 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPARK: Skeleton-Parameter Aligned Retargeting on Humanoid Robots with Kinodynamic Trajectory Optimization
Mar 12, 2026Human motion provides rich priors for training general-purpose humanoid control policies, but raw demonstrations are often incompatible with a robot's kinematics and dynamics, limiting their direct use. We present a two-stage pipeline for generating natural and dynamically feasible motion references from task-space human data. First, we convert human motion into a unified robot description format (URDF)-based skeleton representation and calibrate it to the target humanoid's dimensions. By aligning the underlying skeleton structure rather than heuristically modifying task-space targets, this step significantly reduces inverse kinematics error and tuning effort. Second, we refine the retargeted trajectories through progressive kinodynamic trajectory optimization (TO), solved in three stages: kinematic TO, inverse dynamics, and full kinodynamic TO, each warm-started from the previous solution. The final result yields dynamically consistent state trajectories and joint torque profiles, providing high-quality references for learning-based controllers. Together, skeleton calibration and kinodynamic TO enable the generation of natural, physically consistent motion references across diverse humanoid platforms.
HITTER: A HumanoId Table TEnnis Robot via Hierarchical Planning and Learning
Aug 28, 2025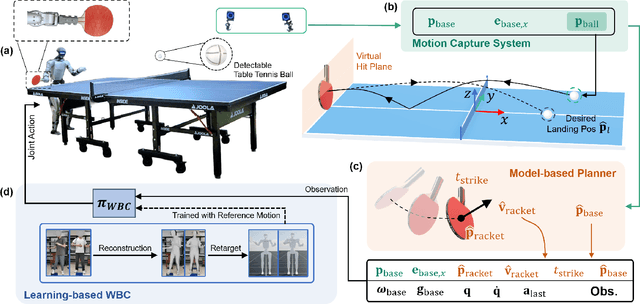
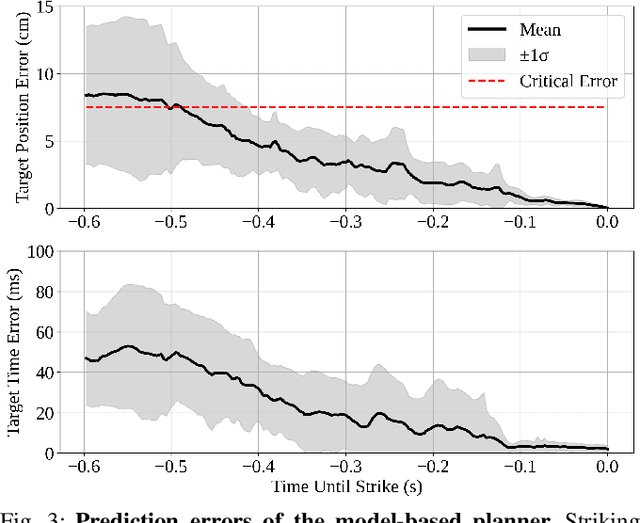
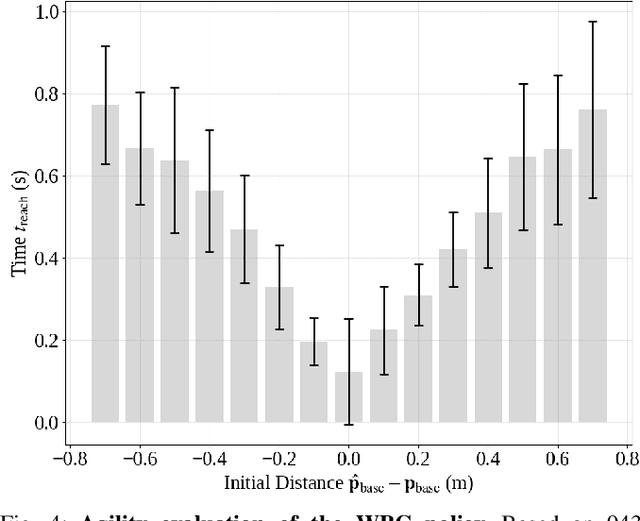

Humanoid robots have recently achieved impressive progress in locomotion and whole-body control, yet they remain constrained in tasks that demand rapid interaction with dynamic environments through manipulation. Table tennis exemplifies such a challenge: with ball speeds exceeding 5 m/s, players must perceive, predict, and act within sub-second reaction times, requiring both agility and precision. To address this, we present a hierarchical framework for humanoid table tennis that integrates a model-based planner for ball trajectory prediction and racket target planning with a reinforcement learning-based whole-body controller. The planner determines striking position, velocity and timing, while the controller generates coordinated arm and leg motions that mimic human strikes and maintain stability and agility across consecutive rallies. Moreover, to encourage natural movements, human motion references are incorporated during training. We validate our system on a general-purpose humanoid robot, achieving up to 106 consecutive shots with a human opponent and sustained exchanges against another humanoid. These results demonstrate real-world humanoid table tennis with sub-second reactive control, marking a step toward agile and interactive humanoid behaviors.
LangWBC: Language-directed Humanoid Whole-Body Control via End-to-end Learning
Apr 30, 2025General-purpose humanoid robots are expected to interact intuitively with humans, enabling seamless integration into daily life. Natural language provides the most accessible medium for this purpose. However, translating language into humanoid whole-body motion remains a significant challenge, primarily due to the gap between linguistic understanding and physical actions. In this work, we present an end-to-end, language-directed policy for real-world humanoid whole-body control. Our approach combines reinforcement learning with policy distillation, allowing a single neural network to interpret language commands and execute corresponding physical actions directly. To enhance motion diversity and compositionality, we incorporate a Conditional Variational Autoencoder (CVAE) structure. The resulting policy achieves agile and versatile whole-body behaviors conditioned on language inputs, with smooth transitions between various motions, enabling adaptation to linguistic variations and the emergence of novel motions. We validate the efficacy and generalizability of our method through extensive simulations and real-world experiments, demonstrating robust whole-body control. Please see our website at LangWBC.github.io for more information.
Berkeley Humanoid: A Research Platform for Learning-based Control
Jul 31, 2024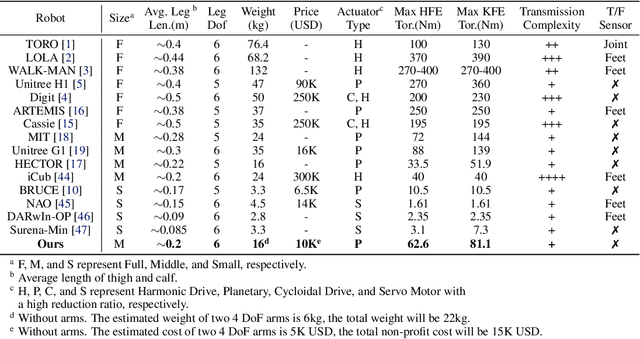
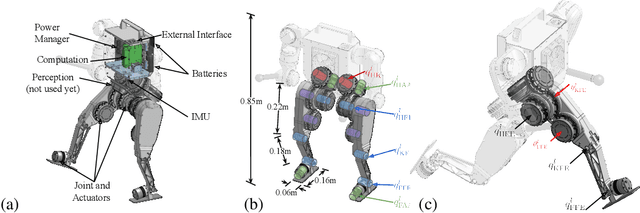
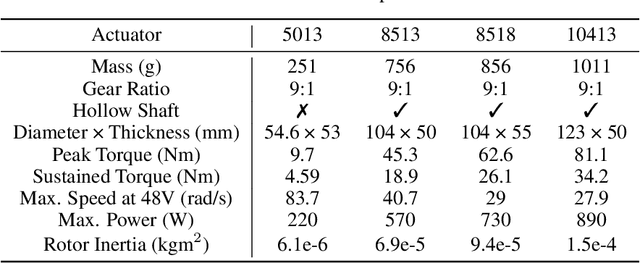
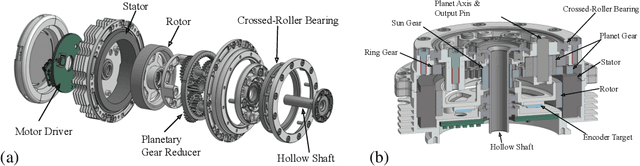
We introduce Berkeley Humanoid, a reliable and low-cost mid-scale humanoid research platform for learning-based control. Our lightweight, in-house-built robot is designed specifically for learning algorithms with low simulation complexity, anthropomorphic motion, and high reliability against falls. The robot's narrow sim-to-real gap enables agile and robust locomotion across various terrains in outdoor environments, achieved with a simple reinforcement learning controller using light domain randomization. Furthermore, we demonstrate the robot traversing for hundreds of meters, walking on a steep unpaved trail, and hopping with single and double legs as a testimony to its high performance in dynamical walking. Capable of omnidirectional locomotion and withstanding large perturbations with a compact setup, our system aims for scalable, sim-to-real deployment of learning-based humanoid systems. Please check http://berkeley-humanoid.com for more details.
Adaptive Energy Regularization for Autonomous Gait Transition and Energy-Efficient Quadruped Locomotion
Mar 29, 2024



In reinforcement learning for legged robot locomotion, crafting effective reward strategies is crucial. Pre-defined gait patterns and complex reward systems are widely used to stabilize policy training. Drawing from the natural locomotion behaviors of humans and animals, which adapt their gaits to minimize energy consumption, we propose a simplified, energy-centric reward strategy to foster the development of energy-efficient locomotion across various speeds in quadruped robots. By implementing an adaptive energy reward function and adjusting the weights based on velocity, we demonstrate that our approach enables ANYmal-C and Unitree Go1 robots to autonomously select appropriate gaits, such as four-beat walking at lower speeds and trotting at higher speeds, resulting in improved energy efficiency and stable velocity tracking compared to previous methods using complex reward designs and prior gait knowledge. The effectiveness of our policy is validated through simulations in the IsaacGym simulation environment and on real robots, demonstrating its potential to facilitate stable and adaptive locomotion.
Humanoid Locomotion as Next Token Prediction
Feb 29, 2024



We cast real-world humanoid control as a next token prediction problem, akin to predicting the next word in language. Our model is a causal transformer trained via autoregressive prediction of sensorimotor trajectories. To account for the multi-modal nature of the data, we perform prediction in a modality-aligned way, and for each input token predict the next token from the same modality. This general formulation enables us to leverage data with missing modalities, like video trajectories without actions. We train our model on a collection of simulated trajectories coming from prior neural network policies, model-based controllers, motion capture data, and YouTube videos of humans. We show that our model enables a full-sized humanoid to walk in San Francisco zero-shot. Our model can transfer to the real world even when trained on only 27 hours of walking data, and can generalize to commands not seen during training like walking backward. These findings suggest a promising path toward learning challenging real-world control tasks by generative modeling of sensorimotor trajectories.
Constraint-Guided Online Data Selection for Scalable Data-Driven Safety Filters in Uncertain Robotic Systems
Nov 23, 2023As the use of autonomous robotic systems expands in tasks that are complex and challenging to model, the demand for robust data-driven control methods that can certify safety and stability in uncertain conditions is increasing. However, the practical implementation of these methods often faces scalability issues due to the growing amount of data points with system complexity, and a significant reliance on high-quality training data. In response to these challenges, this study presents a scalable data-driven controller that efficiently identifies and infers from the most informative data points for implementing data-driven safety filters. Our approach is grounded in the integration of a model-based certificate function-based method and Gaussian Process (GP) regression, reinforced by a novel online data selection algorithm that reduces time complexity from quadratic to linear relative to dataset size. Empirical evidence, gathered from successful real-world cart-pole swing-up experiments and simulated locomotion of a five-link bipedal robot, demonstrates the efficacy of our approach. Our findings reveal that our efficient online data selection algorithm, which strategically selects key data points, enhances the practicality and efficiency of data-driven certifying filters in complex robotic systems, significantly mitigating scalability concerns inherent in nonparametric learning-based control methods.
Prompt a Robot to Walk with Large Language Models
Sep 18, 2023



Large language models (LLMs) pre-trained on vast internet-scale data have showcased remarkable capabilities across diverse domains. Recently, there has been escalating interest in deploying LLMs for robotics, aiming to harness the power of foundation models in real-world settings. However, this approach faces significant challenges, particularly in grounding these models in the physical world and in generating dynamic robot motions. To address these issues, we introduce a novel paradigm in which we use few-shot prompts collected from the physical environment, enabling the LLM to autoregressively generate low-level control commands for robots without task-specific fine-tuning. Experiments across various robots and environments validate that our method can effectively prompt a robot to walk. We thus illustrate how LLMs can proficiently function as low-level feedback controllers for dynamic motion control even in high-dimensional robotic systems. The project website and source code can be found at: https://prompt2walk.github.io/ .
Learning Humanoid Locomotion with Transformers
Mar 06, 2023We present a sim-to-real learning-based approach for real-world humanoid locomotion. Our controller is a causal Transformer trained by autoregressive prediction of future actions from the history of observations and actions. We hypothesize that the observation-action history contains useful information about the world that a powerful Transformer model can use to adapt its behavior in-context, without updating its weights. We do not use state estimation, dynamics models, trajectory optimization, reference trajectories, or pre-computed gait libraries. Our controller is trained with large-scale model-free reinforcement learning on an ensemble of randomized environments in simulation and deployed to the real world in a zero-shot fashion. We evaluate our approach in high-fidelity simulation and successfully deploy it to the real robot as well. To the best of our knowledge, this is the first demonstration of a fully learning-based method for real-world full-sized humanoid locomotion.
Probabilistic Safe Online Learning with Control Barrier Functions
Aug 23, 2022

Learning-based control schemes have recently shown great efficacy performing complex tasks. However, in order to deploy them in real systems, it is of vital importance to guarantee that the system will remain safe during online training and execution. We therefore need safe online learning frameworks able to autonomously reason about whether the current information at their disposal is enough to ensure safety or, in contrast, new measurements are required. In this paper, we present a framework consisting of two parts: first, an out-of-distribution detection mechanism actively collecting measurements when needed to guarantee that at least one safety backup direction is always available for use; and second, a Gaussian Process-based probabilistic safety-critical controller that ensures the system stays safe at all times with high probability. Our method exploits model knowledge through the use of Control Barrier Functions, and collects measurements from the stream of online data in an event-triggered fashion to guarantee recursive feasibility of the learned safety-critical controller. This, in turn, allows us to provide formal results of forward invariance of a safe set with high probability, even in a priori unexplored regions. Finally, we validate the proposed framework in numerical simulations of an adaptive cruise control system.