 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Tale of Two Temperatures: Simple, Efficient, and Diverse Sampling from Diffusion Language Models
Apr 10, 2026Much work has been done on designing fast and accurate sampling for diffusion language models (dLLMs). However, these efforts have largely focused on the tradeoff between speed and quality of individual samples; how to additionally ensure diversity across samples remains less well understood. In this work, we show that diversity can be increased by using softened, tempered versions of familiar confidence-based remasking heuristics, retaining their computational benefits and offering simple implementations. We motivate this approach by introducing an idealized formal model of fork tokens and studying the impact of remasking on the expected entropy at the forks. Empirically, the proposed tempered heuristics close the exploration gap (pass@k) between existing confidence-based and autoregressive sampling, hence outperforming both when controlling for cost (pass@NFE). We further study how the increase in diversity translates to downstream post-training and test-time compute scaling. Overall, our findings demonstrate that simple, efficient, and diverse sampling from dLLMs is possible.
Maximin Robust Bayesian Experimental Design
Mar 14, 2026We address the brittleness of Bayesian experimental design under model misspecification by formulating the problem as a max--min game between the experimenter and an adversarial nature subject to information-theoretic constraints. We demonstrate that this approach yields a robust objective governed by Sibson's $α$-mutual information~(MI), which identifies the $α$-tilted posterior as the robust belief update and establishes the Rényi divergence as the appropriate measure of conditional information gain. To mitigate the bias and variance of nested Monte Carlo estimators needed to estimate Sibson's $α$-MI, we adopt a PAC-Bayes framework to search over stochastic design policies, yielding rigorous high-probability lower bounds on the robust expected information gain that explicitly control finite-sample error.
Equivariant Neural Diffusion for Molecule Generation
Jun 12, 2025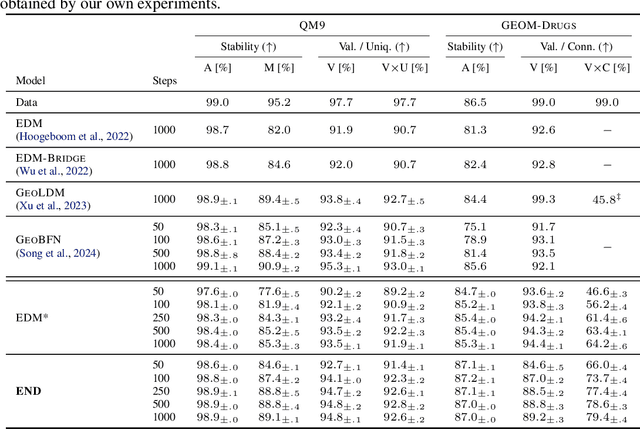
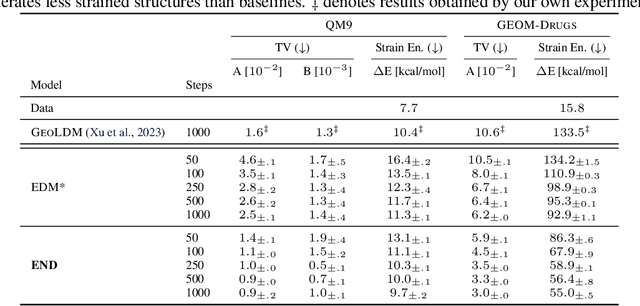
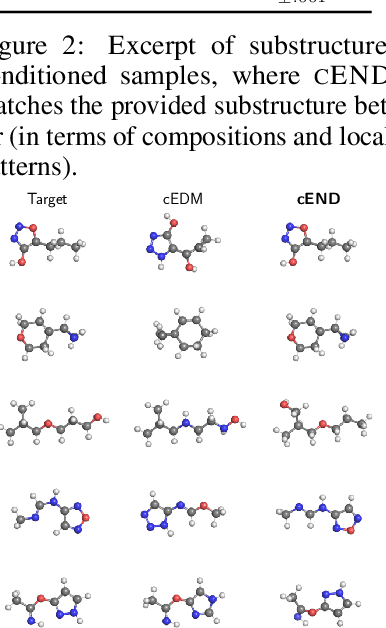
We introduce Equivariant Neural Diffusion (END), a novel diffusion model for molecule generation in 3D that is equivariant to Euclidean transformations. Compared to current state-of-the-art equivariant diffusion models, the key innovation in END lies in its learnable forward process for enhanced generative modelling. Rather than pre-specified, the forward process is parameterized through a time- and data-dependent transformation that is equivariant to rigid transformations. Through a series of experiments on standard molecule generation benchmarks, we demonstrate the competitive performance of END compared to several strong baselines for both unconditional and conditional generation.
SDE Matching: Scalable and Simulation-Free Training of Latent Stochastic Differential Equations
Feb 04, 2025The Latent Stochastic Differential Equation (SDE) is a powerful tool for time series and sequence modeling. However, training Latent SDEs typically relies on adjoint sensitivity methods, which depend on simulation and backpropagation through approximate SDE solutions, which limit scalability. In this work, we propose SDE Matching, a new simulation-free method for training Latent SDEs. Inspired by modern Score- and Flow Matching algorithms for learning generative dynamics, we extend these ideas to the domain of stochastic dynamics for time series and sequence modeling, eliminating the need for costly numerical simulations. Our results demonstrate that SDE Matching achieves performance comparable to adjoint sensitivity methods while drastically reducing computational complexity.
Variational Pseudo Marginal Methods for Jet Reconstruction in Particle Physics
Jun 05, 2024



Reconstructing jets, which provide vital insights into the properties and histories of subatomic particles produced in high-energy collisions, is a main problem in data analyses in collider physics. This intricate task deals with estimating the latent structure of a jet (binary tree) and involves parameters such as particle energy, momentum, and types. While Bayesian methods offer a natural approach for handling uncertainty and leveraging prior knowledge, they face significant challenges due to the super-exponential growth of potential jet topologies as the number of observed particles increases. To address this, we introduce a Combinatorial Sequential Monte Carlo approach for inferring jet latent structures. As a second contribution, we leverage the resulting estimator to develop a variational inference algorithm for parameter learning. Building on this, we introduce a variational family using a pseudo-marginal framework for a fully Bayesian treatment of all variables, unifying the generative model with the inference process. We illustrate our method's effectiveness through experiments using data generated with a collider physics generative model, highlighting superior speed and accuracy across a range of tasks.
Fast yet Safe: Early-Exiting with Risk Control
May 31, 2024



Scaling machine learning models significantly improves their performance. However, such gains come at the cost of inference being slow and resource-intensive. Early-exit neural networks (EENNs) offer a promising solution: they accelerate inference by allowing intermediate layers to exit and produce a prediction early. Yet a fundamental issue with EENNs is how to determine when to exit without severely degrading performance. In other words, when is it 'safe' for an EENN to go 'fast'? To address this issue, we investigate how to adapt frameworks of risk control to EENNs. Risk control offers a distribution-free, post-hoc solution that tunes the EENN's exiting mechanism so that exits only occur when the output is of sufficient quality. We empirically validate our insights on a range of vision and language tasks, demonstrating that risk control can produce substantial computational savings, all the while preserving user-specified performance goals.
Neural Flow Diffusion Models: Learnable Forward Process for Improved Diffusion Modelling
Apr 19, 2024Conventional diffusion models typically relies on a fixed forward process, which implicitly defines complex marginal distributions over latent variables. This can often complicate the reverse process' task in learning generative trajectories, and results in costly inference for diffusion models. To address these limitations, we introduce Neural Flow Diffusion Models (NFDM), a novel framework that enhances diffusion models by supporting a broader range of forward processes beyond the fixed linear Gaussian. We also propose a novel parameterization technique for learning the forward process. Our framework provides an end-to-end, simulation-free optimization objective, effectively minimizing a variational upper bound on the negative log-likelihood. Experimental results demonstrate NFDM's strong performance, evidenced by state-of-the-art likelihood estimation. Furthermore, we investigate NFDM's capacity for learning generative dynamics with specific characteristics, such as deterministic straight lines trajectories. This exploration underscores NFDM's versatility and its potential for a wide range of applications.
VISA: Variational Inference with Sequential Sample-Average Approximations
Mar 15, 2024
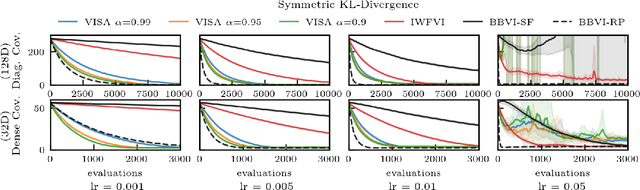
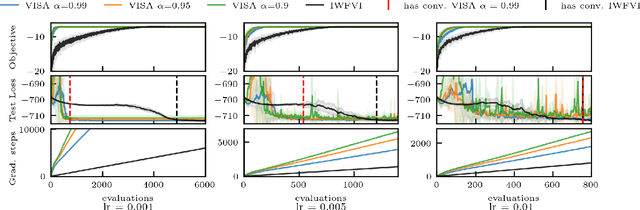
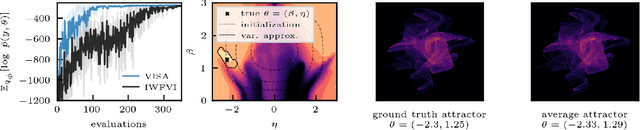
We present variational inference with sequential sample-average approximation (VISA), a method for approximate inference in computationally intensive models, such as those based on numerical simulations. VISA extends importance-weighted forward-KL variational inference by employing a sequence of sample-average approximations, which are considered valid inside a trust region. This makes it possible to reuse model evaluations across multiple gradient steps, thereby reducing computational cost. We perform experiments on high-dimensional Gaussians, Lotka-Volterra dynamics, and a Pickover attractor, which demonstrate that VISA can achieve comparable approximation accuracy to standard importance-weighted forward-KL variational inference with computational savings of a factor two or more for conservatively chosen learning rates.
Neural Diffusion Models
Oct 12, 2023



Diffusion models have shown remarkable performance on many generative tasks. Despite recent success, most diffusion models are restricted in that they only allow linear transformation of the data distribution. In contrast, broader family of transformations can potentially help train generative distributions more efficiently, simplifying the reverse process and closing the gap between the true negative log-likelihood and the variational approximation. In this paper, we present Neural Diffusion Models (NDMs), a generalization of conventional diffusion models that enables defining and learning time-dependent non-linear transformations of data. We show how to optimise NDMs using a variational bound in a simulation-free setting. Moreover, we derive a time-continuous formulation of NDMs, which allows fast and reliable inference using off-the-shelf numerical ODE and SDE solvers. Finally, we demonstrate the utility of NDMs with learnable transformations through experiments on standard image generation benchmarks, including CIFAR-10, downsampled versions of ImageNet and CelebA-HQ. NDMs outperform conventional diffusion models in terms of likelihood and produce high-quality samples.
Practical and Asymptotically Exact Conditional Sampling in Diffusion Models
Jun 30, 2023Diffusion models have been successful on a range of conditional generation tasks including molecular design and text-to-image generation. However, these achievements have primarily depended on task-specific conditional training or error-prone heuristic approximations. Ideally, a conditional generation method should provide exact samples for a broad range of conditional distributions without requiring task-specific training. To this end, we introduce the Twisted Diffusion Sampler, or TDS. TDS is a sequential Monte Carlo (SMC) algorithm that targets the conditional distributions of diffusion models. The main idea is to use twisting, an SMC technique that enjoys good computational efficiency, to incorporate heuristic approximations without compromising asymptotic exactness. We first find in simulation and on MNIST image inpainting and class-conditional generation tasks that TDS provides a computational statistical trade-off, yielding more accurate approximations with many particles but with empirical improvements over heuristics with as few as two particles. We then turn to motif-scaffolding, a core task in protein design, using a TDS extension to Riemannian diffusion models. On benchmark test cases, TDS allows flexible conditioning criteria and often outperforms the state of the art.