 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVISA: Variational Inference with Sequential Sample-Average Approximations
Mar 15, 2024
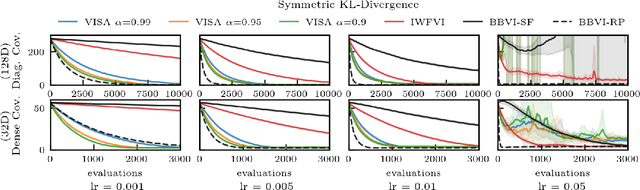
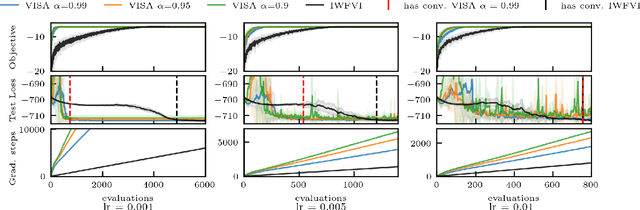
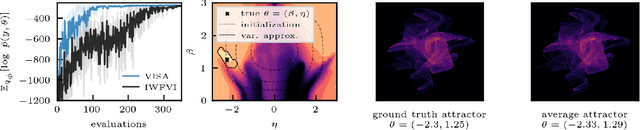
We present variational inference with sequential sample-average approximation (VISA), a method for approximate inference in computationally intensive models, such as those based on numerical simulations. VISA extends importance-weighted forward-KL variational inference by employing a sequence of sample-average approximations, which are considered valid inside a trust region. This makes it possible to reuse model evaluations across multiple gradient steps, thereby reducing computational cost. We perform experiments on high-dimensional Gaussians, Lotka-Volterra dynamics, and a Pickover attractor, which demonstrate that VISA can achieve comparable approximation accuracy to standard importance-weighted forward-KL variational inference with computational savings of a factor two or more for conservatively chosen learning rates.
Topological Obstructions and How to Avoid Them
Dec 12, 2023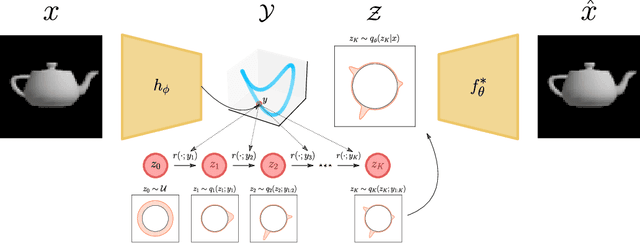
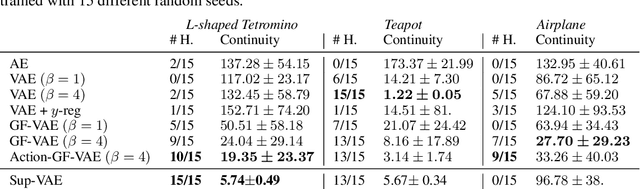


Incorporating geometric inductive biases into models can aid interpretability and generalization, but encoding to a specific geometric structure can be challenging due to the imposed topological constraints. In this paper, we theoretically and empirically characterize obstructions to training encoders with geometric latent spaces. We show that local optima can arise due to singularities (e.g. self-intersection) or due to an incorrect degree or winding number. We then discuss how normalizing flows can potentially circumvent these obstructions by defining multimodal variational distributions. Inspired by this observation, we propose a new flow-based model that maps data points to multimodal distributions over geometric spaces and empirically evaluate our model on 2 domains. We observe improved stability during training and a higher chance of converging to a homeomorphic encoder.
A Variational Perspective on Generative Flow Networks
Oct 14, 2022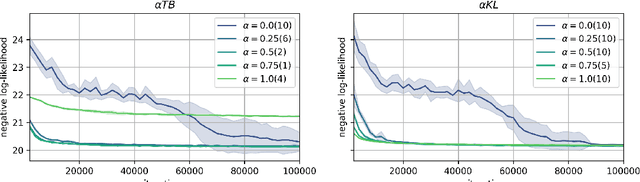
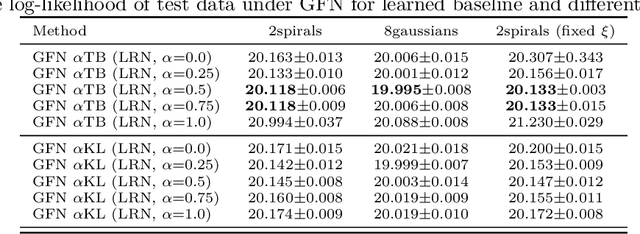
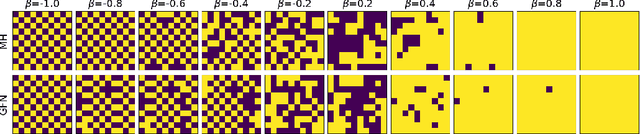

Generative flow networks (GFNs) are a class of models for sequential sampling of composite objects, which approximate a target distribution that is defined in terms of an energy function or a reward. GFNs are typically trained using a flow matching or trajectory balance objective, which matches forward and backward transition models over trajectories. In this work, we define variational objectives for GFNs in terms of the Kullback-Leibler (KL) divergences between the forward and backward distribution. We show that variational inference in GFNs is equivalent to minimizing the trajectory balance objective when sampling trajectories from the forward model. We generalize this approach by optimizing a convex combination of the reverse- and forward KL divergence. This insight suggests variational inference methods can serve as a means to define a more general family of objectives for training generative flow networks, for example by incorporating control variates, which are commonly used in variational inference, to reduce the variance of the gradients of the trajectory balance objective. We evaluate our findings and the performance of the proposed variational objective numerically by comparing it to the trajectory balance objective on two synthetic tasks.
Nested Variational Inference
Jun 21, 2021

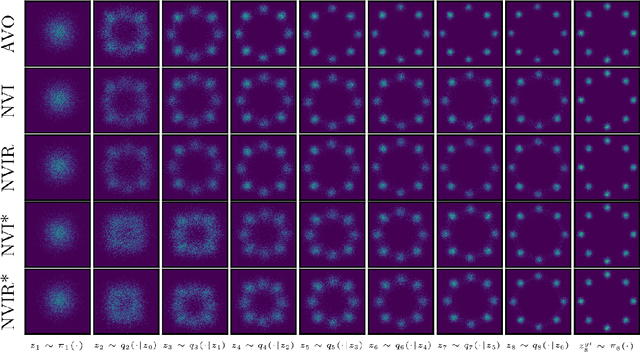

We develop nested variational inference (NVI), a family of methods that learn proposals for nested importance samplers by minimizing an forward or reverse KL divergence at each level of nesting. NVI is applicable to many commonly-used importance sampling strategies and provides a mechanism for learning intermediate densities, which can serve as heuristics to guide the sampler. Our experiments apply NVI to (a) sample from a multimodal distribution using a learned annealing path (b) learn heuristics that approximate the likelihood of future observations in a hidden Markov model and (c) to perform amortized inference in hierarchical deep generative models. We observe that optimizing nested objectives leads to improved sample quality in terms of log average weight and effective sample size.
Learning Proposals for Probabilistic Programs with Inference Combinators
Mar 03, 2021


We develop operators for construction of proposals in probabilistic programs, which we refer to as inference combinators. Inference combinators define a grammar over importance samplers that compose primitive operations such as application of a transition kernel and importance resampling. Proposals in these samplers can be parameterized using neural networks, which in turn can be trained by optimizing variational objectives. The result is a framework for user-programmable variational methods that are correct by construction and can be tailored to specific models. We demonstrate the flexibility of this framework by implementing advanced variational methods based on amortized Gibbs sampling and annealing.
Amortized Population Gibbs Samplers with Neural Sufficient Statistics
Nov 04, 2019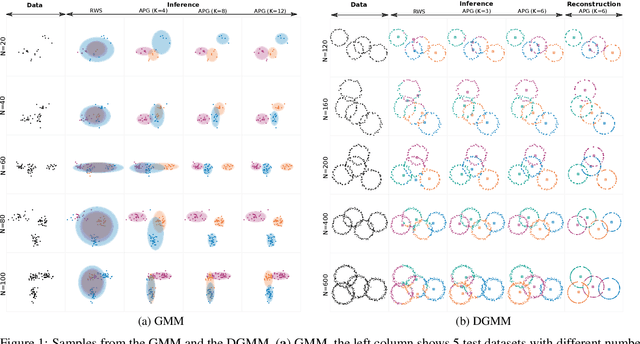
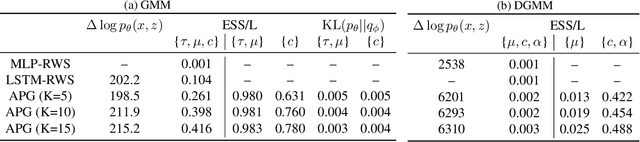

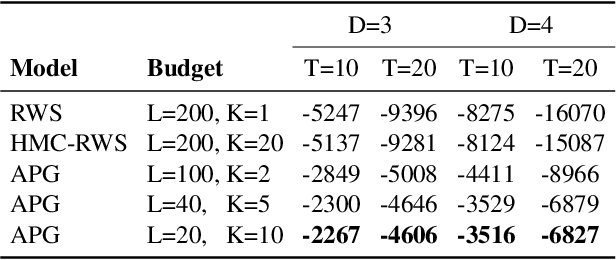
We develop amortized population Gibbs (APG) samplers, a new class of autoencoding variational methods for deep probabilistic models. APG samplers construct high-dimensional proposals by iterating over updates to lower-dimensional blocks of variables. Each conditional update is a neural proposal, which we train by minimizing the inclusive KL divergence relative to the conditional posterior. To appropriately account for the size of the input data, we develop a new parameterization in terms of neural sufficient statistics, resulting in quasi-conjugate variational approximations. Experiments demonstrate that learned proposals converge to the known analytical conditional posterior in conjugate models, and that APG samplers can learn inference networks for highly-structured deep generative models when the conditional posteriors are intractable. Here APG samplers offer a path toward scaling up stochastic variational methods to models in which standard autoencoding architectures fail to produce accurate samples.