 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou've Got a Golden Ticket: Improving Generative Robot Policies With A Single Noise Vector
Mar 16, 2026What happens when a pretrained generative robot policy is provided a constant initial noise as input, rather than repeatedly sampling it from a Gaussian? We demonstrate that the performance of a pretrained, frozen diffusion or flow matching policy can be improved with respect to a downstream reward by swapping the sampling of initial noise from the prior distribution (typically isotropic Gaussian) with a well-chosen, constant initial noise input -- a golden ticket. We propose a search method to find golden tickets using Monte-Carlo policy evaluation that keeps the pretrained policy frozen, does not train any new networks, and is applicable to all diffusion/flow matching policies (and therefore many VLAs). Our approach to policy improvement makes no assumptions beyond being able to inject initial noise into the policy and calculate (sparse) task rewards of episode rollouts, making it deployable with no additional infrastructure or models. Our method improves the performance of policies in 38 out of 43 tasks across simulated and real-world robot manipulation benchmarks, with relative improvements in success rate by up to 58% for some simulated tasks, and 60% within 50 search episodes for real-world tasks. We also show unique benefits of golden tickets for multi-task settings: the diversity of behaviors from different tickets naturally defines a Pareto frontier for balancing different objectives (e.g., speed, success rates); in VLAs, we find that a golden ticket optimized for one task can also boost performance in other related tasks. We release a codebase with pretrained policies and golden tickets for simulation benchmarks using VLAs, diffusion policies, and flow matching policies.
On-Robot Reinforcement Learning with Goal-Contrastive Rewards
Oct 25, 2024Reinforcement Learning (RL) has the potential to enable robots to learn from their own actions in the real world. Unfortunately, RL can be prohibitively expensive, in terms of on-robot runtime, due to inefficient exploration when learning from a sparse reward signal. Designing dense reward functions is labour-intensive and requires domain expertise. In our work, we propose GCR (Goal-Contrastive Rewards), a dense reward function learning method that can be trained on passive video demonstrations. By using videos without actions, our method is easier to scale, as we can use arbitrary videos. GCR combines two loss functions, an implicit value loss function that models how the reward increases when traversing a successful trajectory, and a goal-contrastive loss that discriminates between successful and failed trajectories. We perform experiments in simulated manipulation environments across RoboMimic and MimicGen tasks, as well as in the real world using a Franka arm and a Spot quadruped. We find that GCR leads to a more-sample efficient RL, enabling model-free RL to solve about twice as many tasks as our baseline reward learning methods. We also demonstrate positive cross-embodiment transfer from videos of people and of other robots performing a task. Appendix: \url{https://tinyurl.com/gcr-appendix-2}.
ThinkGrasp: A Vision-Language System for Strategic Part Grasping in Clutter
Jul 16, 2024



Robotic grasping in cluttered environments remains a significant challenge due to occlusions and complex object arrangements. We have developed ThinkGrasp, a plug-and-play vision-language grasping system that makes use of GPT-4o's advanced contextual reasoning for heavy clutter environment grasping strategies. ThinkGrasp can effectively identify and generate grasp poses for target objects, even when they are heavily obstructed or nearly invisible, by using goal-oriented language to guide the removal of obstructing objects. This approach progressively uncovers the target object and ultimately grasps it with a few steps and a high success rate. In both simulated and real experiments, ThinkGrasp achieved a high success rate and significantly outperformed state-of-the-art methods in heavily cluttered environments or with diverse unseen objects, demonstrating strong generalization capabilities.
Equivariant Offline Reinforcement Learning
Jun 20, 2024Sample efficiency is critical when applying learning-based methods to robotic manipulation due to the high cost of collecting expert demonstrations and the challenges of on-robot policy learning through online Reinforcement Learning (RL). Offline RL addresses this issue by enabling policy learning from an offline dataset collected using any behavioral policy, regardless of its quality. However, recent advancements in offline RL have predominantly focused on learning from large datasets. Given that many robotic manipulation tasks can be formulated as rotation-symmetric problems, we investigate the use of $SO(2)$-equivariant neural networks for offline RL with a limited number of demonstrations. Our experimental results show that equivariant versions of Conservative Q-Learning (CQL) and Implicit Q-Learning (IQL) outperform their non-equivariant counterparts. We provide empirical evidence demonstrating how equivariance improves offline learning algorithms in the low-data regime.
Imagination Policy: Using Generative Point Cloud Models for Learning Manipulation Policies
Jun 17, 2024


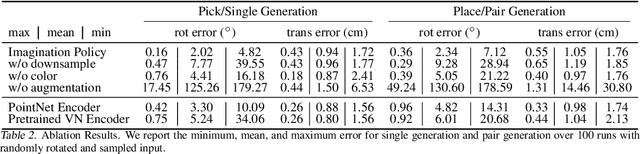
Humans can imagine goal states during planning and perform actions to match those goals. In this work, we propose Imagination Policy, a novel multi-task key-frame policy network for solving high-precision pick and place tasks. Instead of learning actions directly, Imagination Policy generates point clouds to imagine desired states which are then translated to actions using rigid action estimation. This transforms action inference into a local generative task. We leverage pick and place symmetries underlying the tasks in the generation process and achieve extremely high sample efficiency and generalizability to unseen configurations. Finally, we demonstrate state-of-the-art performance across various tasks on the RLbench benchmark compared with several strong baselines.
Equivariant Single View Pose Prediction Via Induced and Restricted Representations
Jul 07, 2023Learning about the three-dimensional world from two-dimensional images is a fundamental problem in computer vision. An ideal neural network architecture for such tasks would leverage the fact that objects can be rotated and translated in three dimensions to make predictions about novel images. However, imposing SO(3)-equivariance on two-dimensional inputs is difficult because the group of three-dimensional rotations does not have a natural action on the two-dimensional plane. Specifically, it is possible that an element of SO(3) will rotate an image out of plane. We show that an algorithm that learns a three-dimensional representation of the world from two dimensional images must satisfy certain geometric consistency properties which we formulate as SO(2)-equivariance constraints. We use the induced and restricted representations of SO(2) on SO(3) to construct and classify architectures which satisfy these geometric consistency constraints. We prove that any architecture which respects said consistency constraints can be realized as an instance of our construction. We show that three previously proposed neural architectures for 3D pose prediction are special cases of our construction. We propose a new algorithm that is a learnable generalization of previously considered methods. We test our architecture on three pose predictions task and achieve SOTA results on both the PASCAL3D+ and SYMSOL pose estimation tasks.
One-shot Imitation Learning via Interaction Warping
Jun 21, 2023
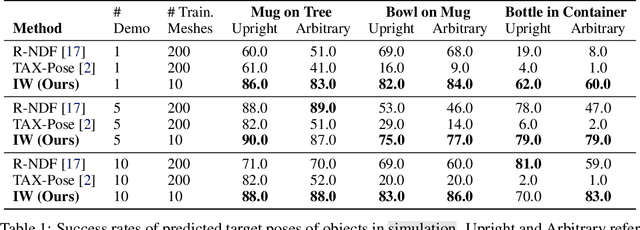


Imitation learning of robot policies from few demonstrations is crucial in open-ended applications. We propose a new method, Interaction Warping, for learning SE(3) robotic manipulation policies from a single demonstration. We infer the 3D mesh of each object in the environment using shape warping, a technique for aligning point clouds across object instances. Then, we represent manipulation actions as keypoints on objects, which can be warped with the shape of the object. We show successful one-shot imitation learning on three simulated and real-world object re-arrangement tasks. We also demonstrate the ability of our method to predict object meshes and robot grasps in the wild.
On Robot Grasp Learning Using Equivariant Models
Jun 10, 2023Real-world grasp detection is challenging due to the stochasticity in grasp dynamics and the noise in hardware. Ideally, the system would adapt to the real world by training directly on physical systems. However, this is generally difficult due to the large amount of training data required by most grasp learning models. In this paper, we note that the planar grasp function is $\SE(2)$-equivariant and demonstrate that this structure can be used to constrain the neural network used during learning. This creates an inductive bias that can significantly improve the sample efficiency of grasp learning and enable end-to-end training from scratch on a physical robot with as few as $600$ grasp attempts. We call this method Symmetric Grasp learning (SymGrasp) and show that it can learn to grasp ``from scratch'' in less that 1.5 hours of physical robot time.
Image to Sphere: Learning Equivariant Features for Efficient Pose Prediction
Feb 27, 2023



Predicting the pose of objects from a single image is an important but difficult computer vision problem. Methods that predict a single point estimate do not predict the pose of objects with symmetries well and cannot represent uncertainty. Alternatively, some works predict a distribution over orientations in $\mathrm{SO}(3)$. However, training such models can be computation- and sample-inefficient. Instead, we propose a novel mapping of features from the image domain to the 3D rotation manifold. Our method then leverages $\mathrm{SO}(3)$ equivariant layers, which are more sample efficient, and outputs a distribution over rotations that can be sampled at arbitrary resolution. We demonstrate the effectiveness of our method at object orientation prediction, and achieve state-of-the-art performance on the popular PASCAL3D+ dataset. Moreover, we show that our method can model complex object symmetries, without any modifications to the parameters or loss function. Code is available at https://dmklee.github.io/image2sphere.
Invariant Slot Attention: Object Discovery with Slot-Centric Reference Frames
Feb 09, 2023



Automatically discovering composable abstractions from raw perceptual data is a long-standing challenge in machine learning. Recent slot-based neural networks that learn about objects in a self-supervised manner have made exciting progress in this direction. However, they typically fall short at adequately capturing spatial symmetries present in the visual world, which leads to sample inefficiency, such as when entangling object appearance and pose. In this paper, we present a simple yet highly effective method for incorporating spatial symmetries via slot-centric reference frames. We incorporate equivariance to per-object pose transformations into the attention and generation mechanism of Slot Attention by translating, scaling, and rotating position encodings. These changes result in little computational overhead, are easy to implement, and can result in large gains in terms of data efficiency and overall improvements to object discovery. We evaluate our method on a wide range of synthetic object discovery benchmarks namely CLEVR, Tetrominoes, CLEVRTex, Objects Room and MultiShapeNet, and show promising improvements on the challenging real-world Waymo Open dataset.