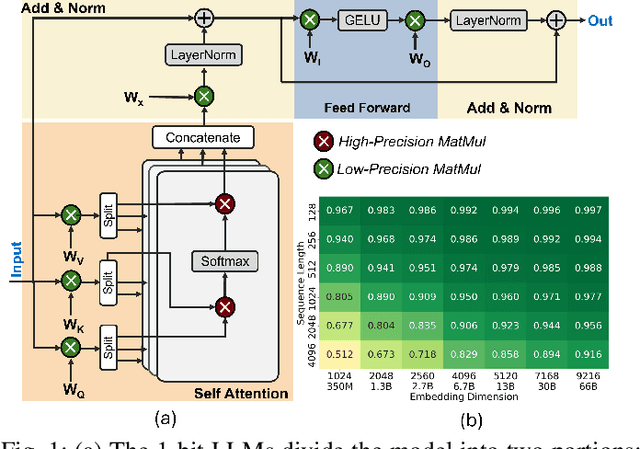
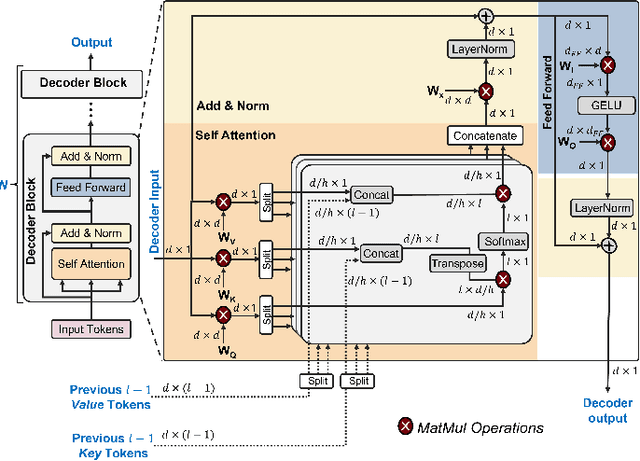
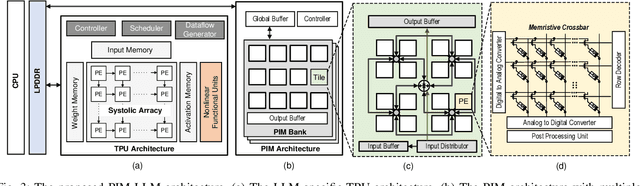
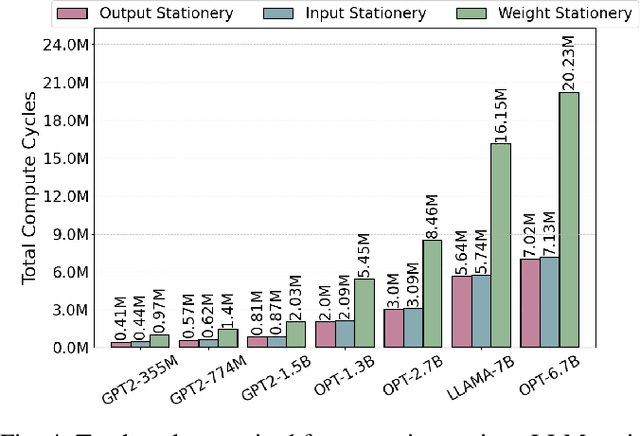
In this paper, we propose PIM-LLM, a hybrid architecture developed to accelerate 1-bit large language models (LLMs). PIM-LLM leverages analog processing-in-memory (PIM) architectures and digital systolic arrays to accelerate low-precision matrix multiplication (MatMul) operations in projection layers and high-precision MatMul operations in attention heads of 1-bit LLMs, respectively. Our design achieves up to roughly 80x improvement in tokens per second and a 70% increase in tokens per joule compared to conventional hardware accelerators. Additionally, PIM-LLM outperforms previous PIM-based LLM accelerators, setting a new benchmark with at least 2x and 5x improvement in GOPS and GOPS/W, respectively.
Towards Efficient Deployment of Hybrid SNNs on Neuromorphic and Edge AI Hardware
Jul 11, 2024
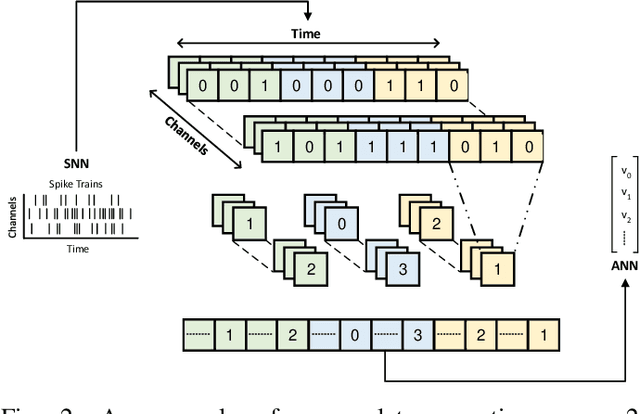


This paper explores the synergistic potential of neuromorphic and edge computing to create a versatile machine learning (ML) system tailored for processing data captured by dynamic vision sensors. We construct and train hybrid models, blending spiking neural networks (SNNs) and artificial neural networks (ANNs) using PyTorch and Lava frameworks. Our hybrid architecture integrates an SNN for temporal feature extraction and an ANN for classification. We delve into the challenges of deploying such hybrid structures on hardware. Specifically, we deploy individual components on Intel's Neuromorphic Processor Loihi (for SNN) and Jetson Nano (for ANN). We also propose an accumulator circuit to transfer data from the spiking to the non-spiking domain. Furthermore, we conduct comprehensive performance analyses of hybrid SNN-ANN models on a heterogeneous system of neuromorphic and edge AI hardware, evaluating accuracy, latency, power, and energy consumption. Our findings demonstrate that the hybrid spiking networks surpass the baseline ANN model across all metrics and outperform the baseline SNN model in accuracy and latency.
Flex-TPU: A Flexible TPU with Runtime Reconfigurable Dataflow Architecture
Jul 11, 2024



Tensor processing units (TPUs) are one of the most well-known machine learning (ML) accelerators utilized at large scale in data centers as well as in tiny ML applications. TPUs offer several improvements and advantages over conventional ML accelerators, like graphical processing units (GPUs), being designed specifically to perform the multiply-accumulate (MAC) operations required in the matrix-matrix and matrix-vector multiplies extensively present throughout the execution of deep neural networks (DNNs). Such improvements include maximizing data reuse and minimizing data transfer by leveraging the temporal dataflow paradigms provided by the systolic array architecture. While this design provides a significant performance benefit, the current implementations are restricted to a single dataflow consisting of either input, output, or weight stationary architectures. This can limit the achievable performance of DNN inference and reduce the utilization of compute units. Therefore, the work herein consists of developing a reconfigurable dataflow TPU, called the Flex-TPU, which can dynamically change the dataflow per layer during run-time. Our experiments thoroughly test the viability of the Flex-TPU comparing it to conventional TPU designs across multiple well-known ML workloads. The results show that our Flex-TPU design achieves a significant performance increase of up to 2.75x compared to conventional TPU, with only minor area and power overheads.
Energy-Efficient Deployment of Machine Learning Workloads on Neuromorphic Hardware
Oct 10, 2022

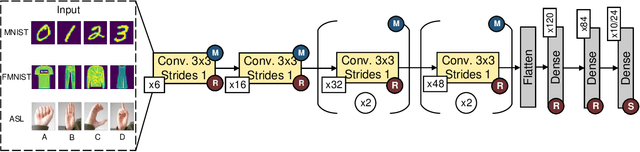
As the technology industry is moving towards implementing tasks such as natural language processing, path planning, image classification, and more on smaller edge computing devices, the demand for more efficient implementations of algorithms and hardware accelerators has become a significant area of research. In recent years, several edge deep learning hardware accelerators have been released that specifically focus on reducing the power and area consumed by deep neural networks (DNNs). On the other hand, spiking neural networks (SNNs) which operate on discrete time-series data, have been shown to achieve substantial power reductions over even the aforementioned edge DNN accelerators when deployed on specialized neuromorphic event-based/asynchronous hardware. While neuromorphic hardware has demonstrated great potential for accelerating deep learning tasks at the edge, the current space of algorithms and hardware is limited and still in rather early development. Thus, many hybrid approaches have been proposed which aim to convert pre-trained DNNs into SNNs. In this work, we provide a general guide to converting pre-trained DNNs into SNNs while also presenting techniques to improve the deployment of converted SNNs on neuromorphic hardware with respect to latency, power, and energy. Our experimental results show that when compared against the Intel Neural Compute Stick 2, Intel's neuromorphic processor, Loihi, consumes up to 27x less power and 5x less energy in the tested image classification tasks by using our SNN improvement techniques.
Static Hand Gesture Recognition for American Sign Language using Neuromorphic Hardware
Jul 25, 2022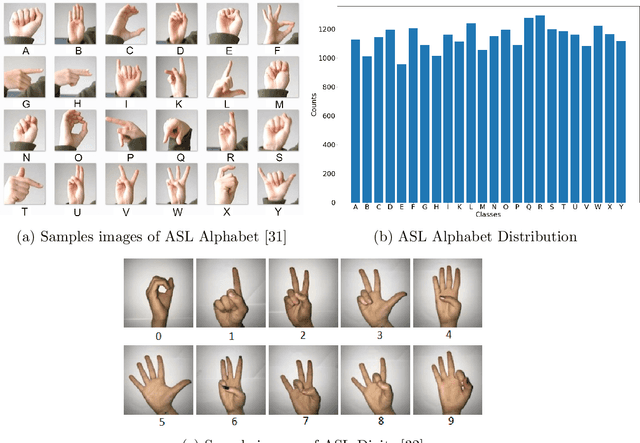

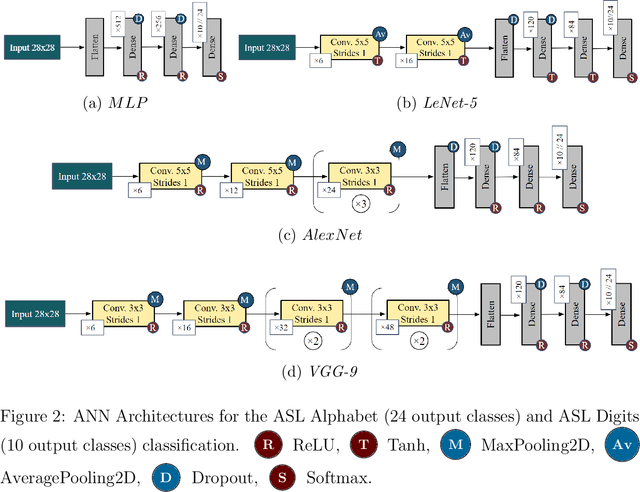
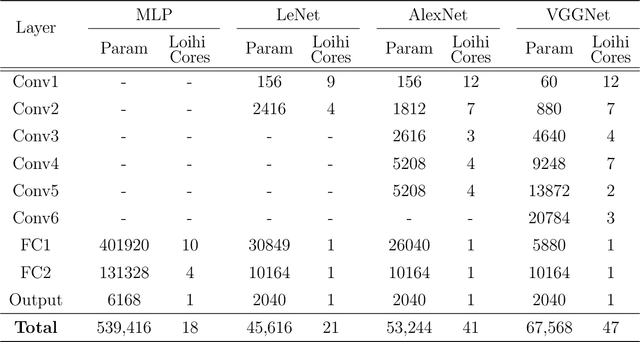
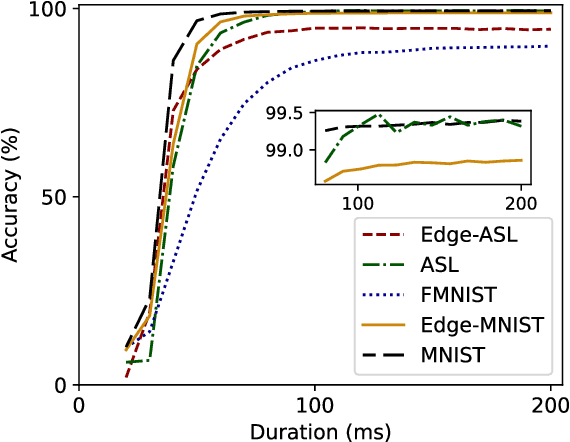
In this paper, we develop four spiking neural network (SNN) models for two static American Sign Language (ASL) hand gesture classification tasks, i.e., the ASL Alphabet and ASL Digits. The SNN models are deployed on Intel's neuromorphic platform, Loihi, and then compared against equivalent deep neural network (DNN) models deployed on an edge computing device, the Intel Neural Compute Stick 2 (NCS2). We perform a comprehensive comparison between the two systems in terms of accuracy, latency, power consumption, and energy. The best DNN model achieves an accuracy of 99.6% on the ASL Alphabet dataset, whereas the best performing SNN model has an accuracy of 99.44%. For the ASL-Digits dataset, the best SNN model outperforms all of its DNN counterparts with 99.52% accuracy. Moreover, our obtained experimental results show that the Loihi neuromorphic hardware implementations achieve up to 14.67x and 4.09x reduction in power consumption and energy, respectively, when compared to NCS2.
An Adaptive Sampling and Edge Detection Approach for Encoding Static Images for Spiking Neural Networks
Oct 19, 2021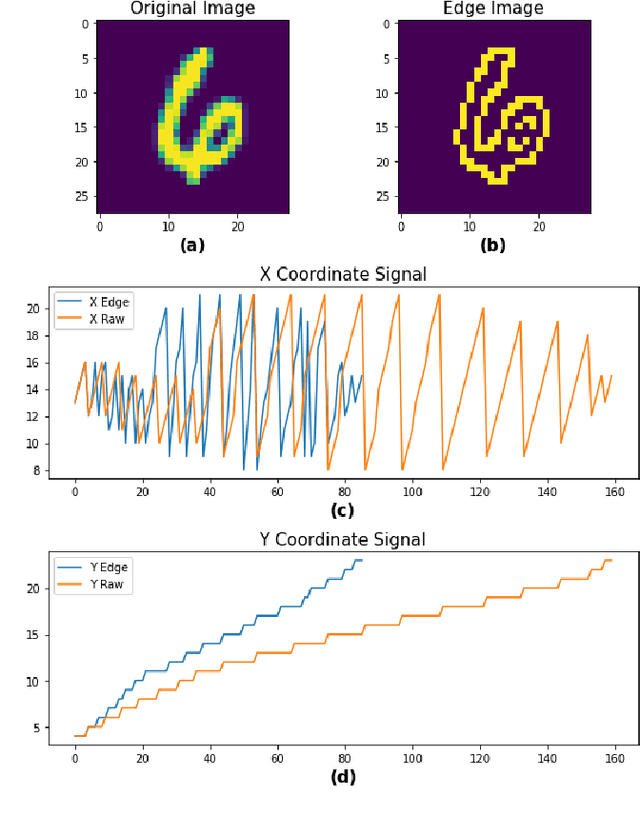
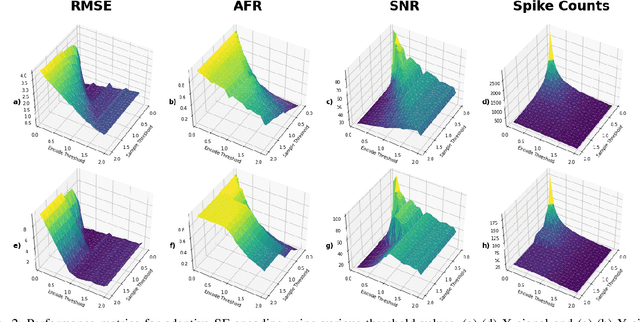
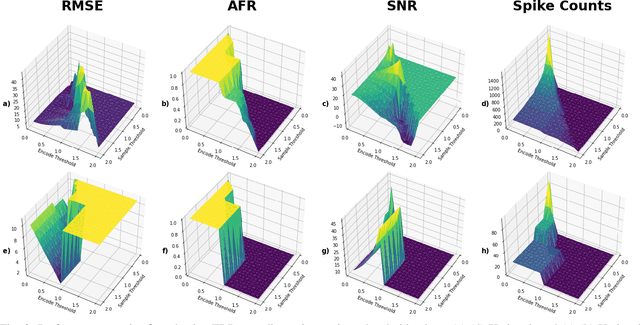
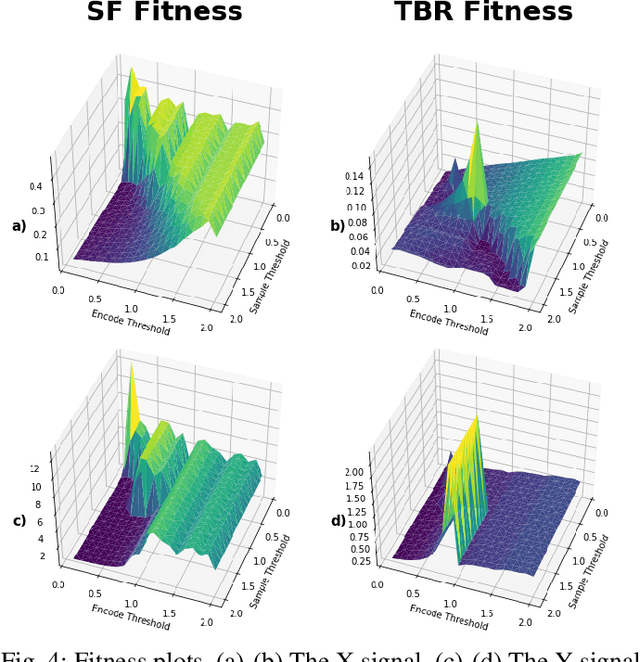
Current state-of-the-art methods of image classification using convolutional neural networks are often constrained by both latency and power consumption. This places a limit on the devices, particularly low-power edge devices, that can employ these methods. Spiking neural networks (SNNs) are considered to be the third generation of artificial neural networks which aim to address these latency and power constraints by taking inspiration from biological neuronal communication processes. Before data such as images can be input into an SNN, however, they must be first encoded into spike trains. Herein, we propose a method for encoding static images into temporal spike trains using edge detection and an adaptive signal sampling method for use in SNNs. The edge detection process consists of first performing Canny edge detection on the 2D static images and then converting the edge detected images into two X and Y signals using an image-to-signal conversion method. The adaptive signaling approach consists of sampling the signals such that the signals maintain enough detail and are sensitive to abrupt changes in the signal. Temporal encoding mechanisms such as threshold-based representation (TBR) and step-forward (SF) are then able to be used to convert the sampled signals into spike trains. We use various error and indicator metrics to optimize and evaluate the efficiency and precision of the proposed image encoding approach. Comparison results between the original and reconstructed signals from spike trains generated using edge-detection and adaptive temporal encoding mechanism exhibit 18x and 7x reduction in average root mean square error (RMSE) compared to the conventional SF and TBR encoding, respectively, while used for encoding MNIST dataset.