 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForgotten Polygons: Multimodal Large Language Models are Shape-Blind
Feb 21, 2025Despite strong performance on vision-language tasks, Multimodal Large Language Models (MLLMs) struggle with mathematical problem-solving, with both open-source and state-of-the-art models falling short of human performance on visual-math benchmarks. To systematically examine visual-mathematical reasoning in MLLMs, we (1) evaluate their understanding of geometric primitives, (2) test multi-step reasoning, and (3) explore a potential solution to improve visual reasoning capabilities. Our findings reveal fundamental shortcomings in shape recognition, with top models achieving under 50% accuracy in identifying regular polygons. We analyze these failures through the lens of dual-process theory and show that MLLMs rely on System 1 (intuitive, memorized associations) rather than System 2 (deliberate reasoning). Consequently, MLLMs fail to count the sides of both familiar and novel shapes, suggesting they have neither learned the concept of sides nor effectively process visual inputs. Finally, we propose Visually Cued Chain-of-Thought (VC-CoT) prompting, which enhances multi-step mathematical reasoning by explicitly referencing visual annotations in diagrams, boosting GPT-4o's accuracy on an irregular polygon side-counting task from 7% to 93%. Our findings suggest that System 2 reasoning in MLLMs remains an open problem, and visually-guided prompting is essential for successfully engaging visual reasoning. Code available at: https://github.com/rsinghlab/Shape-Blind.
Large Language Models for Mental Health Diagnostic Assessments: Exploring The Potential of Large Language Models for Assisting with Mental Health Diagnostic Assessments -- The Depression and Anxiety Case
Jan 02, 2025



Large language models (LLMs) are increasingly attracting the attention of healthcare professionals for their potential to assist in diagnostic assessments, which could alleviate the strain on the healthcare system caused by a high patient load and a shortage of providers. For LLMs to be effective in supporting diagnostic assessments, it is essential that they closely replicate the standard diagnostic procedures used by clinicians. In this paper, we specifically examine the diagnostic assessment processes described in the Patient Health Questionnaire-9 (PHQ-9) for major depressive disorder (MDD) and the Generalized Anxiety Disorder-7 (GAD-7) questionnaire for generalized anxiety disorder (GAD). We investigate various prompting and fine-tuning techniques to guide both proprietary and open-source LLMs in adhering to these processes, and we evaluate the agreement between LLM-generated diagnostic outcomes and expert-validated ground truth. For fine-tuning, we utilize the Mentalllama and Llama models, while for prompting, we experiment with proprietary models like GPT-3.5 and GPT-4o, as well as open-source models such as llama-3.1-8b and mixtral-8x7b.
What Do VLMs NOTICE? A Mechanistic Interpretability Pipeline for Noise-free Text-Image Corruption and Evaluation
Jun 24, 2024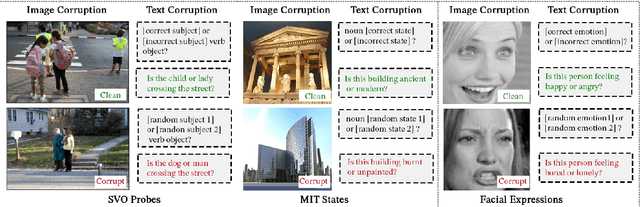

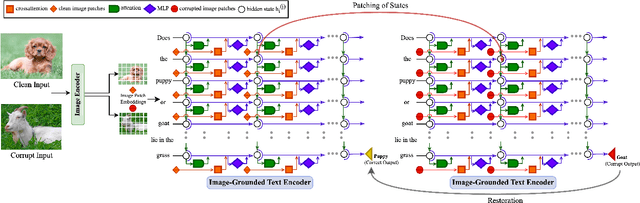
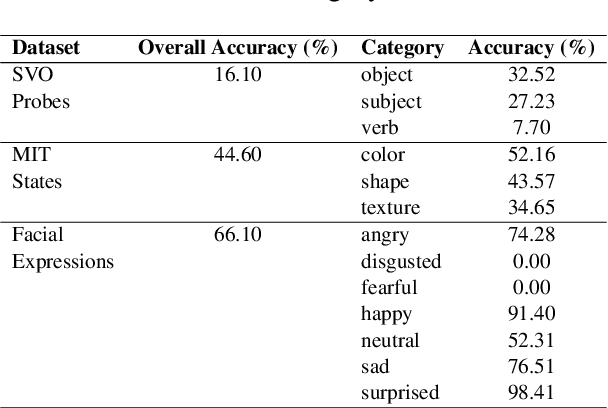
Vision-Language Models (VLMs) have gained community-spanning prominence due to their ability to integrate visual and textual inputs to perform complex tasks. Despite their success, the internal decision-making processes of these models remain opaque, posing challenges in high-stakes applications. To address this, we introduce NOTICE, the first Noise-free Text-Image Corruption and Evaluation pipeline for mechanistic interpretability in VLMs. NOTICE incorporates a Semantic Minimal Pairs (SMP) framework for image corruption and Symmetric Token Replacement (STR) for text. This approach enables semantically meaningful causal mediation analysis for both modalities, providing a robust method for analyzing multimodal integration within models like BLIP. Our experiments on the SVO-Probes, MIT-States, and Facial Expression Recognition datasets reveal crucial insights into VLM decision-making, identifying the significant role of middle-layer cross-attention heads. Further, we uncover a set of ``universal cross-attention heads'' that consistently contribute across tasks and modalities, each performing distinct functions such as implicit image segmentation, object inhibition, and outlier inhibition. This work paves the way for more transparent and interpretable multimodal systems.
WellDunn: On the Robustness and Explainability of Language Models and Large Language Models in Identifying Wellness Dimensions
Jun 17, 2024



Language Models (LMs) are being proposed for mental health applications where the heightened risk of adverse outcomes means predictive performance may not be a sufficient litmus test of a model's utility in clinical practice. A model that can be trusted for practice should have a correspondence between explanation and clinical determination, yet no prior research has examined the attention fidelity of these models and their effect on ground truth explanations. We introduce an evaluation design that focuses on the robustness and explainability of LMs in identifying Wellness Dimensions (WD). We focus on two mental health and well-being datasets: (a) Multi-label Classification-based MultiWD, and (b) WellXplain for evaluating attention mechanism veracity against expert-labeled explanations. The labels are based on Halbert Dunn's theory of wellness, which gives grounding to our evaluation. We reveal four surprising results about LMs/LLMs: (1) Despite their human-like capabilities, GPT-3.5/4 lag behind RoBERTa, and MedAlpaca, a fine-tuned LLM fails to deliver any remarkable improvements in performance or explanations. (2) Re-examining LMs' predictions based on a confidence-oriented loss function reveals a significant performance drop. (3) Across all LMs/LLMs, the alignment between attention and explanations remains low, with LLMs scoring a dismal 0.0. (4) Most mental health-specific LMs/LLMs overlook domain-specific knowledge and undervalue explanations, causing these discrepancies. This study highlights the need for further research into their consistency and explanations in mental health and well-being.
Towards Vision-Language Mechanistic Interpretability: A Causal Tracing Tool for BLIP
Aug 27, 2023



Mechanistic interpretability seeks to understand the neural mechanisms that enable specific behaviors in Large Language Models (LLMs) by leveraging causality-based methods. While these approaches have identified neural circuits that copy spans of text, capture factual knowledge, and more, they remain unusable for multimodal models since adapting these tools to the vision-language domain requires considerable architectural changes. In this work, we adapt a unimodal causal tracing tool to BLIP to enable the study of the neural mechanisms underlying image-conditioned text generation. We demonstrate our approach on a visual question answering dataset, highlighting the causal relevance of later layer representations for all tokens. Furthermore, we release our BLIP causal tracing tool as open source to enable further experimentation in vision-language mechanistic interpretability by the community. Our code is available at https://github.com/vedantpalit/Towards-Vision-Language-Mechanistic-Interpretability.
Knowledge Graph Guided Semantic Evaluation of Language Models For User Trust
May 08, 2023A fundamental question in natural language processing is - what kind of language structure and semantics is the language model capturing? Graph formats such as knowledge graphs are easy to evaluate as they explicitly express language semantics and structure. This study evaluates the semantics encoded in the self-attention transformers by leveraging explicit knowledge graph structures. We propose novel metrics to measure the reconstruction error when providing graph path sequences from a knowledge graph and trying to reproduce/reconstruct the same from the outputs of the self-attention transformer models. The opacity of language models has an immense bearing on societal issues of trust and explainable decision outcomes. Our findings suggest that language models are models of stochastic control processes for plausible language pattern generation. However, they do not ascribe object and concept-level meaning and semantics to the learned stochastic patterns such as those described in knowledge graphs. Furthermore, to enable robust evaluation of concept understanding by language models, we construct and make public an augmented language understanding benchmark built on the General Language Understanding Evaluation (GLUE) benchmark. This has significant application-level user trust implications as stochastic patterns without a strong sense of meaning cannot be trusted in high-stakes applications.