 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Parallelizable Eigengap Dilation for Large Graph Clustering
Paper and Code
Jul 29, 2022

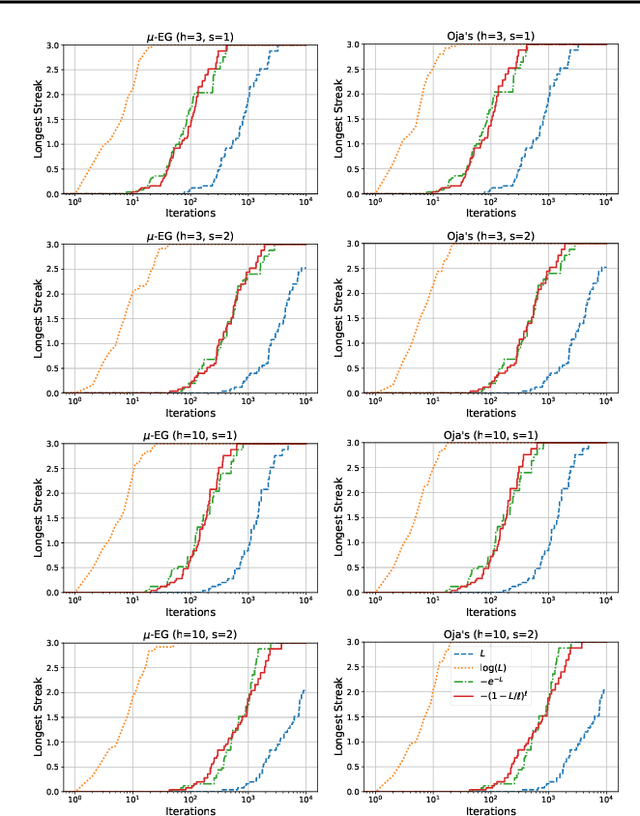
Large graphs commonly appear in social networks, knowledge graphs, recommender systems, life sciences, and decision making problems. Summarizing large graphs by their high level properties is helpful in solving problems in these settings. In spectral clustering, we aim to identify clusters of nodes where most edges fall within clusters and only few edges fall between clusters. This task is important for many downstream applications and exploratory analysis. A core step of spectral clustering is performing an eigendecomposition of the corresponding graph Laplacian matrix (or equivalently, a singular value decomposition, SVD, of the incidence matrix). The convergence of iterative singular value decomposition approaches depends on the eigengaps of the spectrum of the given matrix, i.e., the difference between consecutive eigenvalues. For a graph Laplacian corresponding to a well-clustered graph, the eigenvalues will be non-negative but very small (much less than $1$) slowing convergence. This paper introduces a parallelizable approach to dilating the spectrum in order to accelerate SVD solvers and in turn, spectral clustering. This is accomplished via polynomial approximations to matrix operations that favorably transform the spectrum of a matrix without changing its eigenvectors. Experiments demonstrate that this approach significantly accelerates convergence, and we explain how this transformation can be parallelized and stochastically approximated to scale with available compute.