 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMPi: Optimizing LLMs for High-Throughput on Raspberry Pi
Apr 02, 2025Deploying Large Language Models (LLMs) on resource-constrained edge devices like the Raspberry Pi presents challenges in computational efficiency, power consumption, and response latency. This paper explores quantization-based optimization techniques to enable high-throughput, energy-efficient execution of LLMs on low-power embedded systems. Our approach leverages k-quantization, a Post-Training Quantization (PTQ) method designed for different bit-widths, enabling efficient 2-bit, 4-bit, 6-bit, and 8-bit weight quantization. Additionally, we employ ternary quantization using Quantization-Aware Training (QAT) for BitNet models, allowing for more effective adaptation to lower-bit representations while preserving accuracy. Our findings highlight the potential of quantized LLMs for real-time conversational AI on edge devices, paving the way for low-power, high-efficiency AI deployment in mobile and embedded applications. This study demonstrates that aggressive quantization strategies can significantly reduce energy consumption while maintaining inference quality, making LLMs practical for resource-limited environments.
PIM-LLM: A High-Throughput Hybrid PIM Architecture for 1-bit LLMs
Mar 31, 2025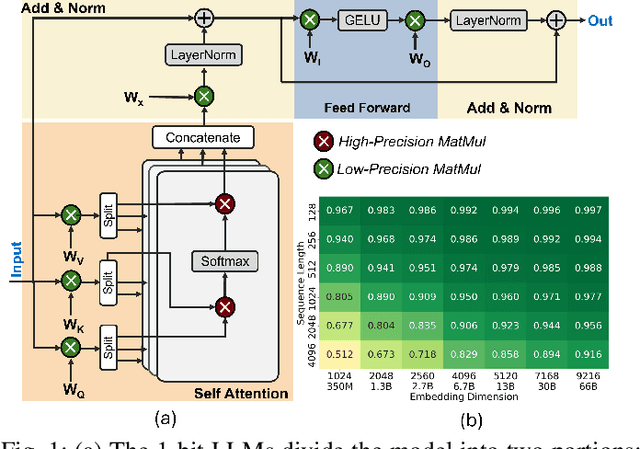
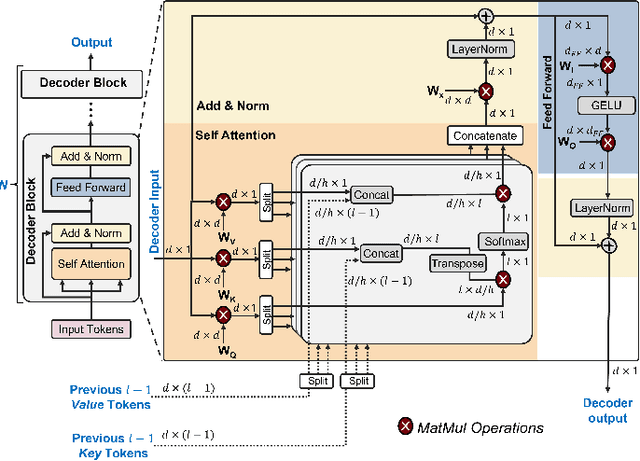
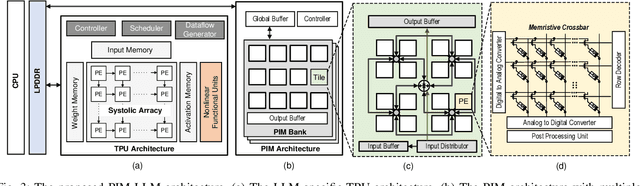
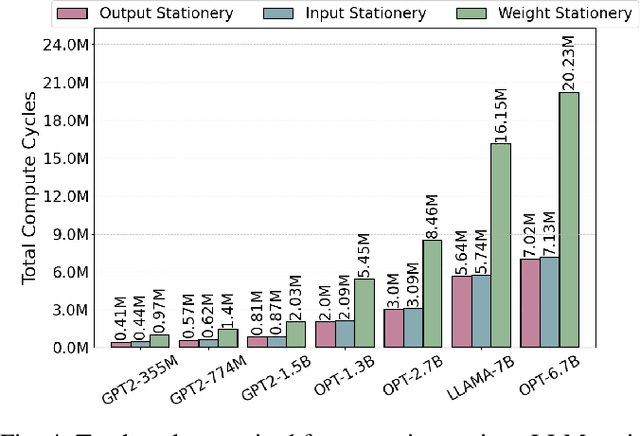
In this paper, we propose PIM-LLM, a hybrid architecture developed to accelerate 1-bit large language models (LLMs). PIM-LLM leverages analog processing-in-memory (PIM) architectures and digital systolic arrays to accelerate low-precision matrix multiplication (MatMul) operations in projection layers and high-precision MatMul operations in attention heads of 1-bit LLMs, respectively. Our design achieves up to roughly 80x improvement in tokens per second and a 70% increase in tokens per joule compared to conventional hardware accelerators. Additionally, PIM-LLM outperforms previous PIM-based LLM accelerators, setting a new benchmark with at least 2x and 5x improvement in GOPS and GOPS/W, respectively.
Matmul or No Matmal in the Era of 1-bit LLMs
Aug 21, 2024The advent of 1-bit large language models (LLMs) has attracted considerable attention and opened up new research opportunities. However, 1-bit LLMs only improve a fraction of models by applying extreme quantization to the projection layers while leaving attention heads unchanged. Therefore, to avoid fundamentally wrong choices of goals in future research, it is crucial to understand the actual improvements in computation and memory usage that 1-bit LLMs can deliver. In this work, we present an adaptation of Amdahl's Law tailored for the 1-bit LLM context, which illustrates how partial improvements in 1-bit LLMs impact overall model performance. Through extensive experiments, we uncover key nuances across different model architectures and hardware configurations, offering a roadmap for future research in the era of 1-bit LLMs.
WellDunn: On the Robustness and Explainability of Language Models and Large Language Models in Identifying Wellness Dimensions
Jun 17, 2024



Language Models (LMs) are being proposed for mental health applications where the heightened risk of adverse outcomes means predictive performance may not be a sufficient litmus test of a model's utility in clinical practice. A model that can be trusted for practice should have a correspondence between explanation and clinical determination, yet no prior research has examined the attention fidelity of these models and their effect on ground truth explanations. We introduce an evaluation design that focuses on the robustness and explainability of LMs in identifying Wellness Dimensions (WD). We focus on two mental health and well-being datasets: (a) Multi-label Classification-based MultiWD, and (b) WellXplain for evaluating attention mechanism veracity against expert-labeled explanations. The labels are based on Halbert Dunn's theory of wellness, which gives grounding to our evaluation. We reveal four surprising results about LMs/LLMs: (1) Despite their human-like capabilities, GPT-3.5/4 lag behind RoBERTa, and MedAlpaca, a fine-tuned LLM fails to deliver any remarkable improvements in performance or explanations. (2) Re-examining LMs' predictions based on a confidence-oriented loss function reveals a significant performance drop. (3) Across all LMs/LLMs, the alignment between attention and explanations remains low, with LLMs scoring a dismal 0.0. (4) Most mental health-specific LMs/LLMs overlook domain-specific knowledge and undervalue explanations, causing these discrepancies. This study highlights the need for further research into their consistency and explanations in mental health and well-being.
Process Knowledge-infused Learning for Clinician-friendly Explanations
Jun 16, 2023


Language models have the potential to assess mental health using social media data. By analyzing online posts and conversations, these models can detect patterns indicating mental health conditions like depression, anxiety, or suicidal thoughts. They examine keywords, language markers, and sentiment to gain insights into an individual's mental well-being. This information is crucial for early detection, intervention, and support, improving mental health care and prevention strategies. However, using language models for mental health assessments from social media has two limitations: (1) They do not compare posts against clinicians' diagnostic processes, and (2) It's challenging to explain language model outputs using concepts that the clinician can understand, i.e., clinician-friendly explanations. In this study, we introduce Process Knowledge-infused Learning (PK-iL), a new learning paradigm that layers clinical process knowledge structures on language model outputs, enabling clinician-friendly explanations of the underlying language model predictions. We rigorously test our methods on existing benchmark datasets, augmented with such clinical process knowledge, and release a new dataset for assessing suicidality. PK-iL performs competitively, achieving a 70% agreement with users, while other XAI methods only achieve 47% agreement (average inter-rater agreement of 0.72). Our evaluations demonstrate that PK-iL effectively explains model predictions to clinicians.
Demo Alleviate: Demonstrating Artificial Intelligence Enabled Virtual Assistance for Telehealth: The Mental Health Case
Mar 31, 2023



After the pandemic, artificial intelligence (AI) powered support for mental health care has become increasingly important. The breadth and complexity of significant challenges required to provide adequate care involve: (a) Personalized patient understanding, (b) Safety-constrained and medically validated chatbot patient interactions, and (c) Support for continued feedback-based refinements in design using chatbot-patient interactions. We propose Alleviate, a chatbot designed to assist patients suffering from mental health challenges with personalized care and assist clinicians with understanding their patients better. Alleviate draws from an array of publicly available clinically valid mental-health texts and databases, allowing Alleviate to make medically sound and informed decisions. In addition, Alleviate's modular design and explainable decision-making lends itself to robust and continued feedback-based refinements to its design. In this paper, we explain the different modules of Alleviate and submit a short video demonstrating Alleviate's capabilities to help patients and clinicians understand each other better to facilitate optimal care strategies.