 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracking by Predicting 3-D Gaussians Over Time
Dec 30, 2025We propose Video Gaussian Masked Autoencoders (Video-GMAE), a self-supervised approach for representation learning that encodes a sequence of images into a set of Gaussian splats moving over time. Representing a video as a set of Gaussians enforces a reasonable inductive bias: that 2-D videos are often consistent projections of a dynamic 3-D scene. We find that tracking emerges when pretraining a network with this architecture. Mapping the trajectory of the learnt Gaussians onto the image plane gives zero-shot tracking performance comparable to state-of-the-art. With small-scale finetuning, our models achieve 34.6% improvement on Kinetics, and 13.1% on Kubric datasets, surpassing existing self-supervised video approaches. The project page and code are publicly available at https://videogmae.org/ and https://github.com/tekotan/video-gmae.
Perception Encoder: The best visual embeddings are not at the output of the network
Apr 17, 2025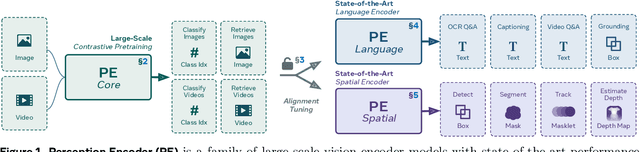

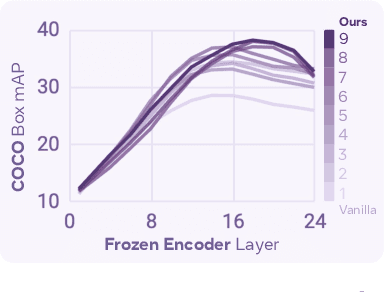
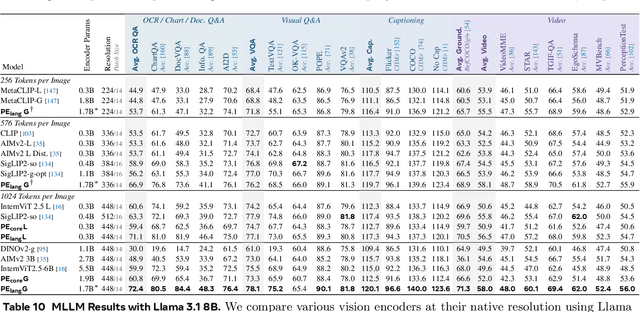
We introduce Perception Encoder (PE), a state-of-the-art encoder for image and video understanding trained via simple vision-language learning. Traditionally, vision encoders have relied on a variety of pretraining objectives, each tailored to specific downstream tasks such as classification, captioning, or localization. Surprisingly, after scaling our carefully tuned image pretraining recipe and refining with our robust video data engine, we find that contrastive vision-language training alone can produce strong, general embeddings for all of these downstream tasks. There is only one caveat: these embeddings are hidden within the intermediate layers of the network. To draw them out, we introduce two alignment methods, language alignment for multimodal language modeling, and spatial alignment for dense prediction. Together with the core contrastive checkpoint, our PE family of models achieves state-of-the-art performance on a wide variety of tasks, including zero-shot image and video classification and retrieval; document, image, and video Q&A; and spatial tasks such as detection, depth estimation, and tracking. To foster further research, we are releasing our models, code, and a novel dataset of synthetically and human-annotated videos.
Poly-Autoregressive Prediction for Modeling Interactions
Feb 12, 2025We introduce a simple framework for predicting the behavior of an agent in multi-agent settings. In contrast to autoregressive (AR) tasks, such as language processing, our focus is on scenarios with multiple agents whose interactions are shaped by physical constraints and internal motivations. To this end, we propose Poly-Autoregressive (PAR) modeling, which forecasts an ego agent's future behavior by reasoning about the ego agent's state history and the past and current states of other interacting agents. At its core, PAR represents the behavior of all agents as a sequence of tokens, each representing an agent's state at a specific timestep. With minimal data pre-processing changes, we show that PAR can be applied to three different problems: human action forecasting in social situations, trajectory prediction for autonomous vehicles, and object pose forecasting during hand-object interaction. Using a small proof-of-concept transformer backbone, PAR outperforms AR across these three scenarios. The project website can be found at https://neerja.me/PAR/.
An Empirical Study of Autoregressive Pre-training from Videos
Jan 09, 2025



We empirically study autoregressive pre-training from videos. To perform our study, we construct a series of autoregressive video models, called Toto. We treat videos as sequences of visual tokens and train transformer models to autoregressively predict future tokens. Our models are pre-trained on a diverse dataset of videos and images comprising over 1 trillion visual tokens. We explore different architectural, training, and inference design choices. We evaluate the learned visual representations on a range of downstream tasks including image recognition, video classification, object tracking, and robotics. Our results demonstrate that, despite minimal inductive biases, autoregressive pre-training leads to competitive performance across all benchmarks. Finally, we find that scaling our video models results in similar scaling curves to those seen in language models, albeit with a different rate. More details at https://brjathu.github.io/toto/
Gaussian Masked Autoencoders
Jan 06, 2025



This paper explores Masked Autoencoders (MAE) with Gaussian Splatting. While reconstructive self-supervised learning frameworks such as MAE learns good semantic abstractions, it is not trained for explicit spatial awareness. Our approach, named Gaussian Masked Autoencoder, or GMAE, aims to learn semantic abstractions and spatial understanding jointly. Like MAE, it reconstructs the image end-to-end in the pixel space, but beyond MAE, it also introduces an intermediate, 3D Gaussian-based representation and renders images via splatting. We show that GMAE can enable various zero-shot learning capabilities of spatial understanding (e.g., figure-ground segmentation, image layering, edge detection, etc.) while preserving the high-level semantics of self-supervised representation quality from MAE. To our knowledge, we are the first to employ Gaussian primitives in an image representation learning framework beyond optimization-based single-scene reconstructions. We believe GMAE will inspire further research in this direction and contribute to developing next-generation techniques for modeling high-fidelity visual data. More details at https://brjathu.github.io/gmae
Scaling Properties of Diffusion Models for Perceptual Tasks
Nov 13, 2024


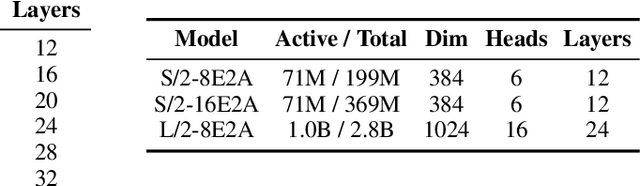
In this paper, we argue that iterative computation with diffusion models offers a powerful paradigm for not only generation but also visual perception tasks. We unify tasks such as depth estimation, optical flow, and amodal segmentation under the framework of image-to-image translation, and show how diffusion models benefit from scaling training and test-time compute for these perceptual tasks. Through a careful analysis of these scaling properties, we formulate compute-optimal training and inference recipes to scale diffusion models for visual perception tasks. Our models achieve competitive performance to state-of-the-art methods using significantly less data and compute. To access our code and models, see https://scaling-diffusion-perception.github.io .
Synergy and Synchrony in Couple Dances
Sep 06, 2024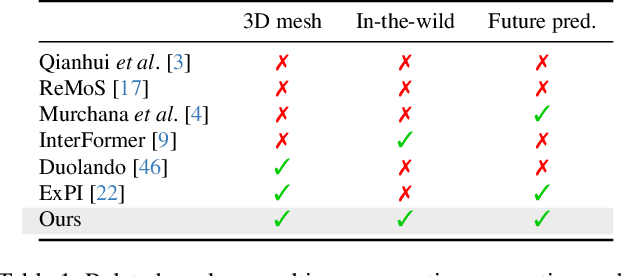
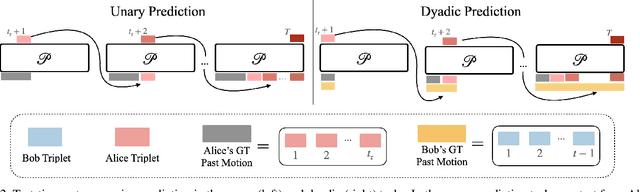
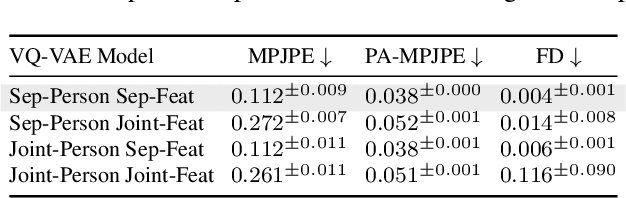
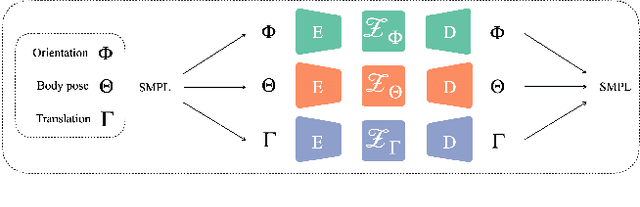
This paper asks to what extent social interaction influences one's behavior. We study this in the setting of two dancers dancing as a couple. We first consider a baseline in which we predict a dancer's future moves conditioned only on their past motion without regard to their partner. We then investigate the advantage of taking social information into account by conditioning also on the motion of their dancing partner. We focus our analysis on Swing, a dance genre with tight physical coupling for which we present an in-the-wild video dataset. We demonstrate that single-person future motion prediction in this context is challenging. Instead, we observe that prediction greatly benefits from considering the interaction partners' behavior, resulting in surprisingly compelling couple dance synthesis results (see supp. video). Our contributions are a demonstration of the advantages of socially conditioned future motion prediction and an in-the-wild, couple dance video dataset to enable future research in this direction. Video results are available on the project website: https://von31.github.io/synNsync
FewShotNeRF: Meta-Learning-based Novel View Synthesis for Rapid Scene-Specific Adaptation
Aug 09, 2024
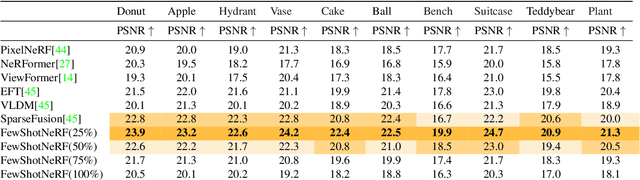
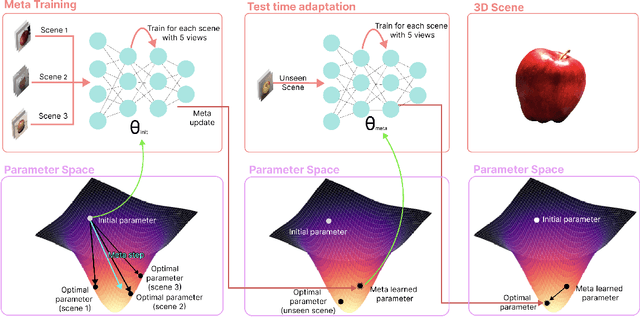
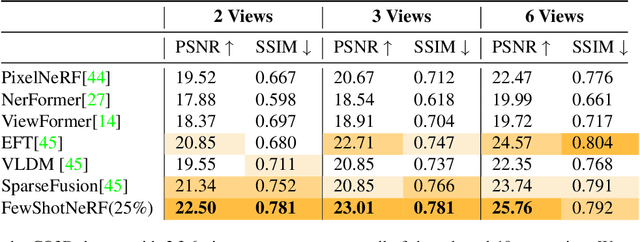
In this paper, we address the challenge of generating novel views of real-world objects with limited multi-view images through our proposed approach, FewShotNeRF. Our method utilizes meta-learning to acquire optimal initialization, facilitating rapid adaptation of a Neural Radiance Field (NeRF) to specific scenes. The focus of our meta-learning process is on capturing shared geometry and textures within a category, embedded in the weight initialization. This approach expedites the learning process of NeRFs and leverages recent advancements in positional encodings to reduce the time required for fitting a NeRF to a scene, thereby accelerating the inner loop optimization of meta-learning. Notably, our method enables meta-learning on a large number of 3D scenes to establish a robust 3D prior for various categories. Through extensive evaluations on the Common Objects in 3D open source dataset, we empirically demonstrate the efficacy and potential of meta-learning in generating high-quality novel views of objects.
EgoPet: Egomotion and Interaction Data from an Animal's Perspective
Apr 15, 2024

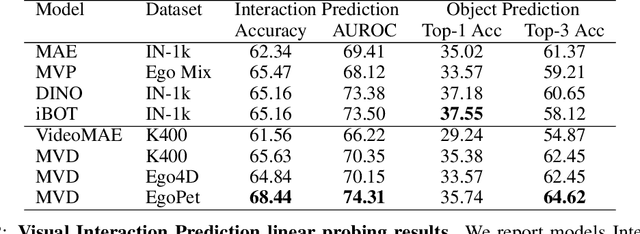

Animals perceive the world to plan their actions and interact with other agents to accomplish complex tasks, demonstrating capabilities that are still unmatched by AI systems. To advance our understanding and reduce the gap between the capabilities of animals and AI systems, we introduce a dataset of pet egomotion imagery with diverse examples of simultaneous egomotion and multi-agent interaction. Current video datasets separately contain egomotion and interaction examples, but rarely both at the same time. In addition, EgoPet offers a radically distinct perspective from existing egocentric datasets of humans or vehicles. We define two in-domain benchmark tasks that capture animal behavior, and a third benchmark to assess the utility of EgoPet as a pretraining resource to robotic quadruped locomotion, showing that models trained from EgoPet outperform those trained from prior datasets.
Humanoid Locomotion as Next Token Prediction
Feb 29, 2024



We cast real-world humanoid control as a next token prediction problem, akin to predicting the next word in language. Our model is a causal transformer trained via autoregressive prediction of sensorimotor trajectories. To account for the multi-modal nature of the data, we perform prediction in a modality-aligned way, and for each input token predict the next token from the same modality. This general formulation enables us to leverage data with missing modalities, like video trajectories without actions. We train our model on a collection of simulated trajectories coming from prior neural network policies, model-based controllers, motion capture data, and YouTube videos of humans. We show that our model enables a full-sized humanoid to walk in San Francisco zero-shot. Our model can transfer to the real world even when trained on only 27 hours of walking data, and can generalize to commands not seen during training like walking backward. These findings suggest a promising path toward learning challenging real-world control tasks by generative modeling of sensorimotor trajectories.