 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-shot Imitation Learning via Interaction Warping
Jun 21, 2023
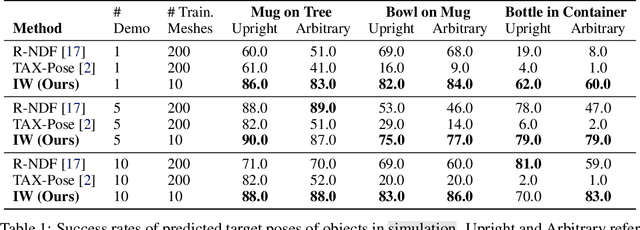


Imitation learning of robot policies from few demonstrations is crucial in open-ended applications. We propose a new method, Interaction Warping, for learning SE(3) robotic manipulation policies from a single demonstration. We infer the 3D mesh of each object in the environment using shape warping, a technique for aligning point clouds across object instances. Then, we represent manipulation actions as keypoints on objects, which can be warped with the shape of the object. We show successful one-shot imitation learning on three simulated and real-world object re-arrangement tasks. We also demonstrate the ability of our method to predict object meshes and robot grasps in the wild.
Stochastic Parallelizable Eigengap Dilation for Large Graph Clustering
Jul 29, 2022

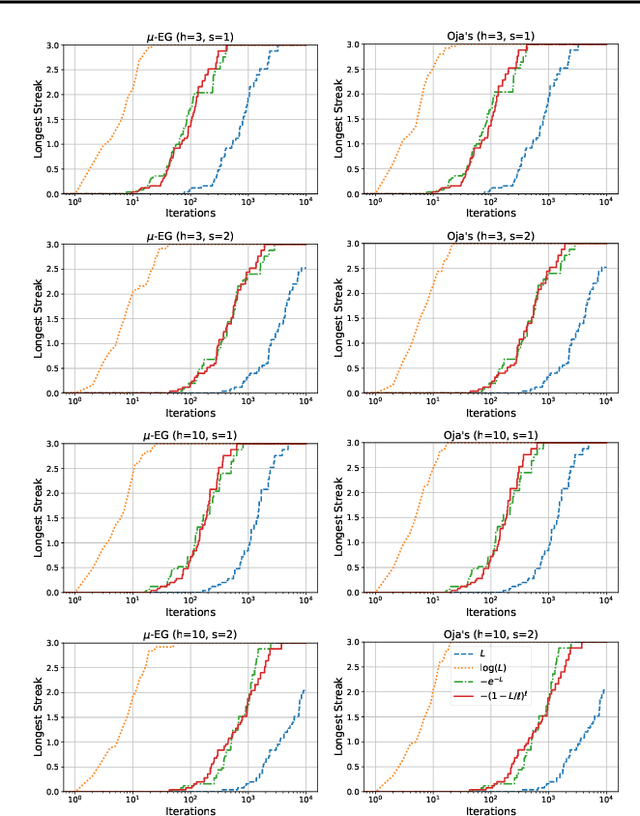
Large graphs commonly appear in social networks, knowledge graphs, recommender systems, life sciences, and decision making problems. Summarizing large graphs by their high level properties is helpful in solving problems in these settings. In spectral clustering, we aim to identify clusters of nodes where most edges fall within clusters and only few edges fall between clusters. This task is important for many downstream applications and exploratory analysis. A core step of spectral clustering is performing an eigendecomposition of the corresponding graph Laplacian matrix (or equivalently, a singular value decomposition, SVD, of the incidence matrix). The convergence of iterative singular value decomposition approaches depends on the eigengaps of the spectrum of the given matrix, i.e., the difference between consecutive eigenvalues. For a graph Laplacian corresponding to a well-clustered graph, the eigenvalues will be non-negative but very small (much less than $1$) slowing convergence. This paper introduces a parallelizable approach to dilating the spectrum in order to accelerate SVD solvers and in turn, spectral clustering. This is accomplished via polynomial approximations to matrix operations that favorably transform the spectrum of a matrix without changing its eigenvectors. Experiments demonstrate that this approach significantly accelerates convergence, and we explain how this transformation can be parallelized and stochastically approximated to scale with available compute.
Maximum Class Separation as Inductive Bias in One Matrix
Jun 17, 2022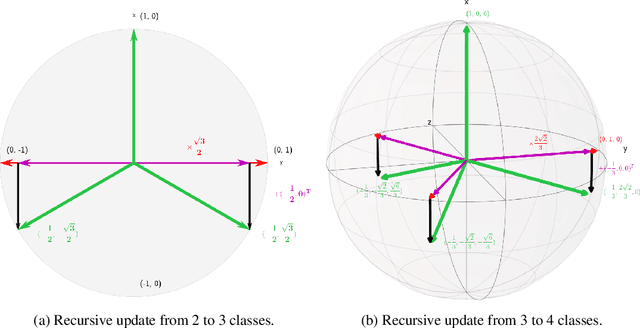
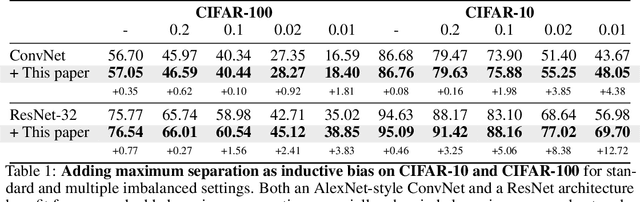
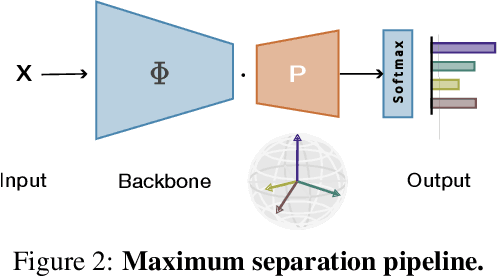
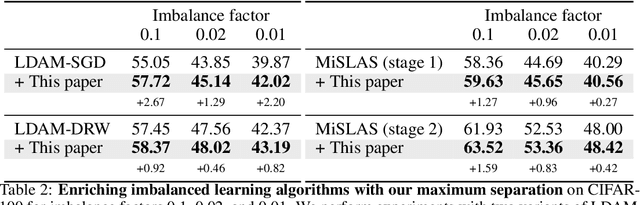
Maximizing the separation between classes constitutes a well-known inductive bias in machine learning and a pillar of many traditional algorithms. By default, deep networks are not equipped with this inductive bias and therefore many alternative solutions have been proposed through differential optimization. Current approaches tend to optimize classification and separation jointly: aligning inputs with class vectors and separating class vectors angularly. This paper proposes a simple alternative: encoding maximum separation as an inductive bias in the network by adding one fixed matrix multiplication before computing the softmax activations. The main observation behind our approach is that separation does not require optimization but can be solved in closed-form prior to training and plugged into a network. We outline a recursive approach to obtain the matrix consisting of maximally separable vectors for any number of classes, which can be added with negligible engineering effort and computational overhead. Despite its simple nature, this one matrix multiplication provides real impact. We show that our proposal directly boosts classification, long-tailed recognition, out-of-distribution detection, and open-set recognition, from CIFAR to ImageNet. We find empirically that maximum separation works best as a fixed bias; making the matrix learnable adds nothing to the performance. The closed-form implementation and code to reproduce the experiments are on github.
Multi-Agent MDP Homomorphic Networks
Oct 09, 2021
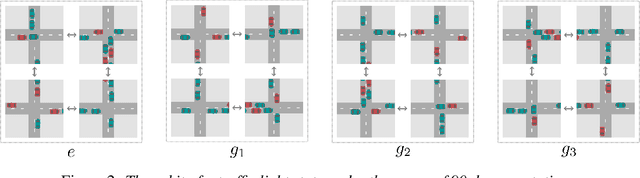
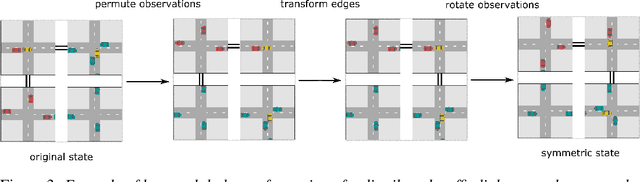
This paper introduces Multi-Agent MDP Homomorphic Networks, a class of networks that allows distributed execution using only local information, yet is able to share experience between global symmetries in the joint state-action space of cooperative multi-agent systems. In cooperative multi-agent systems, complex symmetries arise between different configurations of the agents and their local observations. For example, consider a group of agents navigating: rotating the state globally results in a permutation of the optimal joint policy. Existing work on symmetries in single agent reinforcement learning can only be generalized to the fully centralized setting, because such approaches rely on the global symmetry in the full state-action spaces, and these can result in correspondences across agents. To encode such symmetries while still allowing distributed execution we propose a factorization that decomposes global symmetries into local transformations. Our proposed factorization allows for distributing the computation that enforces global symmetries over local agents and local interactions. We introduce a multi-agent equivariant policy network based on this factorization. We show empirically on symmetric multi-agent problems that distributed execution of globally symmetric policies improves data efficiency compared to non-equivariant baselines.
Geometric and Physical Quantities improve E(3) Equivariant Message Passing
Oct 06, 2021



Including covariant information, such as position, force, velocity or spin is important in many tasks in computational physics and chemistry. We introduce Steerable E(3) Equivariant Graph Neural Networks (SEGNNs) that generalise equivariant graph networks, such that node and edge attributes are not restricted to invariant scalars, but can contain covariant information, such as vectors or tensors. This model, composed of steerable MLPs, is able to incorporate geometric and physical information in both the message and update functions. Through the definition of steerable node attributes, the MLPs provide a new class of activation functions for general use with steerable feature fields. We discuss ours and related work through the lens of equivariant non-linear convolutions, which further allows us to pin-point the successful components of SEGNNs: non-linear message aggregation improves upon classic linear (steerable) point convolutions; steerable messages improve upon recent equivariant graph networks that send invariant messages. We demonstrate the effectiveness of our method on several tasks in computational physics and chemistry and provide extensive ablation studies.
The Impact of Negative Sampling on Contrastive Structured World Models
Jul 24, 2021

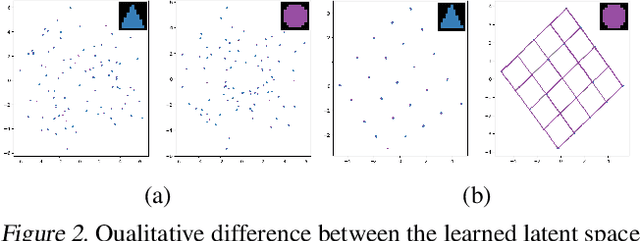
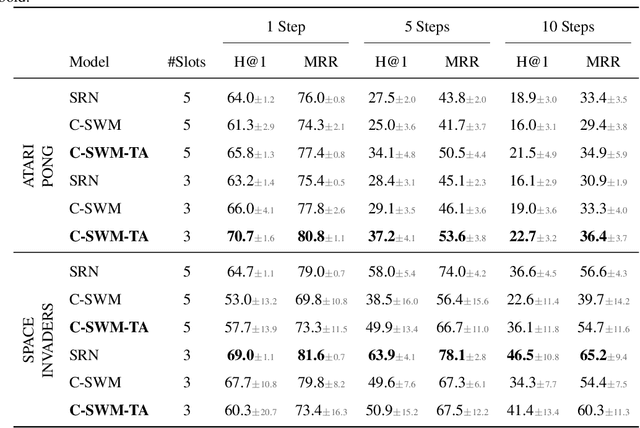
World models trained by contrastive learning are a compelling alternative to autoencoder-based world models, which learn by reconstructing pixel states. In this paper, we describe three cases where small changes in how we sample negative states in the contrastive loss lead to drastic changes in model performance. In previously studied Atari datasets, we show that leveraging time step correlations can double the performance of the Contrastive Structured World Model. We also collect a full version of the datasets to study contrastive learning under a more diverse set of experiences.
MDP Homomorphic Networks: Group Symmetries in Reinforcement Learning
Jun 30, 2020
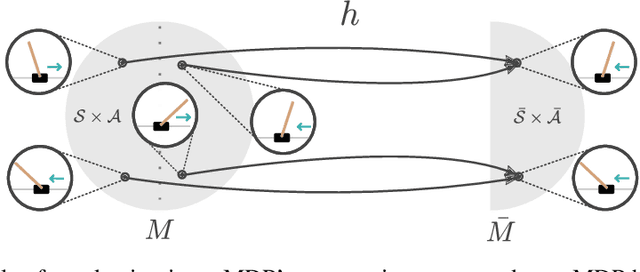
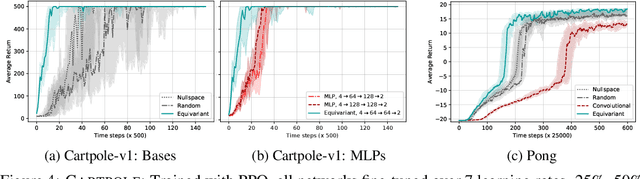
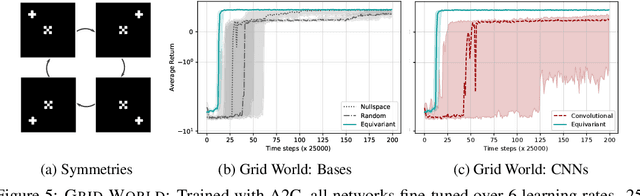
This paper introduces MDP homomorphic networks for deep reinforcement learning. MDP homomorphic networks are neural networks that are equivariant under symmetries in the joint state-action space of an MDP. Current approaches to deep reinforcement learning do not usually exploit knowledge about such structure. By building this prior knowledge into policy and value networks using an equivariance constraint, we can reduce the size of the solution space. We specifically focus on group-structured symmetries (invertible transformations). Additionally, we introduce an easy method for constructing equivariant network layers numerically, so the system designer need not solve the constraints by hand, as is typically done. We construct MDP homomorphic MLPs and CNNs that are equivariant under either a group of reflections or rotations. We show that such networks converge faster than unstructured baselines on CartPole, a grid world and Pong.
Plannable Approximations to MDP Homomorphisms: Equivariance under Actions
Feb 27, 2020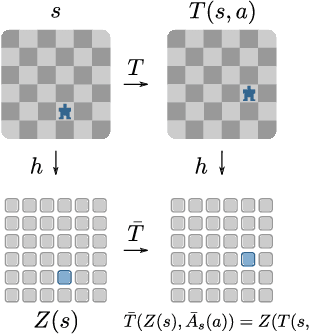
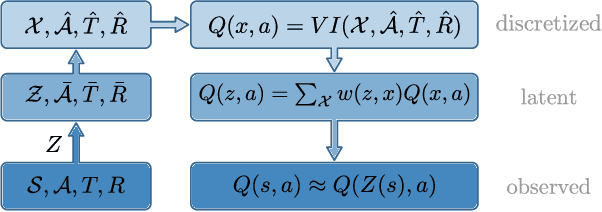

This work exploits action equivariance for representation learning in reinforcement learning. Equivariance under actions states that transitions in the input space are mirrored by equivalent transitions in latent space, while the map and transition functions should also commute. We introduce a contrastive loss function that enforces action equivariance on the learned representations. We prove that when our loss is zero, we have a homomorphism of a deterministic Markov Decision Process (MDP). Learning equivariant maps leads to structured latent spaces, allowing us to build a model on which we plan through value iteration. We show experimentally that for deterministic MDPs, the optimal policy in the abstract MDP can be successfully lifted to the original MDP. Moreover, the approach easily adapts to changes in the goal states. Empirically, we show that in such MDPs, we obtain better representations in fewer epochs compared to representation learning approaches using reconstructions, while generalizing better to new goals than model-free approaches.
Contrastive Learning of Structured World Models
Jan 05, 2020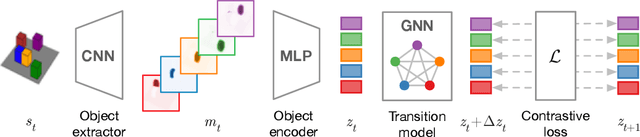
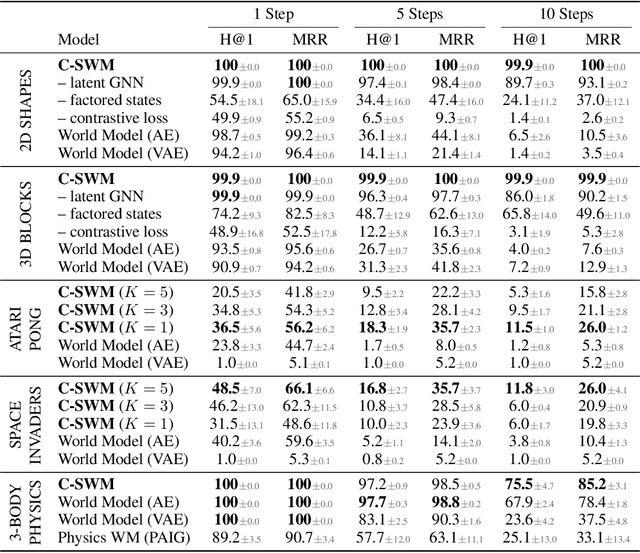
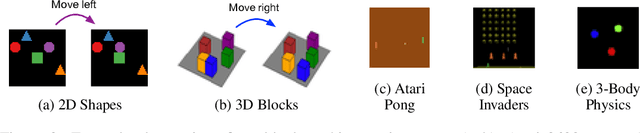

A structured understanding of our world in terms of objects, relations, and hierarchies is an important component of human cognition. Learning such a structured world model from raw sensory data remains a challenge. As a step towards this goal, we introduce Contrastively-trained Structured World Models (C-SWMs). C-SWMs utilize a contrastive approach for representation learning in environments with compositional structure. We structure each state embedding as a set of object representations and their relations, modeled by a graph neural network. This allows objects to be discovered from raw pixel observations without direct supervision as part of the learning process. We evaluate C-SWMs on compositional environments involving multiple interacting objects that can be manipulated independently by an agent, simple Atari games, and a multi-object physics simulation. Our experiments demonstrate that C-SWMs can overcome limitations of models based on pixel reconstruction and outperform typical representatives of this model class in highly structured environments, while learning interpretable object-based representations.
Visual Rationalizations in Deep Reinforcement Learning for Atari Games
Feb 01, 2019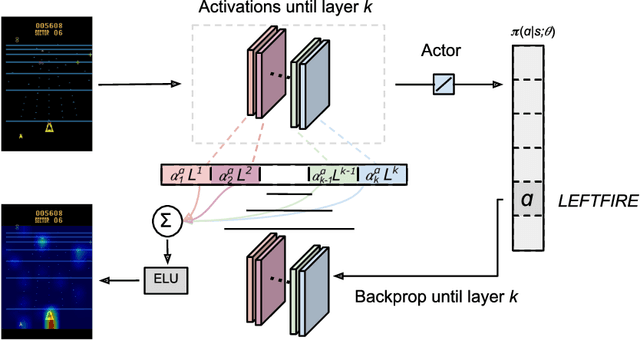

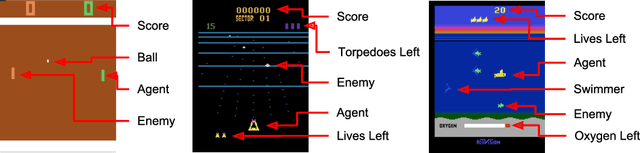

Due to the capability of deep learning to perform well in high dimensional problems, deep reinforcement learning agents perform well in challenging tasks such as Atari 2600 games. However, clearly explaining why a certain action is taken by the agent can be as important as the decision itself. Deep reinforcement learning models, as other deep learning models, tend to be opaque in their decision-making process. In this work, we propose to make deep reinforcement learning more transparent by visualizing the evidence on which the agent bases its decision. In this work, we emphasize the importance of producing a justification for an observed action, which could be applied to a black-box decision agent.