 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMechanisms of Prompt-Induced Hallucination in Vision-Language Models
Jan 08, 2026Large vision-language models (VLMs) are highly capable, yet often hallucinate by favoring textual prompts over visual evidence. We study this failure mode in a controlled object-counting setting, where the prompt overstates the number of objects in the image (e.g., asking a model to describe four waterlilies when only three are present). At low object counts, models often correct the overestimation, but as the number of objects increases, they increasingly conform to the prompt regardless of the discrepancy. Through mechanistic analysis of three VLMs, we identify a small set of attention heads whose ablation substantially reduces prompt-induced hallucinations (PIH) by at least 40% without additional training. Across models, PIH-heads mediate prompt copying in model-specific ways. We characterize these differences and show that PIH ablation increases correction toward visual evidence. Our findings offer insights into the internal mechanisms driving prompt-induced hallucinations, revealing model-specific differences in how these behaviors are implemented.
Pixels Versus Priors: Controlling Knowledge Priors in Vision-Language Models through Visual Counterfacts
May 21, 2025Multimodal Large Language Models (MLLMs) perform well on tasks such as visual question answering, but it remains unclear whether their reasoning relies more on memorized world knowledge or on the visual information present in the input image. To investigate this, we introduce Visual CounterFact, a new dataset of visually-realistic counterfactuals that put world knowledge priors (e.g, red strawberry) into direct conflict with visual input (e.g, blue strawberry). Using Visual CounterFact, we show that model predictions initially reflect memorized priors, but shift toward visual evidence in mid-to-late layers. This dynamic reveals a competition between the two modalities, with visual input ultimately overriding priors during evaluation. To control this behavior, we propose Pixels Versus Priors (PvP) steering vectors, a mechanism for controlling model outputs toward either world knowledge or visual input through activation-level interventions. On average, PvP successfully shifts 92.5% of color and 74.6% of size predictions from priors to counterfactuals. Together, these findings offer new tools for interpreting and controlling factual behavior in multimodal models.
What Do VLMs NOTICE? A Mechanistic Interpretability Pipeline for Noise-free Text-Image Corruption and Evaluation
Jun 24, 2024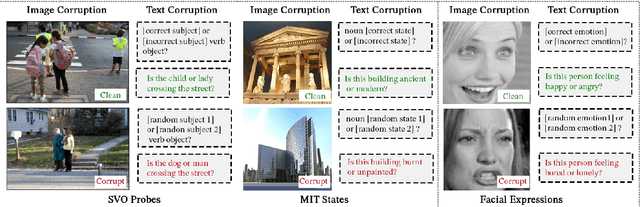

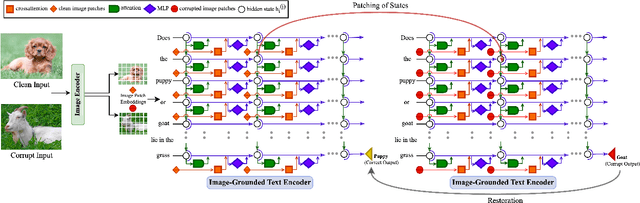
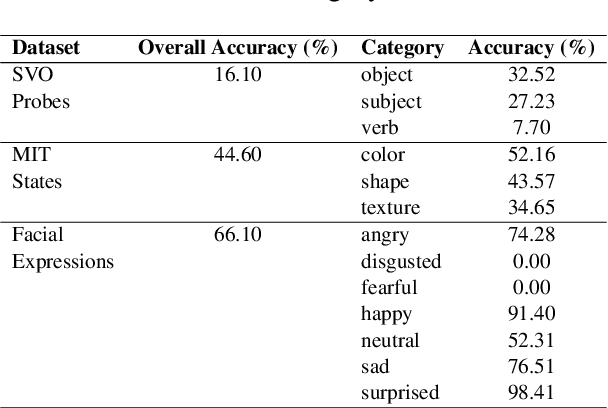
Vision-Language Models (VLMs) have gained community-spanning prominence due to their ability to integrate visual and textual inputs to perform complex tasks. Despite their success, the internal decision-making processes of these models remain opaque, posing challenges in high-stakes applications. To address this, we introduce NOTICE, the first Noise-free Text-Image Corruption and Evaluation pipeline for mechanistic interpretability in VLMs. NOTICE incorporates a Semantic Minimal Pairs (SMP) framework for image corruption and Symmetric Token Replacement (STR) for text. This approach enables semantically meaningful causal mediation analysis for both modalities, providing a robust method for analyzing multimodal integration within models like BLIP. Our experiments on the SVO-Probes, MIT-States, and Facial Expression Recognition datasets reveal crucial insights into VLM decision-making, identifying the significant role of middle-layer cross-attention heads. Further, we uncover a set of ``universal cross-attention heads'' that consistently contribute across tasks and modalities, each performing distinct functions such as implicit image segmentation, object inhibition, and outlier inhibition. This work paves the way for more transparent and interpretable multimodal systems.
One-Versus-Others Attention: Scalable Multimodal Integration
Jul 11, 2023



Multimodal learning models have become increasingly important as they surpass single-modality approaches on diverse tasks ranging from question-answering to autonomous driving. Despite the importance of multimodal learning, existing efforts focus on NLP applications, where the number of modalities is typically less than four (audio, video, text, images). However, data inputs in other domains, such as the medical field, may include X-rays, PET scans, MRIs, genetic screening, clinical notes, and more, creating a need for both efficient and accurate information fusion. Many state-of-the-art models rely on pairwise cross-modal attention, which does not scale well for applications with more than three modalities. For $n$ modalities, computing attention will result in $n \choose 2$ operations, potentially requiring considerable amounts of computational resources. To address this, we propose a new domain-neutral attention mechanism, One-Versus-Others (OvO) attention, that scales linearly with the number of modalities and requires only $n$ attention operations, thus offering a significant reduction in computational complexity compared to existing cross-modal attention algorithms. Using three diverse real-world datasets as well as an additional simulation experiment, we show that our method improves performance compared to popular fusion techniques while decreasing computation costs.
Multimodal Attention-based Deep Learning for Alzheimer's Disease Diagnosis
Jun 17, 2022
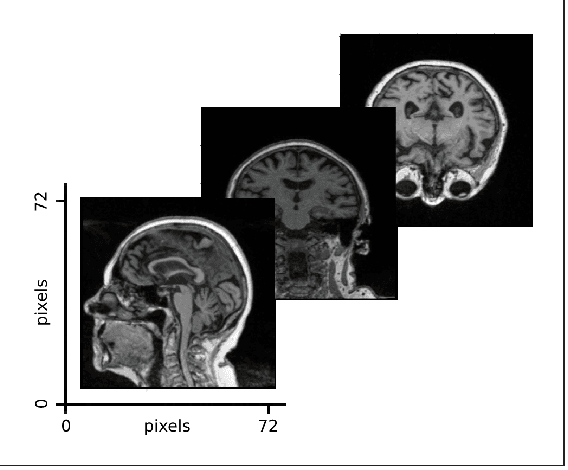

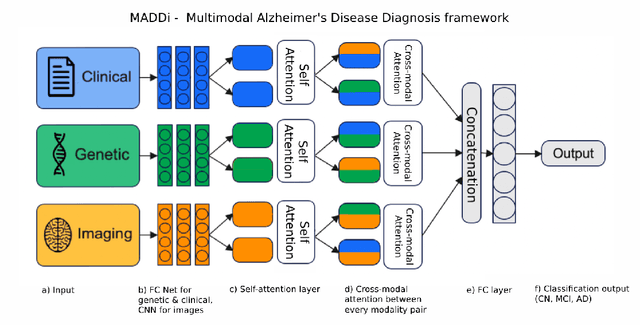
Alzheimer's Disease (AD) is the most common neurodegenerative disorder with one of the most complex pathogeneses, making effective and clinically actionable decision support difficult. The objective of this study was to develop a novel multimodal deep learning framework to aid medical professionals in AD diagnosis. We present a Multimodal Alzheimer's Disease Diagnosis framework (MADDi) to accurately detect the presence of AD and mild cognitive impairment (MCI) from imaging, genetic, and clinical data. MADDi is novel in that we use cross-modal attention, which captures interactions between modalities - a method not previously explored in this domain. We perform multi-class classification, a challenging task considering the strong similarities between MCI and AD. We compare with previous state-of-the-art models, evaluate the importance of attention, and examine the contribution of each modality to the model's performance. MADDi classifies MCI, AD, and controls with 96.88% accuracy on a held-out test set. When examining the contribution of different attention schemes, we found that the combination of cross-modal attention with self-attention performed the best, and no attention layers in the model performed the worst, with a 7.9% difference in F1-Scores. Our experiments underlined the importance of structured clinical data to help machine learning models contextualize and interpret the remaining modalities. Extensive ablation studies showed that any multimodal mixture of input features without access to structured clinical information suffered marked performance losses. This study demonstrates the merit of combining multiple input modalities via cross-modal attention to deliver highly accurate AD diagnostic decision support.