 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFollow the Mean: Reference-Guided Flow Matching
May 11, 2026Existing approaches to controllable generation typically rely on fine-tuning, auxiliary networks, or test-time search. We show that flow matching admits a different control interface: adaptation through examples. For deterministic interpolants, the velocity field is solely governed by a conditional endpoint mean; shifting this mean shifts the flow itself. This yields a simple principle for controllable generation: steer a pretrained model by changing the reference set it follows. We instantiate this idea in two forms. Reference-Mean Guidance is training-free: it computes a closed-form endpoint-mean correction from a reference bank and applies it to a frozen FLUX.2-klein (4B) model, enabling control of color, identity, style, and structure while keeping the prompt, seed, and weights fixed. Semi-Parametric Guidance amortizes the same idea through an explicit mean anchor and learned residual refiner, matching unconditional DiT-B/4 quality on AFHQv2 while allowing the reference set to be swapped at inference time. These results point to a broader direction: generative models that adapt through data, not parameter updates.
Kernel-Gradient Drifting Models
May 11, 2026We propose kernel-gradient drifting, a one-step generative modeling framework that replaces the fixed Euclidean displacement direction in drifting models with directions induced by the kernel itself. Standard drifting is attractive because it enables fast, high-quality generation without distilling a large pretrained diffusion model, but its theory is currently understood mainly for Gaussian kernels, where the drift coincides with smoothed score matching and is identifiable. Our gradient-based reformulation exposes this score-based structure for general kernels: the resulting drift is the score difference between kernel-smoothed data and model distributions, yielding identifiability for characteristic kernels and a smoothed-KL descent interpretation of the drifting dynamics. Since kernel gradients are intrinsic tangent vectors, the same construction extends naturally to Riemannian manifolds and to discrete data via the Fisher-Rao geometry of the probability simplex. Across spherical geospatial data, promoter DNA and molecule generation, kernel-gradient drifting enables state-of-the-art one-step generation beyond the Euclidean setting without distillation.
Crystalite: A Lightweight Transformer for Efficient Crystal Modeling
Apr 02, 2026Generative models for crystalline materials often rely on equivariant graph neural networks, which capture geometric structure well but are costly to train and slow to sample. We present Crystalite, a lightweight diffusion Transformer for crystal modeling built around two simple inductive biases. The first is Subatomic Tokenization, a compact chemically structured atom representation that replaces high-dimensional one-hot encodings and is better suited to continuous diffusion. The second is the Geometry Enhancement Module (GEM), which injects periodic minimum-image pair geometry directly into attention through additive geometric biases. Together, these components preserve the simplicity and efficiency of a standard Transformer while making it better matched to the structure of crystalline materials. Crystalite achieves state-of-the-art results on crystal structure prediction benchmarks, and de novo generation performance, attaining the best S.U.N. discovery score among the evaluated baselines while sampling substantially faster than geometry-heavy alternatives.
Pawsterior: Variational Flow Matching for Structured Simulation-Based Inference
Feb 14, 2026We introduce Pawsterior, a variational flow-matching framework for improved and extended simulation-based inference (SBI). Many SBI problems involve posteriors constrained by structured domains, such as bounded physical parameters or hybrid discrete-continuous variables, yet standard flow-matching methods typically operate in unconstrained spaces. This mismatch leads to inefficient learning and difficulty respecting physical constraints. Our contributions are twofold. First, generalizing the geometric inductive bias of CatFlow, we formalize endpoint-induced affine geometric confinement, a principle that incorporates domain geometry directly into the inference process via a two-sided variational model. This formulation improves numerical stability during sampling and leads to consistently better posterior fidelity, as demonstrated by improved classifier two-sample test performance across standard SBI benchmarks. Second, and more importantly, our variational parameterization enables SBI tasks involving discrete latent structure (e.g., switching systems) that are fundamentally incompatible with conventional flow-matching approaches. By addressing both geometric constraints and discrete latent structure, Pawsterior extends flow-matching to a broader class of structured SBI problems that were previously inaccessible.
Categorical Flow Maps
Feb 12, 2026We introduce Categorical Flow Maps, a flow-matching method for accelerated few-step generation of categorical data via self-distillation. Building on recent variational formulations of flow matching and the broader trend towards accelerated inference in diffusion and flow-based models, we define a flow map towards the simplex that transports probability mass toward a predicted endpoint, yielding a parametrisation that naturally constrains model predictions. Since our trajectories are continuous rather than discrete, Categorical Flow Maps can be trained with existing distillation techniques, as well as a new objective based on endpoint consistency. This continuous formulation also automatically unlocks test-time inference: we can directly reuse existing guidance and reweighting techniques in the categorical setting to steer sampling toward downstream objectives. Empirically, we achieve state-of-the-art few-step results on images, molecular graphs, and text, with strong performance even in single-step generation.
CORDS: Continuous Representations of Discrete Structures
Jan 29, 2026Many learning problems require predicting sets of objects when the number of objects is not known beforehand. Examples include object detection, molecular modeling, and scientific inference tasks such as astrophysical source detection. Existing methods often rely on padded representations or must explicitly infer the set size, which often poses challenges. We present a novel strategy for addressing this challenge by casting prediction of variable-sized sets as a continuous inference problem. Our approach, CORDS (Continuous Representations of Discrete Structures), provides an invertible mapping that transforms a set of spatial objects into continuous fields: a density field that encodes object locations and count, and a feature field that carries their attributes over the same support. Because the mapping is invertible, models operate entirely in field space while remaining exactly decodable to discrete sets. We evaluate CORDS across molecular generation and regression, object detection, simulation-based inference, and a mathematical task involving recovery of local maxima, demonstrating robust handling of unknown set sizes with competitive accuracy.
Discovering Lie Groups with Flow Matching
Dec 23, 2025Symmetry is fundamental to understanding physical systems, and at the same time, can improve performance and sample efficiency in machine learning. Both pursuits require knowledge of the underlying symmetries in data. To address this, we propose learning symmetries directly from data via flow matching on Lie groups. We formulate symmetry discovery as learning a distribution over a larger hypothesis group, such that the learned distribution matches the symmetries observed in data. Relative to previous works, our method, \lieflow, is more flexible in terms of the types of groups it can discover and requires fewer assumptions. Experiments on 2D and 3D point clouds demonstrate the successful discovery of discrete groups, including reflections by flow matching over the complex domain. We identify a key challenge where the symmetric arrangement of the target modes causes ``last-minute convergence,'' where samples remain stationary until relatively late in the flow, and introduce a novel interpolation scheme for flow matching for symmetry discovery.
Purrception: Variational Flow Matching for Vector-Quantized Image Generation
Oct 01, 2025



We introduce Purrception, a variational flow matching approach for vector-quantized image generation that provides explicit categorical supervision while maintaining continuous transport dynamics. Our method adapts Variational Flow Matching to vector-quantized latents by learning categorical posteriors over codebook indices while computing velocity fields in the continuous embedding space. This combines the geometric awareness of continuous methods with the discrete supervision of categorical approaches, enabling uncertainty quantification over plausible codes and temperature-controlled generation. We evaluate Purrception on ImageNet-1k 256x256 generation. Training converges faster than both continuous flow matching and discrete flow matching baselines while achieving competitive FID scores with state-of-the-art models. This demonstrates that Variational Flow Matching can effectively bridge continuous transport and discrete supervision for improved training efficiency in image generation.
Exponential Family Variational Flow Matching for Tabular Data Generation
Jun 06, 2025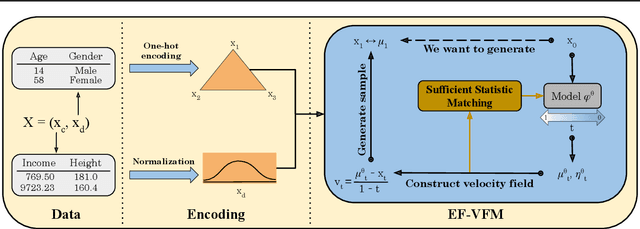



While denoising diffusion and flow matching have driven major advances in generative modeling, their application to tabular data remains limited, despite its ubiquity in real-world applications. To this end, we develop TabbyFlow, a variational Flow Matching (VFM) method for tabular data generation. To apply VFM to data with mixed continuous and discrete features, we introduce Exponential Family Variational Flow Matching (EF-VFM), which represents heterogeneous data types using a general exponential family distribution. We hereby obtain an efficient, data-driven objective based on moment matching, enabling principled learning of probability paths over mixed continuous and discrete variables. We also establish a connection between variational flow matching and generalized flow matching objectives based on Bregman divergences. Evaluation on tabular data benchmarks demonstrates state-of-the-art performance compared to baselines.
Erwin: A Tree-based Hierarchical Transformer for Large-scale Physical Systems
Feb 24, 2025Large-scale physical systems defined on irregular grids pose significant scalability challenges for deep learning methods, especially in the presence of long-range interactions and multi-scale coupling. Traditional approaches that compute all pairwise interactions, such as attention, become computationally prohibitive as they scale quadratically with the number of nodes. We present Erwin, a hierarchical transformer inspired by methods from computational many-body physics, which combines the efficiency of tree-based algorithms with the expressivity of attention mechanisms. Erwin employs ball tree partitioning to organize computation, which enables linear-time attention by processing nodes in parallel within local neighborhoods of fixed size. Through progressive coarsening and refinement of the ball tree structure, complemented by a novel cross-ball interaction mechanism, it captures both fine-grained local details and global features. We demonstrate Erwin's effectiveness across multiple domains, including cosmology, molecular dynamics, and particle fluid dynamics, where it consistently outperforms baseline methods both in accuracy and computational efficiency.