Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Impact of Negative Sampling on Contrastive Structured World Models
Paper and Code
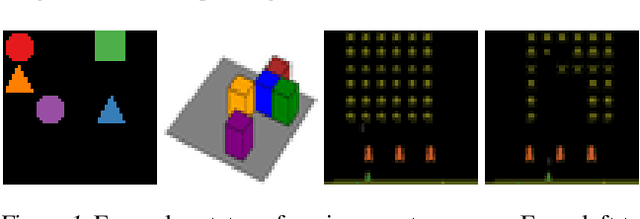

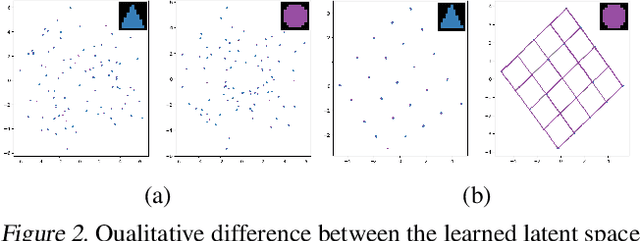
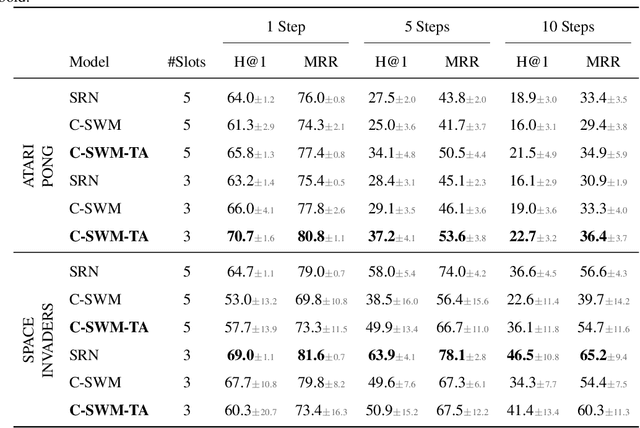
World models trained by contrastive learning are a compelling alternative to autoencoder-based world models, which learn by reconstructing pixel states. In this paper, we describe three cases where small changes in how we sample negative states in the contrastive loss lead to drastic changes in model performance. In previously studied Atari datasets, we show that leveraging time step correlations can double the performance of the Contrastive Structured World Model. We also collect a full version of the datasets to study contrastive learning under a more diverse set of experiences.
* This work appeared at the ICML 2021 Workshop: Self-Supervised
Learning for Reasoning and Perception
View paper on