 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLMs Obfuscate Code? A Systematic Analysis of Large Language Models into Assembly Code Obfuscation
Dec 24, 2024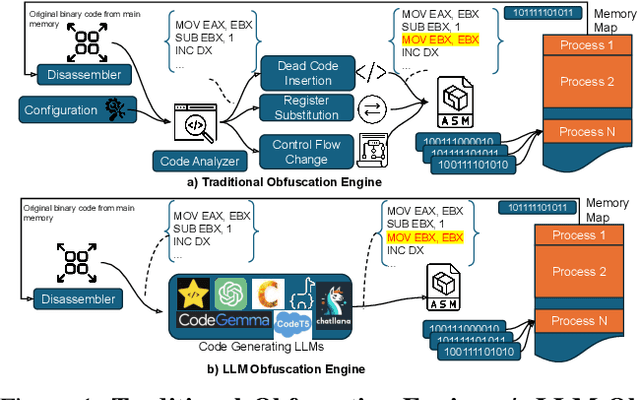


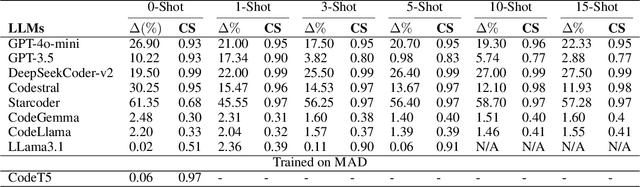
Malware authors often employ code obfuscations to make their malware harder to detect. Existing tools for generating obfuscated code often require access to the original source code (e.g., C++ or Java), and adding new obfuscations is a non-trivial, labor-intensive process. In this study, we ask the following question: Can Large Language Models (LLMs) potentially generate a new obfuscated assembly code? If so, this poses a risk to anti-virus engines and potentially increases the flexibility of attackers to create new obfuscation patterns. We answer this in the affirmative by developing the MetamorphASM benchmark comprising MetamorphASM Dataset (MAD) along with three code obfuscation techniques: dead code, register substitution, and control flow change. The MetamorphASM systematically evaluates the ability of LLMs to generate and analyze obfuscated code using MAD, which contains 328,200 obfuscated assembly code samples. We release this dataset and analyze the success rate of various LLMs (e.g., GPT-3.5/4, GPT-4o-mini, Starcoder, CodeGemma, CodeLlama, CodeT5, and LLaMA 3.1) in generating obfuscated assembly code. The evaluation was performed using established information-theoretic metrics and manual human review to ensure correctness and provide the foundation for researchers to study and develop remediations to this risk. The source code can be found at the following GitHub link: https://github.com/mohammadi-ali/MetamorphASM.
IoT-Based Preventive Mental Health Using Knowledge Graphs and Standards for Better Well-Being
Jun 19, 2024



Sustainable Development Goals (SDGs) give the UN a road map for development with Agenda 2030 as a target. SDG3 "Good Health and Well-Being" ensures healthy lives and promotes well-being for all ages. Digital technologies can support SDG3. Burnout and even depression could be reduced by encouraging better preventive health. Due to the lack of patient knowledge and focus to take care of their health, it is necessary to help patients before it is too late. New trends such as positive psychology and mindfulness are highly encouraged in the USA. Digital Twin (DT) can help with the continuous monitoring of emotion using physiological signals (e.g., collected via wearables). Digital twins facilitate monitoring and provide constant health insight to improve quality of life and well-being with better personalization. Healthcare DT challenges are standardizing data formats, communication protocols, and data exchange mechanisms. To achieve those data integration and knowledge challenges, we designed the Mental Health Knowledge Graph (ontology and dataset) to boost mental health. The Knowledge Graph (KG) acquires knowledge from ontology-based mental health projects classified within the LOV4IoT ontology catalog (Emotion, Depression, and Mental Health). Furthermore, the KG is mapped to standards (e.g., ontologies) when possible. Standards from ETSI SmartM2M, ITU/WHO, ISO, W3C, NIST, and IEEE are relevant to mental health.
WellDunn: On the Robustness and Explainability of Language Models and Large Language Models in Identifying Wellness Dimensions
Jun 17, 2024



Language Models (LMs) are being proposed for mental health applications where the heightened risk of adverse outcomes means predictive performance may not be a sufficient litmus test of a model's utility in clinical practice. A model that can be trusted for practice should have a correspondence between explanation and clinical determination, yet no prior research has examined the attention fidelity of these models and their effect on ground truth explanations. We introduce an evaluation design that focuses on the robustness and explainability of LMs in identifying Wellness Dimensions (WD). We focus on two mental health and well-being datasets: (a) Multi-label Classification-based MultiWD, and (b) WellXplain for evaluating attention mechanism veracity against expert-labeled explanations. The labels are based on Halbert Dunn's theory of wellness, which gives grounding to our evaluation. We reveal four surprising results about LMs/LLMs: (1) Despite their human-like capabilities, GPT-3.5/4 lag behind RoBERTa, and MedAlpaca, a fine-tuned LLM fails to deliver any remarkable improvements in performance or explanations. (2) Re-examining LMs' predictions based on a confidence-oriented loss function reveals a significant performance drop. (3) Across all LMs/LLMs, the alignment between attention and explanations remains low, with LLMs scoring a dismal 0.0. (4) Most mental health-specific LMs/LLMs overlook domain-specific knowledge and undervalue explanations, causing these discrepancies. This study highlights the need for further research into their consistency and explanations in mental health and well-being.