 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Do VLMs NOTICE? A Mechanistic Interpretability Pipeline for Noise-free Text-Image Corruption and Evaluation
Paper and Code
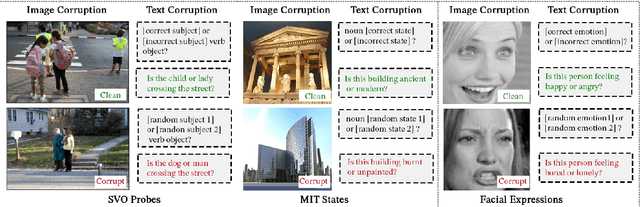

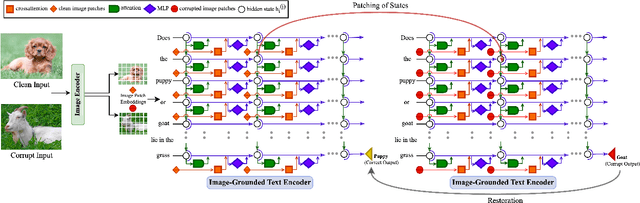
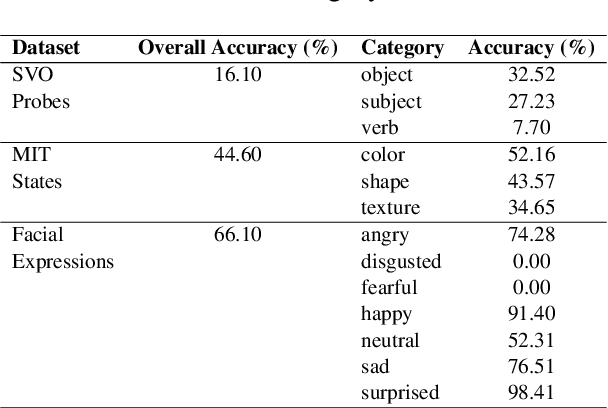
Vision-Language Models (VLMs) have gained community-spanning prominence due to their ability to integrate visual and textual inputs to perform complex tasks. Despite their success, the internal decision-making processes of these models remain opaque, posing challenges in high-stakes applications. To address this, we introduce NOTICE, the first Noise-free Text-Image Corruption and Evaluation pipeline for mechanistic interpretability in VLMs. NOTICE incorporates a Semantic Minimal Pairs (SMP) framework for image corruption and Symmetric Token Replacement (STR) for text. This approach enables semantically meaningful causal mediation analysis for both modalities, providing a robust method for analyzing multimodal integration within models like BLIP. Our experiments on the SVO-Probes, MIT-States, and Facial Expression Recognition datasets reveal crucial insights into VLM decision-making, identifying the significant role of middle-layer cross-attention heads. Further, we uncover a set of ``universal cross-attention heads'' that consistently contribute across tasks and modalities, each performing distinct functions such as implicit image segmentation, object inhibition, and outlier inhibition. This work paves the way for more transparent and interpretable multimodal systems.