 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Planning with Latent World Models
Apr 03, 2026Model predictive control (MPC) with learned world models has emerged as a promising paradigm for embodied control, particularly for its ability to generalize zero-shot when deployed in new environments. However, learned world models often struggle with long-horizon control due to the accumulation of prediction errors and the exponentially growing search space. In this work, we address these challenges by learning latent world models at multiple temporal scales and performing hierarchical planning across these scales, enabling long-horizon reasoning while substantially reducing inference-time planning complexity. Our approach serves as a modular planning abstraction that applies across diverse latent world-model architectures and domains. We demonstrate that this hierarchical approach enables zero-shot control on real-world non-greedy robotic tasks, achieving a 70% success rate on pick-&-place using only a final goal specification, compared to 0% for a single-level world model. In addition, across physics-based simulated environments including push manipulation and maze navigation, hierarchical planning achieves higher success while requiring up to 4x less planning-time compute.
V-JEPA 2.1: Unlocking Dense Features in Video Self-Supervised Learning
Mar 17, 2026We present V-JEPA 2.1, a family of self-supervised models that learn dense, high-quality visual representations for both images and videos while retaining strong global scene understanding. The approach combines four key components. First, a dense predictive loss uses a masking-based objective in which both visible and masked tokens contribute to the training signal, encouraging explicit spatial and temporal grounding. Second, deep self-supervision applies the self-supervised objective hierarchically across multiple intermediate encoder layers to improve representation quality. Third, multi-modal tokenizers enable unified training across images and videos. Finally, the model benefits from effective scaling in both model capacity and training data. Together, these design choices produce representations that are spatially structured, semantically coherent, and temporally consistent. Empirically, V-JEPA 2.1 achieves state-of-the-art performance on several challenging benchmarks, including 7.71 mAP on Ego4D for short-term object-interaction anticipation and 40.8 Recall@5 on EPIC-KITCHENS for high-level action anticipation, as well as a 20-point improvement in real-robot grasping success rate over V-JEPA-2 AC. The model also demonstrates strong performance in robotic navigation (5.687 ATE on TartanDrive), depth estimation (0.307 RMSE on NYUv2 with a linear probe), and global recognition (77.7 on Something-Something-V2). These results show that V-JEPA 2.1 significantly advances the state of the art in dense visual understanding and world modeling.
Beyond Language Modeling: An Exploration of Multimodal Pretraining
Mar 03, 2026The visual world offers a critical axis for advancing foundation models beyond language. Despite growing interest in this direction, the design space for native multimodal models remains opaque. We provide empirical clarity through controlled, from-scratch pretraining experiments, isolating the factors that govern multimodal pretraining without interference from language pretraining. We adopt the Transfusion framework, using next-token prediction for language and diffusion for vision, to train on diverse data including text, video, image-text pairs, and even action-conditioned video. Our experiments yield four key insights: (i) Representation Autoencoder (RAE) provides an optimal unified visual representation by excelling at both visual understanding and generation; (ii) visual and language data are complementary and yield synergy for downstream capabilities; (iii) unified multimodal pretraining leads naturally to world modeling, with capabilities emerging from general training; and (iv) Mixture-of-Experts (MoE) enables efficient and effective multimodal scaling while naturally inducing modality specialization. Through IsoFLOP analysis, we compute scaling laws for both modalities and uncover a scaling asymmetry: vision is significantly more data-hungry than language. We demonstrate that the MoE architecture harmonizes this scaling asymmetry by providing the high model capacity required by language while accommodating the data-intensive nature of vision, paving the way for truly unified multimodal models.
A Lightweight Library for Energy-Based Joint-Embedding Predictive Architectures
Feb 03, 2026We present EB-JEPA, an open-source library for learning representations and world models using Joint-Embedding Predictive Architectures (JEPAs). JEPAs learn to predict in representation space rather than pixel space, avoiding the pitfalls of generative modeling while capturing semantically meaningful features suitable for downstream tasks. Our library provides modular, self-contained implementations that illustrate how representation learning techniques developed for image-level self-supervised learning can transfer to video, where temporal dynamics add complexity, and ultimately to action-conditioned world models, where the model must additionally learn to predict the effects of control inputs. Each example is designed for single-GPU training within a few hours, making energy-based self-supervised learning accessible for research and education. We provide ablations of JEA components on CIFAR-10. Probing these representations yields 91% accuracy, indicating that the model learns useful features. Extending to video, we include a multi-step prediction example on Moving MNIST that demonstrates how the same principles scale to temporal modeling. Finally, we show how these representations can drive action-conditioned world models, achieving a 97% planning success rate on the Two Rooms navigation task. Comprehensive ablations reveal the critical importance of each regularization component for preventing representation collapse. Code is available at https://github.com/facebookresearch/eb_jepa.
Grounding Generated Videos in Feasible Plans via World Models
Feb 02, 2026Large-scale video generative models have shown emerging capabilities as zero-shot visual planners, yet video-generated plans often violate temporal consistency and physical constraints, leading to failures when mapped to executable actions. To address this, we propose Grounding Video Plans with World Models (GVP-WM), a planning method that grounds video-generated plans into feasible action sequences using a learned action-conditioned world model. At test-time, GVP-WM first generates a video plan from initial and goal observations, then projects the video guidance onto the manifold of dynamically feasible latent trajectories via video-guided latent collocation. In particular, we formulate grounding as a goal-conditioned latent-space trajectory optimization problem that jointly optimizes latent states and actions under world-model dynamics, while preserving semantic alignment with the video-generated plan. Empirically, GVP-WM recovers feasible long-horizon plans from zero-shot image-to-video-generated and motion-blurred videos that violate physical constraints, across navigation and manipulation simulation tasks.
Parallel Stochastic Gradient-Based Planning for World Models
Jan 31, 2026World models simulate environment dynamics from raw sensory inputs like video. However, using them for planning can be challenging due to the vast and unstructured search space. We propose a robust and highly parallelizable planner that leverages the differentiability of the learned world model for efficient optimization, solving long-horizon control tasks from visual input. Our method treats states as optimization variables ("virtual states") with soft dynamics constraints, enabling parallel computation and easier optimization. To facilitate exploration and avoid local optima, we introduce stochasticity into the states. To mitigate sensitive gradients through high-dimensional vision-based world models, we modify the gradient structure to descend towards valid plans while only requiring action-input gradients. Our planner, which we call GRASP (Gradient RelAxed Stochastic Planner), can be viewed as a stochastic version of a non-condensed or collocation-based optimal controller. We provide theoretical justification and experiments on video-based world models, where our resulting planner outperforms existing planning algorithms like the cross-entropy method (CEM) and vanilla gradient-based optimization (GD) on long-horizon experiments, both in success rate and time to convergence.
DeFM: Learning Foundation Representations from Depth for Robotics
Jan 26, 2026Depth sensors are widely deployed across robotic platforms, and advances in fast, high-fidelity depth simulation have enabled robotic policies trained on depth observations to achieve robust sim-to-real transfer for a wide range of tasks. Despite this, representation learning for depth modality remains underexplored compared to RGB, where large-scale foundation models now define the state of the art. To address this gap, we present DeFM, a self-supervised foundation model trained entirely on depth images for robotic applications. Using a DINO-style self-distillation objective on a curated dataset of 60M depth images, DeFM learns geometric and semantic representations that generalize to diverse environments, tasks, and sensors. To retain metric awareness across multiple scales, we introduce a novel input normalization strategy. We further distill DeFM into compact models suitable for resource-constrained robotic systems. When evaluated on depth-based classification, segmentation, navigation, locomotion, and manipulation benchmarks, DeFM achieves state-of-the-art performance and demonstrates strong generalization from simulation to real-world environments. We release all our pretrained models, which can be adopted off-the-shelf for depth-based robotic learning without task-specific fine-tuning. Webpage: https://de-fm.github.io/
World Models Can Leverage Human Videos for Dexterous Manipulation
Dec 15, 2025
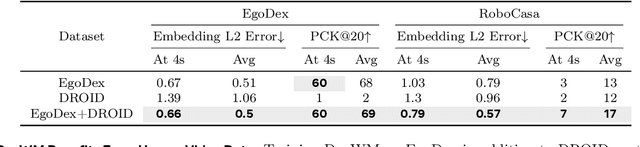
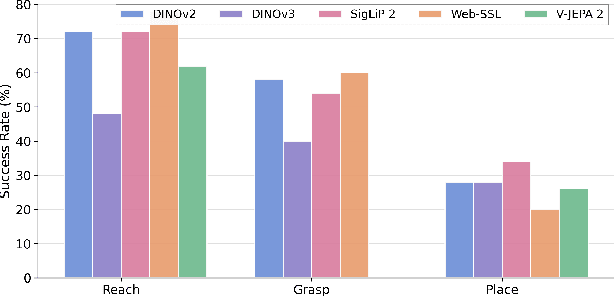
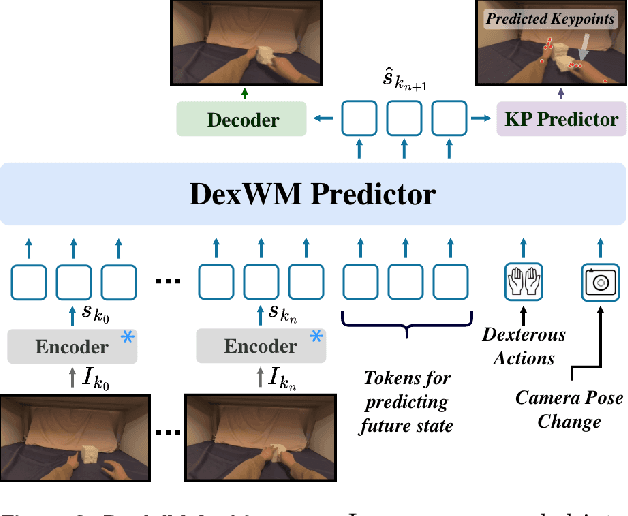
Dexterous manipulation is challenging because it requires understanding how subtle hand motion influences the environment through contact with objects. We introduce DexWM, a Dexterous Manipulation World Model that predicts the next latent state of the environment conditioned on past states and dexterous actions. To overcome the scarcity of dexterous manipulation datasets, DexWM is trained on over 900 hours of human and non-dexterous robot videos. To enable fine-grained dexterity, we find that predicting visual features alone is insufficient; therefore, we introduce an auxiliary hand consistency loss that enforces accurate hand configurations. DexWM outperforms prior world models conditioned on text, navigation, and full-body actions, achieving more accurate predictions of future states. DexWM also demonstrates strong zero-shot generalization to unseen manipulation skills when deployed on a Franka Panda arm equipped with an Allegro gripper, outperforming Diffusion Policy by over 50% on average in grasping, placing, and reaching tasks.
Whole-Body Conditioned Egocentric Video Prediction
Jun 26, 2025



We train models to Predict Ego-centric Video from human Actions (PEVA), given the past video and an action represented by the relative 3D body pose. By conditioning on kinematic pose trajectories, structured by the joint hierarchy of the body, our model learns to simulate how physical human actions shape the environment from a first-person point of view. We train an auto-regressive conditional diffusion transformer on Nymeria, a large-scale dataset of real-world egocentric video and body pose capture. We further design a hierarchical evaluation protocol with increasingly challenging tasks, enabling a comprehensive analysis of the model's embodied prediction and control abilities. Our work represents an initial attempt to tackle the challenges of modeling complex real-world environments and embodied agent behaviors with video prediction from the perspective of a human.
Pixels Versus Priors: Controlling Knowledge Priors in Vision-Language Models through Visual Counterfacts
May 21, 2025Multimodal Large Language Models (MLLMs) perform well on tasks such as visual question answering, but it remains unclear whether their reasoning relies more on memorized world knowledge or on the visual information present in the input image. To investigate this, we introduce Visual CounterFact, a new dataset of visually-realistic counterfactuals that put world knowledge priors (e.g, red strawberry) into direct conflict with visual input (e.g, blue strawberry). Using Visual CounterFact, we show that model predictions initially reflect memorized priors, but shift toward visual evidence in mid-to-late layers. This dynamic reveals a competition between the two modalities, with visual input ultimately overriding priors during evaluation. To control this behavior, we propose Pixels Versus Priors (PvP) steering vectors, a mechanism for controlling model outputs toward either world knowledge or visual input through activation-level interventions. On average, PvP successfully shifts 92.5% of color and 74.6% of size predictions from priors to counterfactuals. Together, these findings offer new tools for interpreting and controlling factual behavior in multimodal models.