 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Short-Term Memory of Visuomotor Policies for Long-Horizon Tasks
Jun 15, 2026Many robotic tasks require short-term memory, whether it's retrieving an object that's no longer visible or turning off an appliance after a set period. Yet, most visuomotor policies trained via imitation learning rely only on immediate sensory input without using past experiences to guide decisions. We present PRISM, a transformer-based architecture for visuomotor policies to effectively use short-term memory via two key components: (i) gated attention, which filters retrieved information to suppress irrelevant details, improving performance by reducing the spurious correlations between the history and current action prediction, (ii) a hierarchical architecture that first compresses local information into compact tokens and then integrates them to capture temporally extended dependencies, improving its compute and memory footprint. Together, these mechanisms enable us to scale short-term memory in visuomotor policies for up to two minutes. To systematically evaluate memory in visuomotor control, we introduce ReMemBench -- a benchmark of eight diverse household manipulation tasks spanning four categories of short-term memory -- designed to foster general memory mechanisms rather than siloed, task-specific solutions. PRISM consistently outperforms prior works, including recurrent architectures, transformers, and their variants -- achieving an absolute improvement of 5%--12% over the strongest baseline. On the RoboCasa and LIBERO benchmarks, it achieves absolute improvements of 11%--15% over its no-memory variant and fine-tuned Vision-Language-Action baselines such as GR00T-N1-3B and OpenVLA, despite not leveraging any large-scale pretraining. Together, PRISM and ReMemBench establish a foundation for developing and evaluating short-term memory-augmented visuomotor policies that scale to long-horizon tasks. Additional materials are available at https://shahrutav.github.io/short-term-memory
NovaPlan: Zero-Shot Long-Horizon Manipulation via Closed-Loop Video Language Planning
Feb 23, 2026Solving long-horizon tasks requires robots to integrate high-level semantic reasoning with low-level physical interaction. While vision-language models (VLMs) and video generation models can decompose tasks and imagine outcomes, they often lack the physical grounding necessary for real-world execution. We introduce NovaPlan, a hierarchical framework that unifies closed-loop VLM and video planning with geometrically grounded robot execution for zero-shot long-horizon manipulation. At the high level, a VLM planner decomposes tasks into sub-goals and monitors robot execution in a closed loop, enabling the system to recover from single-step failures through autonomous re-planning. To compute low-level robot actions, we extract and utilize both task-relevant object keypoints and human hand poses as kinematic priors from the generated videos, and employ a switching mechanism to choose the better one as a reference for robot actions, maintaining stable execution even under heavy occlusion or depth inaccuracy. We demonstrate the effectiveness of NovaPlan on three long-horizon tasks and the Functional Manipulation Benchmark (FMB). Our results show that NovaPlan can perform complex assembly tasks and exhibit dexterous error recovery behaviors without any prior demonstrations or training. Project page: https://nova-plan.github.io/
EMPM: Embodied MPM for Modeling and Simulation of Deformable Objects
Jan 24, 2026Modeling deformable objects - especially continuum materials - in a way that is physically plausible, generalizable, and data-efficient remains challenging across 3D vision, graphics, and robotic manipulation. Many existing methods oversimplify the rich dynamics of deformable objects or require large training sets, which often limits generalization. We introduce embodied MPM (EMPM), a deformable object modeling and simulation framework built on a differentiable Material Point Method (MPM) simulator that captures the dynamics of challenging materials. From multi-view RGB-D videos, our approach reconstructs geometry and appearance, then uses an MPM physics engine to simulate object behavior by minimizing the mismatch between predicted and observed visual data. We further optimize MPM parameters online using sensory feedback, enabling adaptive, robust, and physics-aware object representations that open new possibilities for robotic manipulation of complex deformables. Experiments show that EMPM outperforms spring-mass baseline models. Project website: https://embodied-mpm.github.io.
SAGA: Open-World Mobile Manipulation via Structured Affordance Grounding
Dec 14, 2025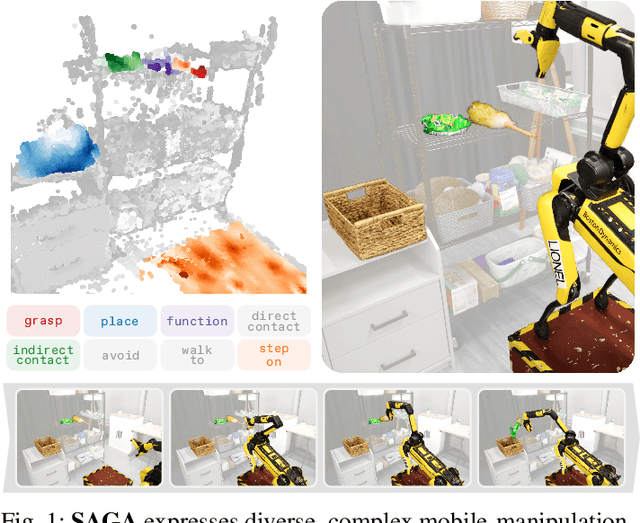
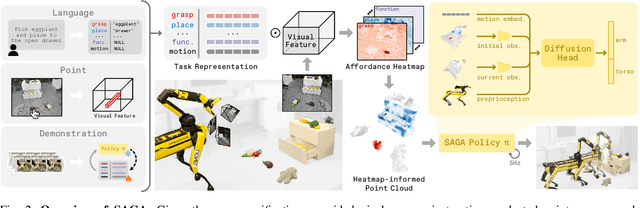
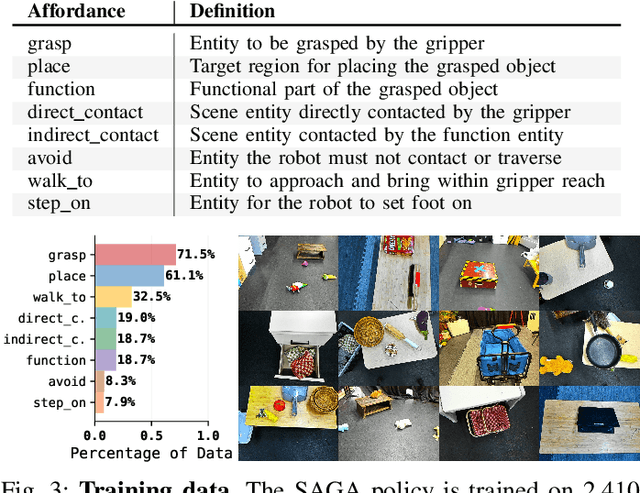
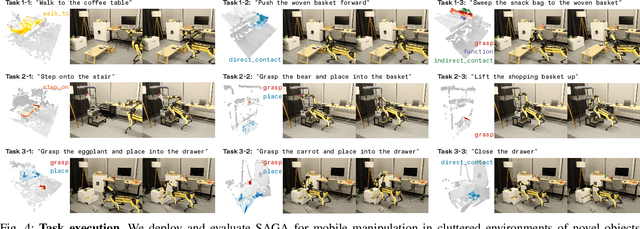
We present SAGA, a versatile and adaptive framework for visuomotor control that can generalize across various environments, task objectives, and user specifications. To efficiently learn such capability, our key idea is to disentangle high-level semantic intent from low-level visuomotor control by explicitly grounding task objectives in the observed environment. Using an affordance-based task representation, we express diverse and complex behaviors in a unified, structured form. By leveraging multimodal foundation models, SAGA grounds the proposed task representation to the robot's visual observation as 3D affordance heatmaps, highlighting task-relevant entities while abstracting away spurious appearance variations that would hinder generalization. These grounded affordances enable us to effectively train a conditional policy on multi-task demonstration data for whole-body control. In a unified framework, SAGA can solve tasks specified in different forms, including language instructions, selected points, and example demonstrations, enabling both zero-shot execution and few-shot adaptation. We instantiate SAGA on a quadrupedal manipulator and conduct extensive experiments across eleven real-world tasks. SAGA consistently outperforms end-to-end and modular baselines by substantial margins. Together, these results demonstrate that structured affordance grounding offers a scalable and effective pathway toward generalist mobile manipulation.
NovaFlow: Zero-Shot Manipulation via Actionable Flow from Generated Videos
Oct 09, 2025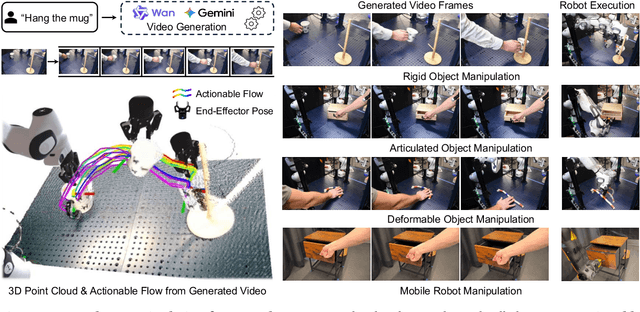
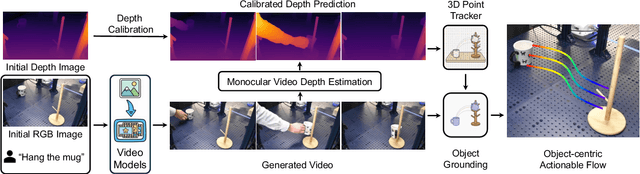


Enabling robots to execute novel manipulation tasks zero-shot is a central goal in robotics. Most existing methods assume in-distribution tasks or rely on fine-tuning with embodiment-matched data, limiting transfer across platforms. We present NovaFlow, an autonomous manipulation framework that converts a task description into an actionable plan for a target robot without any demonstrations. Given a task description, NovaFlow synthesizes a video using a video generation model and distills it into 3D actionable object flow using off-the-shelf perception modules. From the object flow, it computes relative poses for rigid objects and realizes them as robot actions via grasp proposals and trajectory optimization. For deformable objects, this flow serves as a tracking objective for model-based planning with a particle-based dynamics model. By decoupling task understanding from low-level control, NovaFlow naturally transfers across embodiments. We validate on rigid, articulated, and deformable object manipulation tasks using a table-top Franka arm and a Spot quadrupedal mobile robot, and achieve effective zero-shot execution without demonstrations or embodiment-specific training. Project website: https://novaflow.lhy.xyz/.
Versatile Loco-Manipulation through Flexible Interlimb Coordination
Jun 09, 2025The ability to flexibly leverage limbs for loco-manipulation is essential for enabling autonomous robots to operate in unstructured environments. Yet, prior work on loco-manipulation is often constrained to specific tasks or predetermined limb configurations. In this work, we present Reinforcement Learning for Interlimb Coordination (ReLIC), an approach that enables versatile loco-manipulation through flexible interlimb coordination. The key to our approach is an adaptive controller that seamlessly bridges the execution of manipulation motions and the generation of stable gaits based on task demands. Through the interplay between two controller modules, ReLIC dynamically assigns each limb for manipulation or locomotion and robustly coordinates them to achieve the task success. Using efficient reinforcement learning in simulation, ReLIC learns to perform stable gaits in accordance with the manipulation goals in the real world. To solve diverse and complex tasks, we further propose to interface the learned controller with different types of task specifications, including target trajectories, contact points, and natural language instructions. Evaluated on 12 real-world tasks that require diverse and complex coordination patterns, ReLIC demonstrates its versatility and robustness by achieving a success rate of 78.9% on average. Videos and code can be found at https://relic-locoman.github.io/.
Real-is-Sim: Bridging the Sim-to-Real Gap with a Dynamic Digital Twin for Real-World Robot Policy Evaluation
Apr 04, 2025Recent advancements in behavior cloning have enabled robots to perform complex manipulation tasks. However, accurately assessing training performance remains challenging, particularly for real-world applications, as behavior cloning losses often correlate poorly with actual task success. Consequently, researchers resort to success rate metrics derived from costly and time-consuming real-world evaluations, making the identification of optimal policies and detection of overfitting or underfitting impractical. To address these issues, we propose real-is-sim, a novel behavior cloning framework that incorporates a dynamic digital twin (based on Embodied Gaussians) throughout the entire policy development pipeline: data collection, training, and deployment. By continuously aligning the simulated world with the physical world, demonstrations can be collected in the real world with states extracted from the simulator. The simulator enables flexible state representations by rendering image inputs from any viewpoint or extracting low-level state information from objects embodied within the scene. During training, policies can be directly evaluated within the simulator in an offline and highly parallelizable manner. Finally, during deployment, policies are run within the simulator where the real robot directly tracks the simulated robot's joints, effectively decoupling policy execution from real hardware and mitigating traditional domain-transfer challenges. We validate real-is-sim on the PushT manipulation task, demonstrating strong correlation between success rates obtained in the simulator and real-world evaluations. Videos of our system can be found at https://realissim.rai-inst.com.
Imagined Potential Games: A Framework for Simulating, Learning and Evaluating Interactive Behaviors
Nov 06, 2024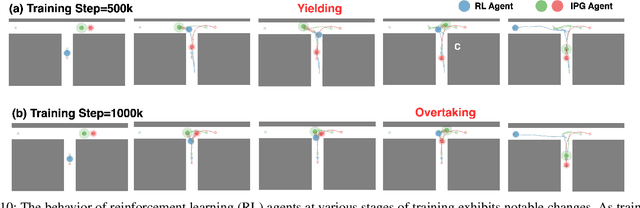


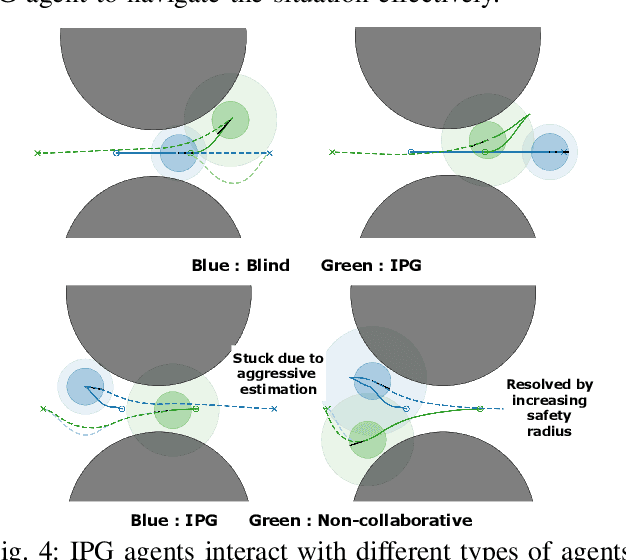
Interacting with human agents in complex scenarios presents a significant challenge for robotic navigation, particularly in environments that necessitate both collision avoidance and collaborative interaction, such as indoor spaces. Unlike static or predictably moving obstacles, human behavior is inherently complex and unpredictable, stemming from dynamic interactions with other agents. Existing simulation tools frequently fail to adequately model such reactive and collaborative behaviors, impeding the development and evaluation of robust social navigation strategies. This paper introduces a novel framework utilizing distributed potential games to simulate human-like interactions in highly interactive scenarios. Within this framework, each agent imagines a virtual cooperative game with others based on its estimation. We demonstrate this formulation can facilitate the generation of diverse and realistic interaction patterns in a configurable manner across various scenarios. Additionally, we have developed a gym-like environment leveraging our interactive agent model to facilitate the learning and evaluation of interactive navigation algorithms.
On-Robot Reinforcement Learning with Goal-Contrastive Rewards
Oct 25, 2024Reinforcement Learning (RL) has the potential to enable robots to learn from their own actions in the real world. Unfortunately, RL can be prohibitively expensive, in terms of on-robot runtime, due to inefficient exploration when learning from a sparse reward signal. Designing dense reward functions is labour-intensive and requires domain expertise. In our work, we propose GCR (Goal-Contrastive Rewards), a dense reward function learning method that can be trained on passive video demonstrations. By using videos without actions, our method is easier to scale, as we can use arbitrary videos. GCR combines two loss functions, an implicit value loss function that models how the reward increases when traversing a successful trajectory, and a goal-contrastive loss that discriminates between successful and failed trajectories. We perform experiments in simulated manipulation environments across RoboMimic and MimicGen tasks, as well as in the real world using a Franka arm and a Spot quadruped. We find that GCR leads to a more-sample efficient RL, enabling model-free RL to solve about twice as many tasks as our baseline reward learning methods. We also demonstrate positive cross-embodiment transfer from videos of people and of other robots performing a task. Appendix: \url{https://tinyurl.com/gcr-appendix-2}.
Optimizing Diffusion Models for Joint Trajectory Prediction and Controllable Generation
Aug 01, 2024



Diffusion models are promising for joint trajectory prediction and controllable generation in autonomous driving, but they face challenges of inefficient inference steps and high computational demands. To tackle these challenges, we introduce Optimal Gaussian Diffusion (OGD) and Estimated Clean Manifold (ECM) Guidance. OGD optimizes the prior distribution for a small diffusion time $T$ and starts the reverse diffusion process from it. ECM directly injects guidance gradients to the estimated clean manifold, eliminating extensive gradient backpropagation throughout the network. Our methodology streamlines the generative process, enabling practical applications with reduced computational overhead. Experimental validation on the large-scale Argoverse 2 dataset demonstrates our approach's superior performance, offering a viable solution for computationally efficient, high-quality joint trajectory prediction and controllable generation for autonomous driving. Our project webpage is at https://yixiaowang7.github.io/OptTrajDiff_Page/.